[TFLite] Quantization and unfolding of the ADD_N operator #44806
Comments
|
This is a good example of quantization aware conversion. FYI, @karimnosseir @renjie-liu |
|
@Tessil We should be doing the TF Lowering pass and you should see the add Tree. Did you try converting using the nightly build ? |
|
I think that is the expected behavior. The TF Lower pass will be trigged only when the given TensorFlow core operators are not directly legalized. Since we have the ADD_N op implementation, the legalization procedure prefers adding the the TFLite ADD_N op into the flatbuffer over the ADD op tree addition. If we would do that always, we need to add the the ADD_N op --> ADD op tree lowering rule in the early TensorFlow preparation stage. |
|
Thank you very much for your answers. I did my tests with the nightly build. Note that if we lower the ADD_N to a series of ADD, it would be nice to keep some coherence with the lowering done in |
|
Hi @abattery @karimnosseir I was wondering if there was any eventual news on the issue? Should we aim to lower the |
|
For the workaround, maybe you create a custom keras layer to meet your needs. |
|
For now we can just replace |
|
@teijeong could you triage this issue? |
|
FYI, @jianlijianli |
|
Hi @abattery, out of interest, what is the difference between "ModelOptimizationTookit" and "TFLiteConverter" labels? I noticed you re-assigned this issues from the latter to the former above. Quick check of other issues under both seems to suggest that both are applicable to issues with the TFLite Converter. |
|
TFLite converter is a gateway to the TFLite product. However, it contains several components, TF -> TFLite graph lowering and model optimization techniques. This issue is related to the model optimizations so to be clear, we tried to set the model optimization tag for such cases. |
|
@Tessil |
|
Hi, yes |
|
Hi, Thank you for opening this issue. Since this issue has been open for a long time, the code/debug information for this issue may not be relevant with the current state of the code base. The TFLite team is constantly improving the framework by fixing bugs and adding new features. We suggest you try the latest TensorFlow version with the latest compatible hardware configuration which could potentially resolve the issue. If you are still facing the issue, please create a new GitHub issue with your latest findings, with all the debugging information which could help us investigate. Please follow the release notes to stay up to date with the latest developments which are happening in the TFLite space. Thanks. |
|
This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you. |
|
Hi, The issue is still present in the latest 2.13 version of TF. |
Hello,
When adding multiple tensors (> 2) in a NN we can either use
tf.keras.layers.Addortf.math.add_n. The first one is quantizable but not the second one as unfortunatly even if both have the same high-level functionality they aren't converted in the same way when using the TFLiteConverter.The
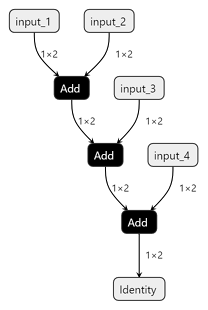
tf.keras.layers.Addlayer is converted to a cascade of binary ADD operators:The
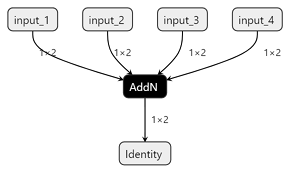
tf.math.add_non the other hand is converted to a single not yet quantizabe ADD_N operator:It seems there is an existing
LowerAddNOptransformation to lower the ADD_N operator into an adder tree of binary ADD operators (instead of a cascade) but for some reasons it doesn't seem to apply during the tests I did.As both functions provide the same functionality it would be ideal for them to be exported in the same way in TFLite to avoid any output difference which could occur due to different kernel implementations and additions order as the floating-point and quantized additions are not associative. Unfolding the ADD_N operator would also allow to easily reuse the optimized ADD kernels (both for HW and SW kernels).
As we would like to add support for the quantization of models with
tf.math.add_nI was wondering what were the plans regarding the ADD_N kernel. Would it be alright to unfold it into a cascade of adds? Or was the plan to unfold it into an adder tree (which would then produce different results thantf.keras.layers.Addas the order of additions would not be the same)?Thanks,
Thibaut
The text was updated successfully, but these errors were encountered: