Memory leak with DqnAgent #569
Comments
|
@romandunets this is a bit hard to debug because it sounds like it takes a while for the issue to appear. To see if this is caused by something in eager mode, try this: run = tf.function(driver.run, autograph=False)
while True:
run()that should run the same graph over and over, bypassing eager mode computation for the most part. let us know if that fixes the leak and if so, we can let TF team know about this. |
|
@ebrevdo Thanks for response! Actually, the issue is visible just after first 30 seconds of running the script I provided above. Here is the memory usage of that one after running collection loop for the first 100000 iterations: Wrapping Taking one step further and introducing (replacing collection with) Memory usage steadily increases along the time: Wrapping |

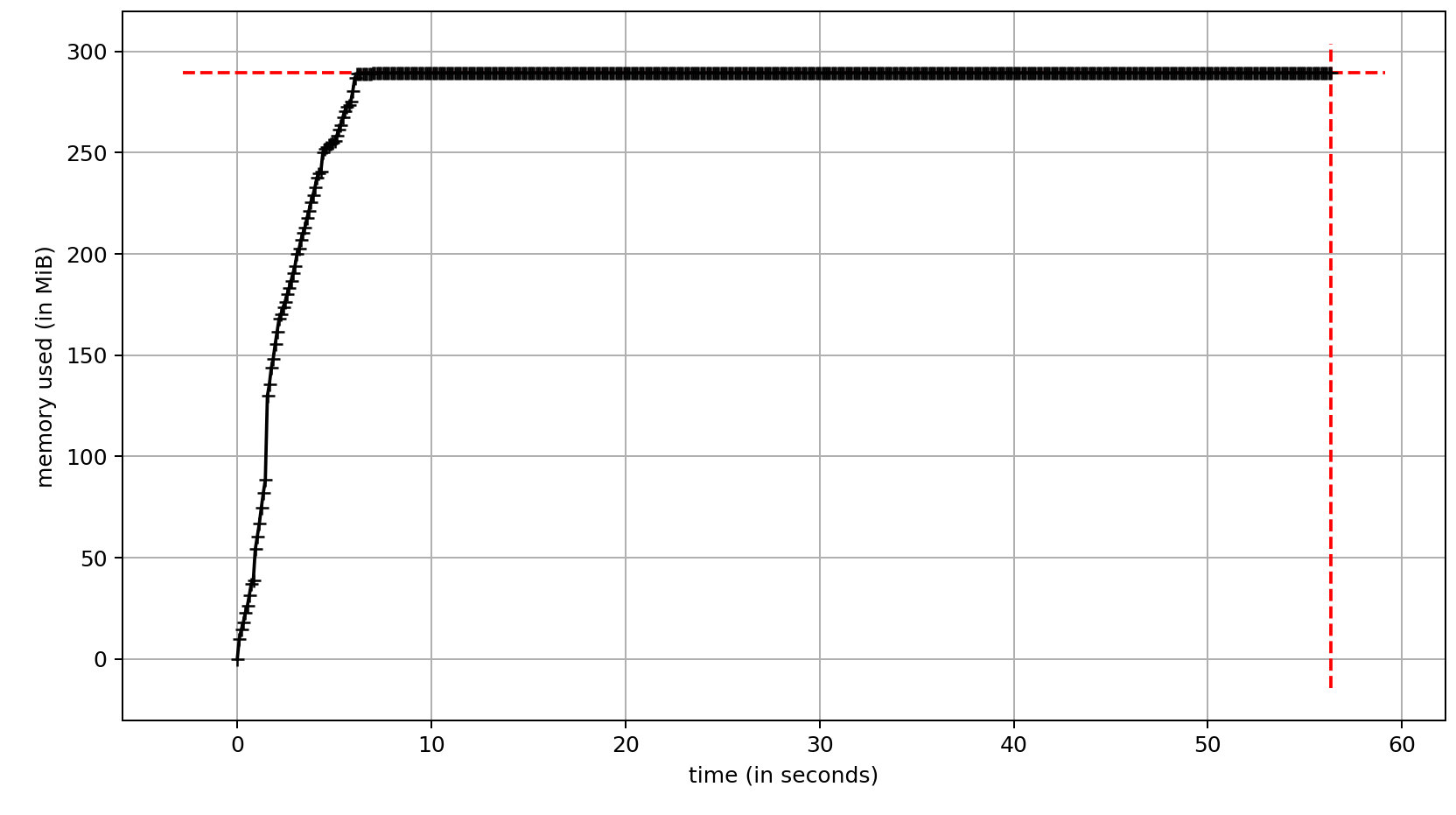
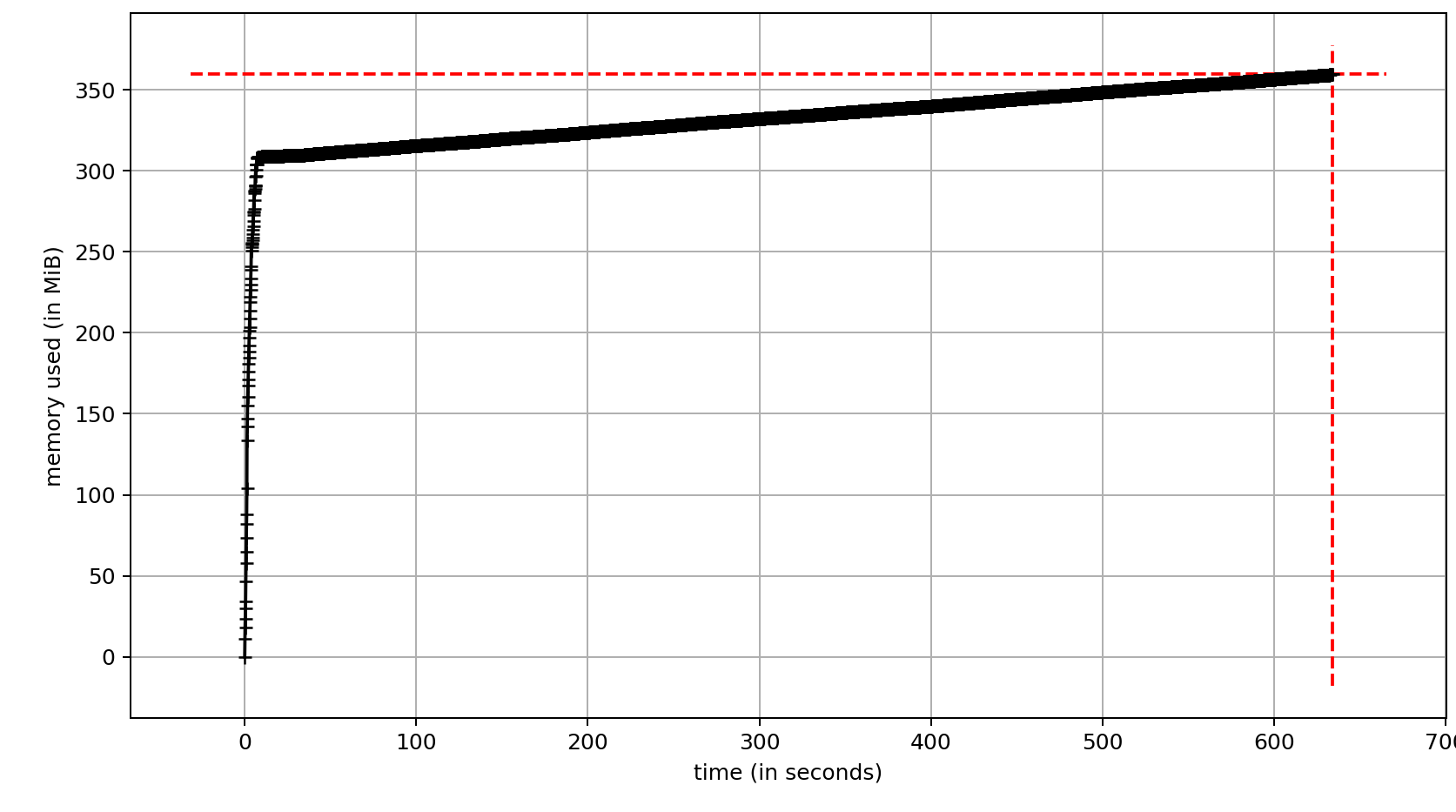
|
I don't think this is an issue with the |
|
Thanks for the update. Looks like we should increase the priority of this issue. |
|
BTW we've been moving to Actor/Learner which takes care of a lot of this for you. There's a DQN example here. Additionally it uses Reverb replay buffer, which is a preferred way to pass data between collection & training. Can you try using that and seeing if the memory leak disappears? |
|
I've been trying to figure out a very similar problem, and the code I'm running is basically the same as above. I've noticed that the issue doesn't seem to happen when I call agent.train as a Python function instead of wrapping it in a tf.function. It loses some speed, but not quite as much as using pure Python everything. |
|
@ebrevdo I used the exact script you referenced for memory profiling and realized that it demonstrates same memory leakage issues as the original script I used: |
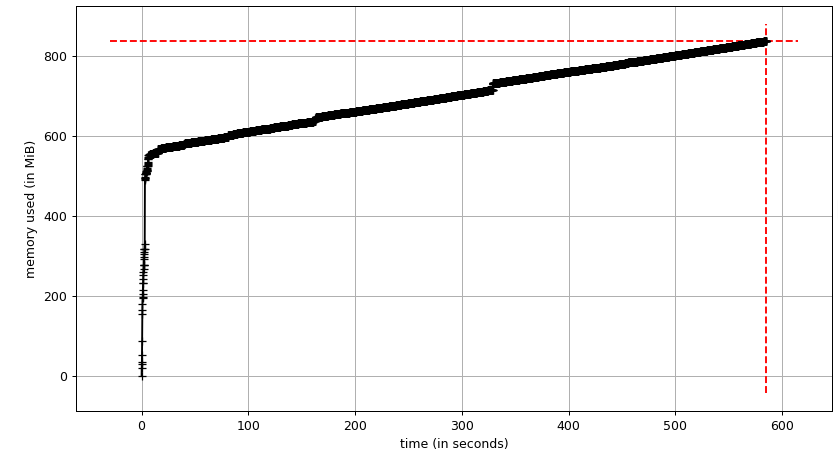
Unfortunately, both wrapped and unwrapped |
|
Using Tracing this to my tf-nightly package these are the lines this is a setter of class and in the property If I add a print command to setter Here's the backtrace for when this happens: Looks like @jaingaurav do you know this codepath? who should take a look to help debug this memory leak? |
|
Investigating the backtrace, it doesn't look like thread_local_data is being recreated each time; it just seems like |
|
Is this being called from a new thread each time? As far as I know there's no eviction for thread_local data when the thread goes away. For debugging on the TF side please file a tensorflow/tensorflow bug. |
|
No; this is definitely all from the same thread. I'll file a bug. |
|
Filed tensorflow/tensorflow#48888. |
|
Moving the conversation to that bug. |
…ady set. This speeds up dqn_train_eval from ~470 steps/sec to ~500 steps/sec, giving a 6% performance boost. Fixes #569; though other changes by TF team address the actual memory leak (see tensorflow/tensorflow#48888). PiperOrigin-RevId: 374511986 Change-Id: I378ff6760e1ec620441b75d6c627929df3fdc335
I have built basic DQN agent to play within CartPole environment by following the DQN tutorial: https://www.tensorflow.org/agents/tutorials/1_dqn_tutorial However, after couple of training hours I noticed that process is increasing memory consumption substantially. I was able to simplify the training script in order to narrow down the problem and figured out that memory leaks whenever driver is using
agent.policyoragent.collect_policy(replacing that one withRandomTFPolicyeliminates the issue):Other hotfix as mentioned in the code above is to call
gc.collect()after eachdriver.run()but that has huge impact on the performance.This memory leak prevents long-running training process which might be a bit of bummer for more complex environments based on DQN.
Running setup:
Same script has been also run within Docker container and confirmed memory leak.
What could be possible cause for this problem and how to properly fix it?
The text was updated successfully, but these errors were encountered: