Massive memory leaks due to data.Dataset.shuffle #44176
Comments
|
I cannot reproduce the issue when I ran your program using internal version of TensorFlow at HEAD and I am not aware of any issues that got fixed between TF 2.3 and now that could explain that. Could you set the Lastly, how do you measure the memory consumption? |
|
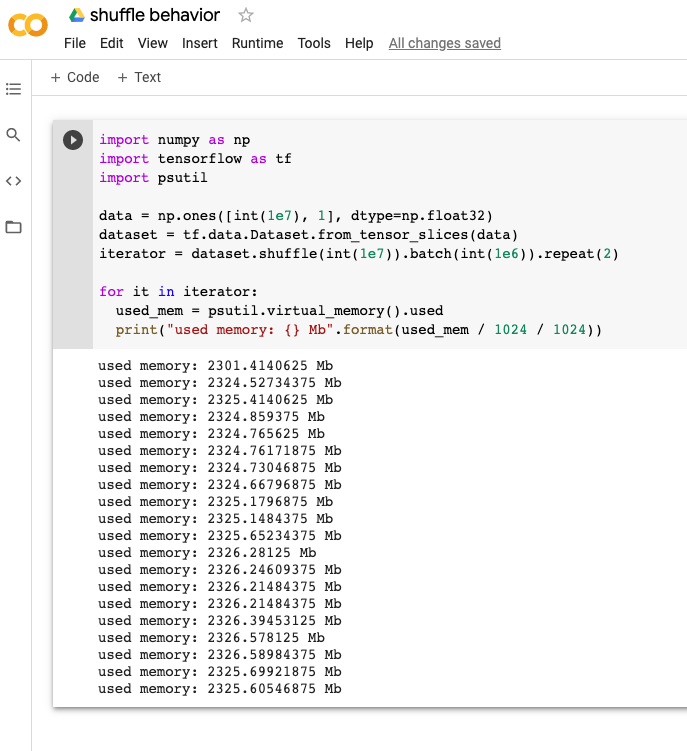
@jsimsa Can you check this code. The memory usage keeps increasing. import numpy as np
import tensorflow as tf
import psutil
data = np.ones([int(1e7), 1], dtype=np.float32)
dataset = tf.data.Dataset.from_tensor_slices(data)
iterator = dataset.shuffle(int(1e7)).batch(int(1e6)).repeat(10)
for it in iterator:
used_mem = psutil.virtual_memory().used
print("used memory: {} Mb".format(used_mem / 1024 / 1024))Am I using it correctly? |
|
@shauidu I cannot reproduce this using public colab
|
|
I'm having the same issue. System information(s) (I've tried two different configurations): Issue: Output: Edit: Generally speaking, running the code in CPU mode shows some memory cleaning, but overall, memory usage increases as follows: used memory: 6375.6015625 Mb |
|
@federicoruggeri what do the numbers look like when you remove the |
|
@jsimsa Disabling shuffle gives the following results. Memory usage seems stable. CPU: GPU: |
|
@federicoruggeri can you reproduce this issue in a colab? I cannot reproduce the issue in my environment. |
I've tried the colab session that you've linked above, but I'm not able to reproduce the issue there. My initial guess was that the colab runtime was using tensorflow==2.3 (no gpu) but the same configuration does not work for me. Just to be sure about that, I've created a virtualenv from scratch with just tensorflow==2.3 and python 3.5.0. Running the same toy script does show the memory leak issue. Therefore, I don't know if the problem does not show in the colab session due to some additional package that is installed there. Could the python version mean something here? I'm a bit sceptic about this since @sehoffmann was using python 3.6.9 (yet another version). |
|
@federicoruggeri can you try @jsimsa script in an official Tensorflow Docker image? |
|
Sorry for the late reply! I've tried running the script in the following docker tensorflow image: tensorflow/tensorflow:latest-gpu-jupyter CPU, no shuffle: CPU, shuffle: As you can see, enabling shuffles causes the same memory leak issue. |
|
Can you check also with |
|
Here you are! CPU, no shuffle: CPU, shuffle: |
|
Do you have an updated Nvidia driver? |
|
Info: I've tried also the 450 driver Is it ok? |
|
It Is strange that It Is GPU only. Can you try to give a run with https://www.tensorflow.org/api_docs/python/tf/config/experimental/set_memory_growth |
|
@bhack Actually the problem seems to not related to the device. I've tested tensorflow-gpu (different versions) with and without GPU device, as well as standard tensorflow. As you suggested, I've also tried by enabling memory growth (that's what I usually do) but the memory leak still appears. The strange thing is that the same code on the colab session works fine. I don't know if it is a combination of tensorflow packages (and their versions) that does the trick.. |
|
Yes It was very strange if It was related to the GPU package. The problem is the Colab has its own build from soruce. Can you try on Colab with |
|
Here's the link to the colab session: https://colab.research.google.com/drive/1MKQmTbly7BxSJVxEjlgdO-ZpRsVK0RhJ?usp=sharing I'm not sure I've done eveything correctly (debug print messages seem ok to me): running For what concerns the test script, it runs fine without any memory issue. |
|
I have recently investigated the memory growth observed for OSS version of TensorFlow when For the evaluation, I used the following simple input pipeline: When executed on workstation, it produces the following output: I then installed tcmalloc using Not only the gradual memory growth disappeared, but the program also ran 2x faster. |
|
Is this about a specific glibc version? |
|
Also I don't know if we could pilot some specific tuning with |
|
Independently arrived at a similar memory issue in a training situation I'm working on. In my case, we had a lot of RAM, and we noticed that after 3 or so epochs, it no longer continued incrementing. After swapping to the malloc library above, from the start we had it staying constant! Thanks @jsimsa for posting your fix! Is this dependency issue even mentioned anywhere in the TF docs? |
What Is your glibc version? |
|
2.27-3ubuntu1 |
It could be nice to test this with a more recent glibc version |
My experiments used |
|
@jsimsa Can you reproduce the memory growing in your example prefix |
|
@bhack Unfortunately, I will not have cycles to investigate this further in the near future. |
|
Ok just to confirm that I cannot reproduce your example with |
|
Hi @jsimsa, So I tried your solution which solved my memory problem but it's 2x slower (TF version: 2.4.0). is there any fix planned to this issue in the upcoming releases ? |
|
Any tips on what to do if the tcmalloc LD_PRELOAD only works occasionally?
It only worked 3 or 4 times so far (out of maybe 50 runs). Using Ubuntu 20.04 amd64. |
|
This may be related to how glibc works for smaller allocations, the ones that are not mmaped. IIUC, glibc import tensorflow as tf
import psutil
dataset = tf.Dataset.range(int(1e7))
iterator = dataset.shuffle(int(1e7)).batch(int(1e6))
for _ in iterator:
used_mem = psutil.virtual_memory().used
print("used memory: {} Mb".format(used_mem / 1024 / 1024))and run as follows the leak disappears. Forcing mmap everywhere also "works" Using tcmalloc is still ~2x faster however. |
|
This may explain the issue we're seeing here: https://blog.cloudflare.com/the-effect-of-switching-to-tcmalloc-on-rocksdb-memory-use/. |
|
it still useless |
|
sorry, i try it again, it indeed works. |
System information
Describe the current behavior
When a new iterator to a dataset containing a
shuffle()iteration is opened after the old one became completely exhausted,the memory held by the
ShuffleDatasetis not released / reused, resulting in massive memory leaks and ultimately in the process being killed by the OOM reaper.For this purpose it does not matter whether we manually iterate over the dataset, use a Keras function like
Model.fit()or chain aDataset.repeat()operation at the end.The original bug was found in production code and the condensed code below outlines roughly our original data pipeline
but perfectly reproduces the problem.
Describe the expected behavior
Memory usage should be constant when a new iterator to the Dataset is opened and there are no existing iterators anymore.
To be extra safe it might be desirable to immediately release any memory held by the
ShuffleDatasetwhen iteration is done,so that other components can use it. (maybe introduce parameter controlling the behaviour?). This could be very important in conjunction with
Dataset.interleave(), e.g when we iterate 36 files with acycle_lengthof four and only have enough memory to hold 4 shuffle buffers in memory. If memory is not immediately released, we would run out of memory after the first four files have been processed.Standalone code to reproduce the issue
I run the code with the
memory-profilerpackage (https://pypi.org/project/memory-profiler/) to generate plots of the memory usage. By default shuffle buffers are enabled but when any additional argv is passed, shuffle buffers will be disabled:Example usage:
mprof run --include-children test.pyormprof run --include-children test.py no-shuffleI recommend at least 32 GB of memory so that you can properly observe the behaviour. Otherwise feel free to tune down the memory usage in the code, for example by reducing the image size from 512x512 to 256x256.
Other info / logs
The first run uses shuffling and we can clearly see the buffer filling up again after each epoch without the old memory being released (it appears that sometimes a small fraction is released though). I'm not sure why the buffers use 8gb in total opposed to the theoretical 4gb. After the fourth epoch the process is killed on my machine, because i run out of memory (32gb):
Log:
For the second run I disabled shuffling and we can see that there is still some leakage yet much more irregularly. In previous test runs which used our original data-pipeline, I was able to achieve a flat memory usage by disabling the shuffling; I'm not sure why it doesn't work with the test script though. This might require further investigation. I manually terminated the script after a while.
Log:
The text was updated successfully, but these errors were encountered: