Prototype the custom-scalars plugin. #664
Conversation
a0b1b99
to
dca1a06
Compare
|
I like this so far. Here's some feedback. Maybe have this: category {
title: "mean biases"
regex: "^mean/layer\\d+/biases$"
}Be this instead: category {
title: "mean biases"
chart: {
name: "Mean Layer Biases"
tag: "mean/layer\\d+/biases"
}
}
On the UI front, I like the idea of not having the search box and match list be there by default. The matching tag names can be viewed in the hover box. But I like the customizability. Maybe a click dialog or a sliding drawer? |
|
Also super helpful instructions in the plugin inactive page, that show example proto files (in addition to Python API examples) would really help users bootstrap themselves with this feature. In that sense, I think you were correct that there are advantages to this being its own plugin. |
There was a problem hiding this comment.
I'd like to see the config placed in a way that we could imagine generalizing to many plugins. If we had 10 plugins, all dumping their random config files into the logdir, it will be a mess. So I think we should standardize on something like:
dir/plugins/custom_scalars/foo.pbtxt
Also, I think the plugin asset should be handled by framework code that interfaces thru the SummaryWriter, rather than directly writing files. This will improve consistency across plugins, and interoperability for when we are writing data that isn't going to a local directory on disk, but to a distributed backend / tensorbase / what have you.
Plugin Asset Util may be relevant.
Also: What should the behavior be if we have
RunA defines LayoutA in ./runs/A
RunB defines LayoutB in ./runs/B
User decides to look at both runs by pointing to ./runs
| // Downsample the data. Otherwise, too many markers clutter the chart. | ||
| const skipLength = Math.ceil(originalData.length / _MAX_MARKERS); | ||
| const data = new Array(Math.floor(originalData.length / skipLength)); | ||
| let indexIntoOriginal = 0; |
There was a problem hiding this comment.
indexIntoOriginal is unused
| for (let i = 0, j = 0; i < data.length; i++, j += skipLength) { | ||
| data[i] = originalData[j]; | ||
| } | ||
| return new Plottable.Dataset(data, {name: original.metadata().name}); |
There was a problem hiding this comment.
Why not copy or reuse the whole metadata object?
| """ | ||
| self._logdir = context.logdir | ||
| self._multiplexer = context.multiplexer | ||
| self._scalars_plugin = scalars_plugin.ScalarsPlugin(context) |
There was a problem hiding this comment.
Note: we're counting on instantiating a scalars plugin not to have side effects. i think we can make this assumption, since the plugin will re-use the multiplexer and plugins don't do anything directly if you don't request their WSGI apps.
There was a problem hiding this comment.
Hm, but the custom scalars plugin itself does have a side effect (starting a config file checking thread) as soon as it's constructed. Maybe it would be worth formalizing a little when one plugin depends on another, e.g. by refactoring the scalars plugin to have a data-loading class without any of the WSGI stuff that is what other plugins should depend on directly?
There was a problem hiding this comment.
Just a note: the distributions plugin similarly instantiates a histograms plugin. At the time, @dandelionmane and I agreed that this was a Good Thing because they depend on the same data source and this code makes the data dependency especially explicit.
| layout.CONFIG_FILE, e) | ||
|
|
||
| # Wait a while before checking again. | ||
| time.sleep(_CONFIG_FILE_CHECK_THROTTLE) |
There was a problem hiding this comment.
I think this method is misleadingly named. It is called "periodically_check" but it doesn't implement the periodic check - really it is "check then delay".
I think the time.sleep should be factored to live with (or include) the while True: loop for checking the file. The try/except error handling and logging can be moved into check_for_config_file.
|
|
||
| layout_proto = scalars_layout_pb2.Layout() | ||
| text_format.Parse(pbtxt_contents, layout_proto) | ||
| self._layout = json_format.MessageToJson( |
There was a problem hiding this comment.
I think while in Python-land it should be stored as a proto, not JSON. Early conversion to JSON just loses inspectability/safety, no?
Then, you can convert to JSON in the handler when it is actually being sent to the frontend.
It gives a straightforward mapping between data storage type and location:
fronted = json
backend = proto
There was a problem hiding this comment.
Done. That general rule sounds great, albeit we do incur a little latency from serialization at response time.
|
|
||
| CONFIG_FILE = 'custom_scalars_config.pbtxt' | ||
|
|
||
| def set_layout(logdir, scalars_layout): |
There was a problem hiding this comment.
Better to pass some SummaryWriter-esque object rather than a logdir, since the SummaryWriter is the canonical point by which the summary data is exported.
Reasons:
- One often keeps access to a SummaryWriter when writing code that deals with summaries, but the logdir might be in some outer scope
- In the future, we may switch to e.g a DatabseWriter or RemoteServerWriter and in these cases there isn't meaningfully a "logdir". It would be better to implement a consistent interface across all our writers that can handle this, rather than privilging the logdir concept.
There was a problem hiding this comment.
I see what you mean ... I'm grappling with how file writer pertains to a run. A config for a run is meaningless: We only have 1 config for the dashboard. Maybe we accept a logdir for now (and pass it into plugin_asset_util.PluginDirectory()? And then we do away with the concept of logdir when say we save the config in SQL?
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
| # ============================================================================== | ||
| """Integration tests for the pr_curves plugin.""" |
There was a problem hiding this comment.
s/pr_curves/custom_scalars/
| """ | ||
| self._logdir = context.logdir | ||
| self._multiplexer = context.multiplexer | ||
| self._scalars_plugin = scalars_plugin.ScalarsPlugin(context) |
There was a problem hiding this comment.
Hm, but the custom scalars plugin itself does have a side effect (starting a config file checking thread) as soon as it's constructed. Maybe it would be worth formalizing a little when one plugin depends on another, e.g. by refactoring the scalars plugin to have a data-loading class without any of the WSGI stuff that is what other plugins should depend on directly?
|
|
||
| # Start a separate thread that periodically checks for the config file | ||
| # specifying layout. | ||
| threading.Thread(target=self._periodically_check_for_config_file).start() |
There was a problem hiding this comment.
Can you give the thread a name? Makes it easier to follow in the python logs when debugging. E.g. "CustomScalarsConfigThread" or something.
There was a problem hiding this comment.
Done. That does make logs for the thread easier to follow!
|
This looks like a great new feature. I just wanted to echo Dandelion's question about whether/how this feature would make it possible to compare line charts from two different models (i.e. RunA defines LayoutA in ./runs/A, RunB defines LayoutB in ./runs/B). I'm interested in comparing multiple models that may have slightly different graphs (e.g. model A is the baseline, model B has some added layer or new component). Beyond that, the models might actually have several runs each (I'm thinking several workers in A3C), so ideally I'd love to get a mean and confidence interval around all the runs for model A and plot that against the mean and CI for model B. I definitely agree with @georgedahl's comment in #597; I'm also currently pulling out all the data from the tf.events and plotting it myself in a notebook, in order to generate something like this: |
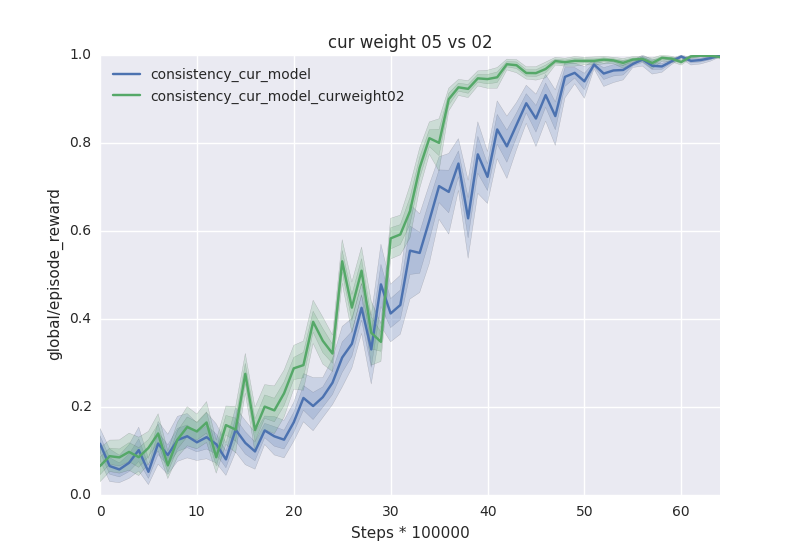
|
Happy to see that you're working on this! Just wanted to let you know that I’ve seen this and have read (and will continue to follow) the discussion, but I don’t have the bandwidth to do a 1640-line code review right now. If there are future, smaller PRs that you’d like me to look at—or anything specific in this PR—please feel free to re-add me. I generally agree with comments so far (especially defaulting to the |
There was a problem hiding this comment.
@jart, wonderful ideas! I incorporated the changes. Let me know what you think.
The one change I did not incorporate yet is a helpful "no data" message. I plan to add that once we settle on the API for writing/reading the config file.
- I made each
Categorycontain severalCharts. EachChartcontains severaltags (or really regexes for tags). - We match whole strings by default.
- The list of matches is now collapsible.
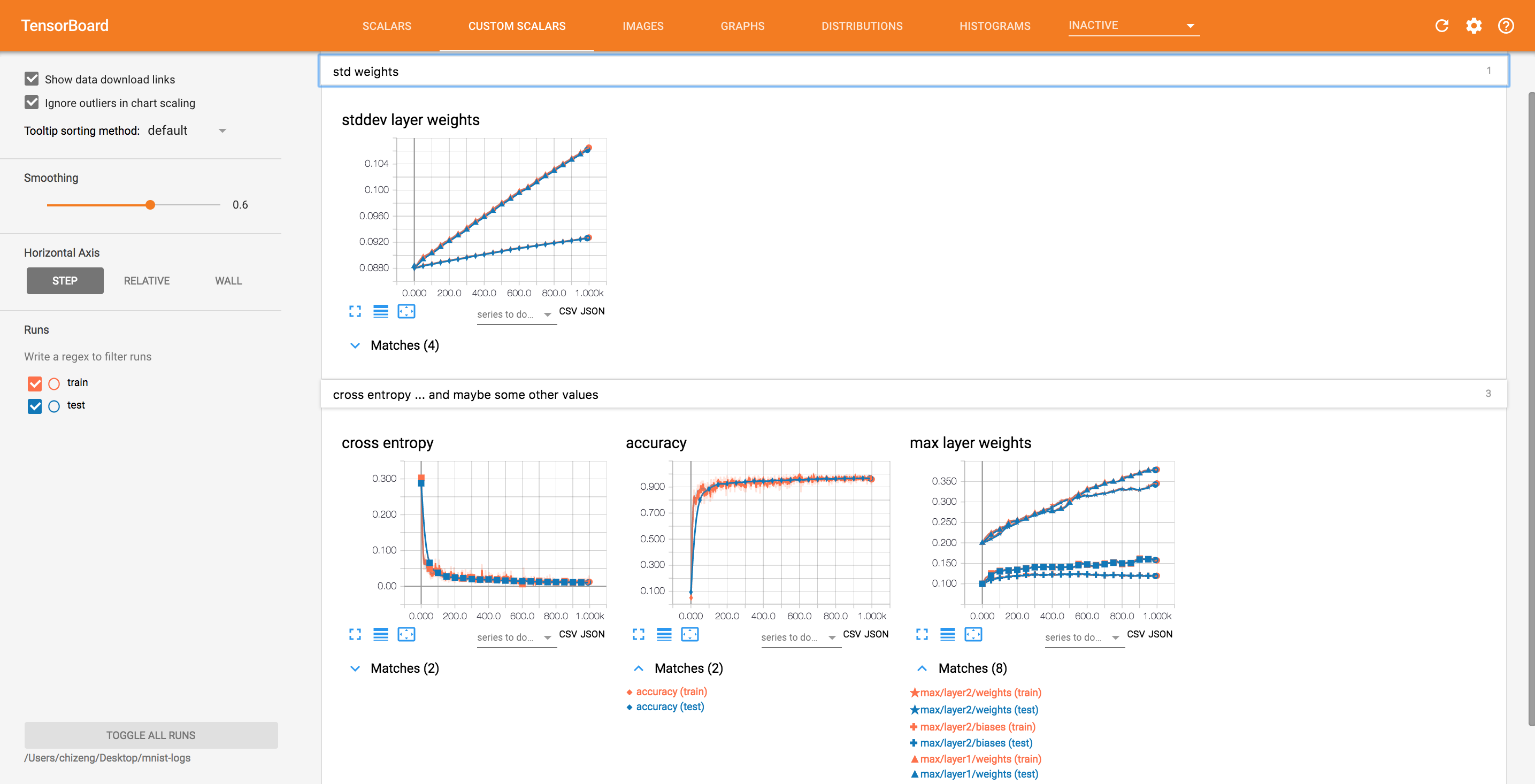
@dandelionmane, I addressed some of your detailed comments, but I want to discuss the system for loading plugin-specific files.
I think we can use the PluginDirectory method here:
https://github.com/tensorflow/tensorboard/blob/master/tensorboard/backend/event_processing/plugin_asset_util.py
Specifically, we can have plugins call that method and then be responsible for writing data into it.
This would involve preserving the concept of logdir though, which I think might be necessary for now: The config file is only relevant for the top-level log directory (which concerns your other question), while each file writer pertains to a run (I think per-run config files should be ignored ... what would a per-run config file mean?).
@natashamjaques, after this plugin goes in, each run for each model should manifest as a distinct run in TensorBoard if you start TensorBoard at the top-level logdir. TensorBoard recursively finds runs within the logdir - you'll be able to explicitly select those runs and they should show within the same custom scalars plot.
Regarding confidence intervals, we would actually need to build a separate plugin since the scalars summary format is rigid. I am currently adding frontend logic to support visualizing confidence intervals though. See this separate effort:
#608 (comment)
| // Downsample the data. Otherwise, too many markers clutter the chart. | ||
| const skipLength = Math.ceil(originalData.length / _MAX_MARKERS); | ||
| const data = new Array(Math.floor(originalData.length / skipLength)); | ||
| let indexIntoOriginal = 0; |
| for (let i = 0, j = 0; i < data.length; i++, j += skipLength) { | ||
| data[i] = originalData[j]; | ||
| } | ||
| return new Plottable.Dataset(data, {name: original.metadata().name}); |
|
|
||
| # Start a separate thread that periodically checks for the config file | ||
| # specifying layout. | ||
| threading.Thread(target=self._periodically_check_for_config_file).start() |
There was a problem hiding this comment.
Done. That does make logs for the thread easier to follow!
|
|
||
| layout_proto = scalars_layout_pb2.Layout() | ||
| text_format.Parse(pbtxt_contents, layout_proto) | ||
| self._layout = json_format.MessageToJson( |
There was a problem hiding this comment.
Done. That general rule sounds great, albeit we do incur a little latency from serialization at response time.
|
|
||
| CONFIG_FILE = 'custom_scalars_config.pbtxt' | ||
|
|
||
| def set_layout(logdir, scalars_layout): |
There was a problem hiding this comment.
I see what you mean ... I'm grappling with how file writer pertains to a run. A config for a run is meaningless: We only have 1 config for the dashboard. Maybe we accept a logdir for now (and pass it into plugin_asset_util.PluginDirectory()? And then we do away with the concept of logdir when say we save the config in SQL?
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
| # ============================================================================== | ||
| """Integration tests for the pr_curves plugin.""" |
| """ | ||
| self._logdir = context.logdir | ||
| self._multiplexer = context.multiplexer | ||
| self._scalars_plugin = scalars_plugin.ScalarsPlugin(context) |
| } | ||
|
|
||
| The response is an empty object if no layout could be found. | ||
| """ # pylint: disable=anomalous-backslash-in-string |
There was a problem hiding this comment.
…why? What's wrong with using a raw docstring (r"""Fetches…""") or properly escaping the metacharacter (\\d+/biases)?
There was a problem hiding this comment.
Using a raw doc string sounds great! Done.
0f00c29
to
e2f2013
Compare
Some plugins (such as the `custom-scalar` and `debugger` plugins) make use of the `vz_line_chart` component but plot data series that are not runs (such as custom run-tag combos or tensor values). This change makes the `tf-line-chart-data-loader` component accept a data series property that defaults to the list of runs. Test plan: Note that the custom scalars plugin works (allows for custom run-tag combos within `vz_line_chart`) after this change: #664
b83cc81
to
8ab307b
Compare
|
A quick update: @dandelionmane and I discussed. I plan to make We had discussed simplifying the |
8ab307b
to
6d24ec7
Compare
|
SGTM |
1cfda30
to
d2a766e
Compare
f712947
to
7f21a39
Compare
|
FYI, I am stuck by googlebot: Usually, rebasing does away with this issue, but not this time. Will keep trying things. |
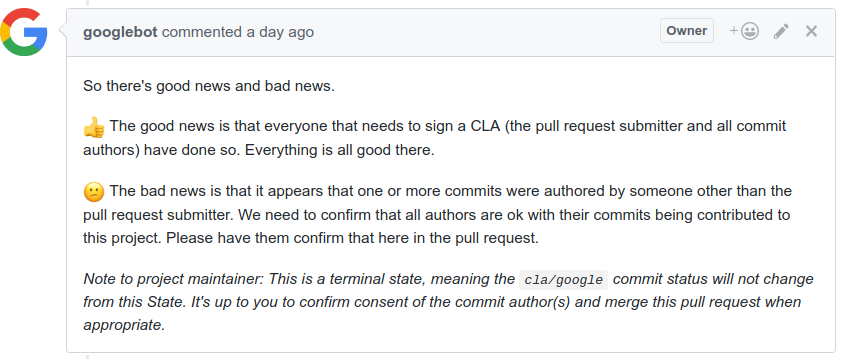
0a83d62
to
e523c78
Compare
e523c78
to
49cfe40
Compare
| scalars_layout: The scalars_layout_pb2.Layout proto that specifies the | ||
| layout. | ||
| """ | ||
| tensor = tf.make_tensor_proto( |
There was a problem hiding this comment.
Is it possible to have a precondition here to check if it's the right type of proto?
| Args: | ||
| scalars_layout: The scalars_layout_pb2.Layout proto that specifies the | ||
| layout. | ||
| """ |
There was a problem hiding this comment.
Please document that it Returns: a tf.Summary proto that can be passed to FileWriter.
| from tensorboard.plugins.custom_scalar import layout_pb2 | ||
| ... | ||
| with tf.summary.FileWriter(LOGDIR) as file_writer: | ||
| file_writer.add_summary( |
There was a problem hiding this comment.
I love this doc but it needs to be updated due to recent changes.
There was a problem hiding this comment.
Done. We now use summary.custom_scalars_pb.
There was a problem hiding this comment.
Yes but FileWriter isn't going to be used in go/tf-summaries-2.0. I guess we can change this doc later.
There was a problem hiding this comment.
OK, lets just leave out the part about constructing a FileWriter. Done.
| as="seriesName" | ||
| > | ||
| <div | ||
| class="match-list-entry" |
There was a problem hiding this comment.
go/htmlstyle should, generally speaking, take precedence when creating new files. There's no stylistic disadvantage to putting this on the previous line and then aligning the attrs.
| is="dom-repeat" | ||
| items="[[_dataSeriesStrings]]" | ||
| as="seriesName" | ||
| > |
There was a problem hiding this comment.
I'd say put this on the previous line, since nothing comes after the >.
49cfe40
to
2ccf6d5
Compare
| Args: | ||
| scalars_layout: The scalars_layout_pb2.Layout proto that specifies the | ||
| layout. | ||
| """ |
| scalars_layout: The scalars_layout_pb2.Layout proto that specifies the | ||
| layout. | ||
| """ | ||
| tensor = tf.make_tensor_proto( |
| from tensorboard.plugins.custom_scalar import layout_pb2 | ||
| ... | ||
| with tf.summary.FileWriter(LOGDIR) as file_writer: | ||
| file_writer.add_summary( |
There was a problem hiding this comment.
Done. We now use summary.custom_scalars_pb.
| is="dom-repeat" | ||
| items="[[_dataSeriesStrings]]" | ||
| as="seriesName" | ||
| > |
| as="seriesName" | ||
| > | ||
| <div | ||
| class="match-list-entry" |
|
Also, if we could make cla/google go green, that'd be great. |
| from tensorboard.plugins.custom_scalar import layout_pb2 | ||
| ... | ||
| with tf.summary.FileWriter(LOGDIR) as file_writer: | ||
| file_writer.add_summary( |
There was a problem hiding this comment.
Yes but FileWriter isn't going to be used in go/tf-summaries-2.0. I guess we can change this doc later.
2ccf6d5
to
f16d309
Compare
This plugin makes custom line charts based on regex filtering of tags.
f16d309
to
10a76d6
Compare
Sorry, I had inadvertently introduced an empty foo file into the TensorBoard directory with PR tensorflow#664.
Sorry, I had inadvertently introduced an empty foo file into the TensorBoard directory with PR #664.
It has always had wrong property value since tensorflow#664.
Cause: ignoreYOutlier instead of _ignoreYOutlier It had wrong property value since #664.
|
CLAs look good, thanks! ℹ️ Googlers: Go here for more info. |
This plugin makes custom line charts based on regex filtering of tags. Input appreciated! I want to port a prototype into google ASAP so we can test it out.
At a glance, here's how it works. The user sets the dashboard layout via a proto. For instance,
The
setmethod writes a pbtxt into$LOG_DIR/custom_scalars_config.pbtxt, which the plugin uses to organize the dashboard:Different tags within the same runs are differentiated by markers. The user can opt for certain categories to be opened by default.
Again, I really want to know everyone's feedback on this. This prototype deviates a bit from the discussion on the thread, but I think makes sense and addresses @georgedahl's needs.
I was wavering between whether to pass the dashboard organization via a flag or via a programmatic API ... and opted for the latter because