[MixedPrecision] DynamicLossScale should accept scale_loss smaller than one #38357
Comments
|
@chychen, Will it possible to provide the sample code to analyze the reported issue. Thanks! |
|
@gadagashwini Please see Before/After in following pdf file. TF2#38357.pdf |
|
@chychen, Instead of pdf can you share the executable code or provide the colab gist to reproduce the issue . Thanks |
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.mixed_precision import experimental as mixed_precision
policy = mixed_precision.Policy('mixed_float16')
mixed_precision.set_policy(policy)
print('Compute dtype: %s' % policy.compute_dtype)
print('Variable dtype: %s' % policy.variable_dtype)
inputs = keras.Input(shape=(784,), name='digits')
num_units = 4096
dense1 = layers.Dense(num_units, activation='relu', name='dense_1')
x = dense1(inputs)
dense2 = layers.Dense(1, activation='relu', name='dense_2')
outputs = dense2(x)
model = keras.Model(inputs=inputs, outputs=outputs)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
optimizer = keras.optimizers.RMSprop()
optimizer = mixed_precision.LossScaleOptimizer(optimizer, loss_scale='dynamic')
loss_object = tf.keras.losses.MeanSquaredError()
train_dataset = (tf.data.Dataset.from_tensor_slices((x_train, y_train))
.shuffle(10000).batch(1024))
@tf.function
def train_step(x, y):
with tf.GradientTape() as tape:
predictions = model(x)
loss = loss_object(y, predictions) * 10000.
scaled_loss = optimizer.get_scaled_loss(loss)
scaled_gradients = tape.gradient(scaled_loss, model.trainable_variables)
gradients = optimizer.get_unscaled_gradients(scaled_gradients)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
for epoch in range(2):
for i, (x, y) in enumerate(train_dataset):
mp_loss_scale = optimizer.loss_scale().numpy()
loss = train_step(x, y)
print('epoch {}: step {}: loss={}, loss_scale={}'.format(epoch, i, loss, mp_loss_scale))Compute dtype: float16 |
|
In practice, I have never seen losses or intermediate gradients so large that they overflow in float16 when the loss scale is 1. The max float16 value is 65504, which be an enormous gradient. The reason the loss scale cannot go below 1 is that conceptually the purpose of a loss scale is to avoid underflow. @nluehr, @benbarsdell, any thoughts on having a loss scale below 1? I don't think this would happen in practice much, and if it did, I imagine the model would not converge to a good accuracy. The current behavior of keeping the loss scale at 1 also would converge poorly, as it just causes every step to be skipped. |
|
I could replicate the issue with Tf 2.2rc2. |
|
In the example above, the INF is generated in the forward pass. Running in FP32, I see an initial loss of 279232.1875, which exceeds the representable range of fp16. Loss scaling gets applied after the loss is computed, so no value of loss scale will help in this case. |
|
True, in this case it wouldn't help, but what about in general? Do you think it's likely the backwards pass could overflow without the forwards pass overflowing? Even if it's unlikely, should we allow the loss scale to go below 1? |
Just casting the loss is not sufficient; it it is already NAN in fp16 and will be NAN when cast to fp32. The forward pass needs to cast the unsafe ops that produced the NAN values to fp32. When this is done, the corresponding backward ops will also use fp32, so those should have no numerical issues if the loss scale clamps at one. Other ops did not produce NANs on the forward pass, and are expected to produce smaller values in backward, so a loss scale of one should be fine here as well. In the provided example, the second dense layer is essentially serving as a reduction. When it is performed with 4 is rather close to 1, so it is possible a loss scale below 1 could be required in some corner case. In practice I have not seen such a case. On the other hand, the loss scale cannot be used to work around a NaN in the loss, that requires assigning ops to fp32. Some lower bound on the loss scale is necessary (letting it be reduced all the way to zero, for example, has obvious problems). Setting the lower bound to the point where loss scaling becomes a numerical no-op (i.e., multiply by one) is appealing, but not strictly necessary. However, we would need an example model requiring a lower loss scale in order to determine where to set a new lower bound. |
|
Dear @nluehr, I don't see any strong reasons you insisted not to adjust it. if possible the scale smaller than one, why not just relax it? I really can't understand. |
|
@chychen, I am not insisting against reducing the lower bound below one. However, I do think some lower bound is needed. It is better to error out with overflowing gradients than let the loss scale drop near zero and silently quench convergence (because many/most gradients underflow to zero). It is difficult for me to decide what the lower bound on the loss scaler should be without some typical models that need this change. I would also like to understand the problem in more detail in order to evaluate whether reducing the loss_scale is the best solution. It might be better to cast some additional layers to float32 because an agressively small loss scale will cause underflow in a subset of the model parameters and could result in poor convergence compared to fp32. I'm curious, have you adjusted the loss scale interval in your TF installation to unblock your research? With this change did your models train all the way to expected accuracy? What was the smallest required loss scale? Given the uncertainties and risks, I would rather not change the default behavior. Perhaps a custom loss scale interval could be optionally provided when constructing the optimizer. @reedwm, any thoughts? |
|
in my experience, yes, adjust the loss scale unblock my research. I think custom interval is a good solution. or maybe check whether loss is zero to scale back the factor? just like the solution for nan overflow situation. |
|
As @nluehr stated, it's difficult to come to a decision here without knowing of any model that requires a loss scale below 1. One potential workaround is to copy the DynamicLossScale implementation, but change the minimum loss scale from 1 to some lower number. Note the loss scale classes are still experimental so the copied class may break in a future version of TensorFlow.
Perhaps the variable initialization should be modified so the L2 loss is not as big. Altneratively, you can start training in float32 for the first few steps, then switch to mixed precision training. This can be accomplished by saving a checkpoint from a float32 model then restoring the checkpoint into an equivalent mixed precision model. |
|
Hi there @reedwm and @nluehr. Im currently having the same problem as @chychen.
I have monkey-patched the
That would be great. But why not remove the constraint completely? It sound like the argument is "We want to always prevent underflow, and for that reason we put a limit which will cause overflow.". I mean, if the worst thing that can happen is underflow, why should that be a reason to enforce an overflow? I would be happy to try other approaches to lower the loss if you have any sensible (best practice) suggestions, but I will not hack my way around it. |
|
Here is the loss scale in two different training runs |
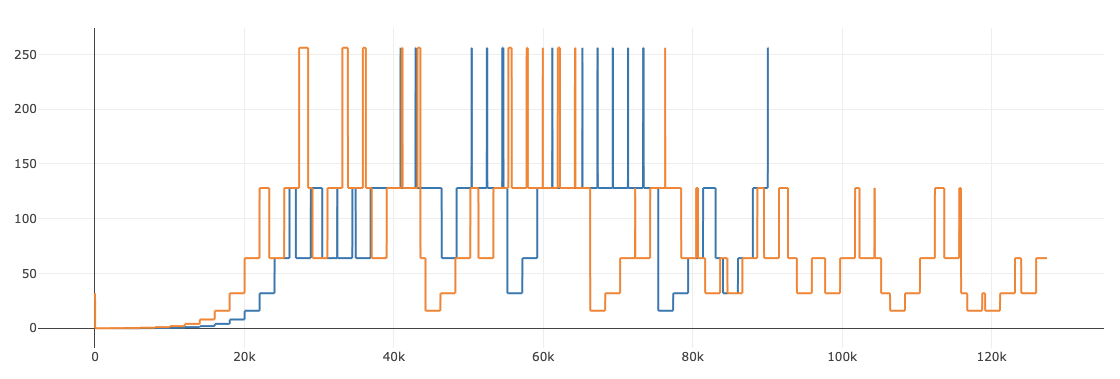
|
It is difficult to make a decision in the Also, class LossScaleBelowOneOptimizer(tf.keras.mixed_precision.LossScaleOptimizer):
MULTIPLIER = 2 ** 10
@property
def actual_loss_scale(self):
return self.loss_scale / self.MULTIPLIER
def get_scaled_loss(self, loss):
if callable(loss):
def new_loss():
loss_val = loss()
return loss_val * tf.cast(self.actual_loss_scale, loss_val.dtype)
return new_loss
else:
return loss * tf.cast(self.actual_loss_scale, loss.dtype)
def get_unscaled_gradients(self, grads):
reciprocal = 1. / self.actual_loss_scale
return [g * reciprocal if g is not None else None for g in grads]This allows the effective loss scale to go as low as
I am worried that allowing the loss scale to go below 1 will cause confusion. A model may get NaNs on the forward pass, in which case the gradients will be NaN regardless of the loss scale. If the loss scale could go below 1, the loss scale would be repeatedly lowered every step until it reached zero. I think we should raise an error if the loss scale reaches 1 or if the loss is NaN, but this is tricky to implement without reducing performance. If we find there are a significant number of models which benefit from a loss scale below 1, we can also add a |
|
Thanks for the pointer on how to adjust for newer versions of tensorflow. Appreciate it.
Agree. I took me quite some digging to find out why my loss did not converge, would have been very helpful with an error message.
It is for commercial use so I cannot go into a lot of details unfortunately. But it an hourglass network with a lot of 3x3 convolutions. |
https://github.com/tensorflow/tensorflow/blob/r2.2/tensorflow/python/training/experimental/loss_scale.py#L391
self._current_loss_scale >=1is unnecessary and wrong.In some use cases, loss is possible overflow
infin float16, thereforeself._current_loss_scale<1is necessary for mixed precision training.The text was updated successfully, but these errors were encountered: