Training with GPU on TF 2.0 is much slower than on TF 1.14 if set a large number to input_dim of tf.keras.layers.Embedding
#32104
Comments
|
@DeviLeo, I tried executing the code on both the versions, looks like both versions performed same. Please take a look at gist of Tf-2.0.0-rc0 and Tf-1.14.0. Please let me if my understanding is bad. Thanks! |
|
@gadagashwini Could you try again with GPU? If training with CPU and TPU, both versions are almost the same. |
input_dim of tf.keras.layers.Embeddinginput_dim of tf.keras.layers.Embedding
|
Please take a look at colab gist with Tensorflow 1.14.0. |
|
@DeviLeo -- are you sure you're running on GPU? It's not clear how you are intending to place ops on GPU here. Have you tried with tf.distribute.MirroredStrategy? |
|
@karmel Yes, I'm sure it is running on GPU. At least I have just tried with tf.distribute.MirroredStrategy, and it worked with |
|
Can you use .fit instead? In the code snippet above, you appear to be using .fit; what requires the generator? |
|
Sorry, I'm afraid I cannot use |
|
There seems to be a significant slowdown generally when using TF2 fit_generator. It seems to be around a 3x slowdown in my own code between TF1 and TF2. It is easy to reproduce using the "Transfer Learning with TFHub" example from the TF2 official tutorials on Collab: https://www.tensorflow.org/beta/tutorials/images/hub_with_keras To reproduce it, all I did was change model.fit to model.fit_generator. I ran these cases for both TF2 and TF1. TF1 is via this change to the first code cell: Here's the training runs for the four cases: With TF1, there is no difference between fit and fit_geneator as you might hope. TF2 seems slower in general and fit_generator in particular is 3x slower than TF1--at least for this tutorial and my own code. BTW, Collab is using TF2 RC1 at the moment: |
|
Can confirm with @cupdike . I had a similar issue with my own project when switching to TF2 (stable. I waited for the official release a couple days ago), with a 2x to 3x decrease in training time for the same data and code, as compared to TF1. After some Google searching and reading, I then proceeded to implement the code using tf.data.Dataset.from_generator(), instead, which allows me to use model.fit(). Unfortunately there was 0 performance benefit either way. As for some pseudocode (posting here just in case someone can point out something fundamentally wrong with my setup), my fit_generator version of my code went something like this below. All my code uses the internal tf.keras instead of the external one: For the pseudocode using tf.data.Dataset.from_generator(): |
|
I am not sure |
|
@tabacof Hi, I created the other issue linked. There are two current resolutions to the issues people were having there; You say that you don't believe the issue is because of eager execution, the easiest way to prove that is to add the first fix The issue I encountered is that I hope that this can help you isolate the issue so that the cause can be identified. |
|
Thanks to all. I've tried The following cases are all tested with GPU on TF 2.0.0rc2 compared with TF 1.14.
Here the pseudo code I have tried. import tensorflow as tf
# `disable_eager_execution` conflicts with `tf.distribute.MirroredStrategy`.
# "AssertError: assert isinstance(x, dataset_ops.DatasetV2)" will be raised.
# tf.compat.v1.disable_eager_execution()
from tensorflow.keras.utils import Sequence
class MyGenerator(Sequence):
def __init__(self, ...):
# do something
def __iter__(self):
return self
def __len__(self):
return batches
def __getitem__(self, index):
# do something
return tuple([x1, x2, ...]), y
def train():
strategy = tf.distribute.MirroredStrategy()
print ('Number of devices: {}'.format(strategy.num_replicas_in_sync))
with strategy.scope():
model = ... # Create model
model.compile(...)
my_gen = MyGenerator(...) # Create generator
model.fit(
x=my_gen,
# Do not specify `y` and `batch_size` if x is a dataset, generator, or keras.utils.Sequence instance
# Other arguments are the same as `fit_generator`'s
...
)
if __name__ == '__main__':
train() |
|
Regarding your gist on colab, I suspect it is normal to see slower training with 2.0. When you do |
|
@Shiro-LK No, it returns True both on the colab and my computer. # python3
Python 3.6.8 |Anaconda, Inc.| (default, Dec 30 2018, 01:22:34)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>> print("Tensorflow version: ", tf.__version__)
Tensorflow version: 2.0.0
>>> print("is_gpu_available: ", tf.test.is_gpu_available())
2019-11-21 17:15:31.360917: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-11-21 17:15:31.366375: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3593275000 Hz
2019-11-21 17:15:31.367054: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x56555a7aa340 executing computations on platform Host. Devices:
2019-11-21 17:15:31.367080: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version
2019-11-21 17:15:31.368710: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
2019-11-21 17:15:31.977171: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-11-21 17:15:31.977604: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x56555a8622c0 executing computations on platform CUDA. Devices:
2019-11-21 17:15:31.977636: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): GeForce RTX 2070 SUPER, Compute Capability 7.5
2019-11-21 17:15:31.977803: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-11-21 17:15:31.978367: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:
name: GeForce RTX 2070 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.905
pciBusID: 0000:08:00.0
2019-11-21 17:15:31.978611: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0
2019-11-21 17:15:31.979953: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0
2019-11-21 17:15:31.981247: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0
2019-11-21 17:15:31.981508: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0
2019-11-21 17:15:31.983163: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0
2019-11-21 17:15:31.984398: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0
2019-11-21 17:15:31.988258: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
2019-11-21 17:15:31.988370: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-11-21 17:15:31.988985: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-11-21 17:15:31.989527: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0
2019-11-21 17:15:31.989563: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0
2019-11-21 17:15:31.990447: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-11-21 17:15:31.990469: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165] 0
2019-11-21 17:15:31.990482: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1178] 0: N
2019-11-21 17:15:31.990590: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-11-21 17:15:31.991174: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-11-21 17:15:31.991771: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1304] Created TensorFlow device (/device:GPU:0 with 7478 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:08:00.0, compute capability: 7.5)
is_gpu_available: True |
|
Hi guys, any updates? |
|
@DeviLeo and @maximveksler can you please try with 2.2.0-rc2, there have been multiple fixes in improving 2.x performance. here is a colab gist of the original issue with 2.2.0-rc2. |
|
@DeviLeo Thanks for the report! Would you mind trying this on tf==2.2, since it contains many performance improvements on eager |
|
@goldiegadde and @tanzhenyu I have tried on Eager mode: Disabled Tensorflow version: 2.2.0-rc2
Tensorflow eager mode: False
is_gpu_available: True
Train on 10000 samples
Epoch 1/3
10000/10000 [==============================] - 1s 87us/sample - loss: 0.8003
Epoch 2/3
10000/10000 [==============================] - 1s 90us/sample - loss: 0.7889
Epoch 3/3
10000/10000 [==============================] - 1s 90us/sample - loss: 0.7758Tensorflow version: 1.15.2
Tensorflow eager mode: False
is_gpu_available: True
Train on 10000 samples
Epoch 1/3
10000/10000 [==============================] - 1s 95us/sample - loss: 0.7089
Epoch 2/3
10000/10000 [==============================] - 0s 31us/sample - loss: 0.7039
Epoch 3/3
10000/10000 [==============================] - 0s 32us/sample - loss: 0.6972Eager mode: Enabled Tensorflow version: 2.2.0-rc2
Tensorflow eager mode: True
is_gpu_available: True
Epoch 1/3
40/40 [==============================] - 7s 181ms/step - loss: 0.7136
Epoch 2/3
40/40 [==============================] - 7s 178ms/step - loss: 0.7085
Epoch 3/3
40/40 [==============================] - 7s 177ms/step - loss: 0.7034Tensorflow version: 1.15.2
Tensorflow eager mode: True
is_gpu_available: True
Train on 10000 samples
Epoch 1/3
10000/10000 [==============================] - 9s 947us/sample - loss: 0.9751
Epoch 2/3
10000/10000 [==============================] - 8s 845us/sample - loss: 0.9588
Epoch 3/3
10000/10000 [==============================] - 8s 848us/sample - loss: 0.9409So, I think the issue is solved. Thank you all. |
Awesome! |
|
Just upgraded to TF 2.2 . Having huge performance issues with keras models. Update : Update 2 : |
|
Having similar problems to DollarAkshay. For me, I can't get lookup table initializers to work with eager execution disabled. Strongly considering PyTorch at this point. |
|
It seems contradictory to what @DeviLeo verified -- do you have a concreate code snippet to reproduce? |
|
Having the same problem. I have upgraded to TF2.2. Moreover, I use the CPU to run the code. Through analyzing the timeprofile, I also find the embedding_lookup ReadVariableOp takes the too much time. |
I have the same problem,Tensorflow version is 2.5.0. |
@PWZER I met the same issue and I fixed it by upgrading to TF2.6 |
System information
Linux-3.10.0-957.21.3.el7.x86_64CentOS-7.3.1611-Core2.0.0-rc0(v2.0.0-beta1-5101-gc75bb66),1.14.0(v1.14.0-rc1-22-gaf24dc91b5)Describe the current behavior
I converted the
Kerasimplementation ofNeural Matrix Factorization (NeuMF)totf.kerasand it works well on TF 1.14.But when I run it on TF 2.0.0-rc0, the training is much slower than on TF 1.14.
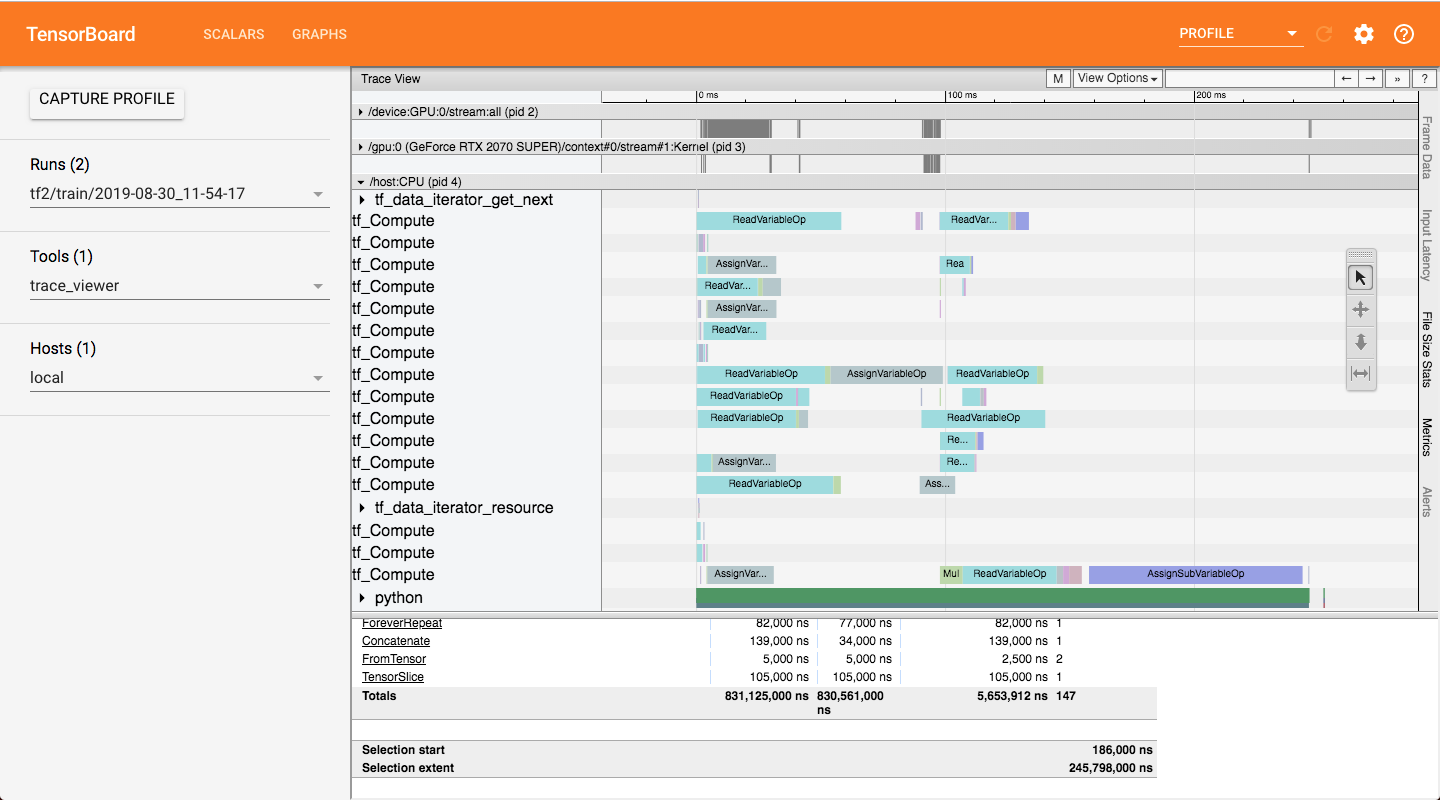
I use the profiling tools to check the time, and I found
ReadVariableOptakes too much time if I set a large number to theinput_dimoftf.keras.layers.Embedding.Describe the expected behavior
The speed of training on TF 2.0 with large
input_dimofEmbeddingshould be the same as TF 1.14 or faster.Code to reproduce the issue
I have shared the codes on Colab
or check the codes below.
Other info / logs
The attachment 'tb-logs.zip' is the tensorboard logs.
The profiling screenshot of the training on TF 2.0.0-rc0.
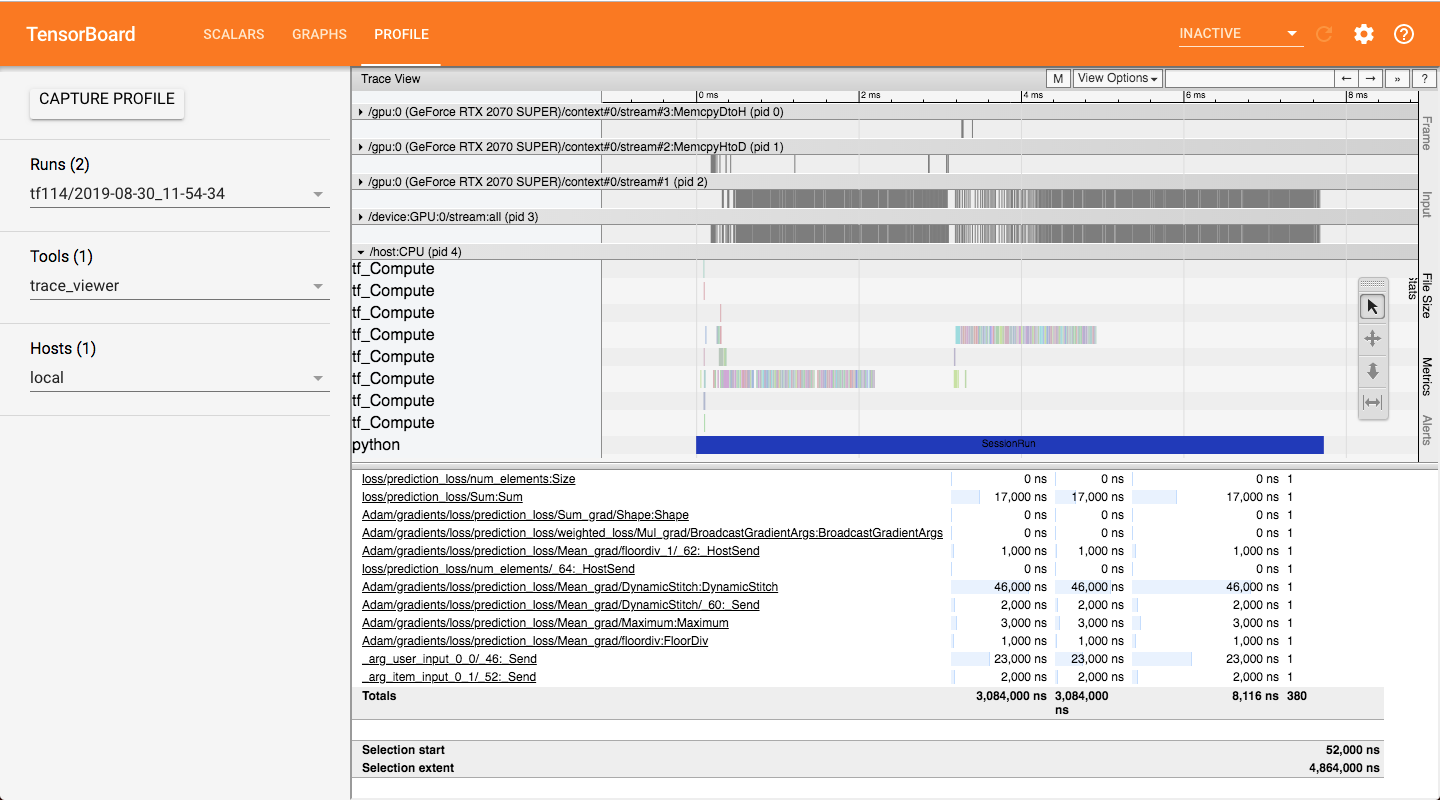
The profiling screenshot of the training on TF 1.14.
The text was updated successfully, but these errors were encountered: