different output value in pytorch->onnx->tflite(int8 quantization) #52357
Comments
|
@JunhoohnuJ |
|
#1. """make input""" import numpy as np #2. """pytorch to onnx""" import torch model = resnet50(pretrained=True) x = np.load('input.npy') torch.onnx.export(torch_model, #3. """onnx runtime""" x = np.load('input.npy') #4. """onnx to pb""" onnx_model = onnx.load("backbone.onnx") tf_rep = prepare(onnx_model) model = tf.saved_model.load(tf_model_path) x = np.load('input.npy') output_pytorch = np.load('output_pytorch.npy') #5. """pb to tflite""" input_shape = (3, 256, 256) def representative_data_gen(): tf_model_path = "backbone_saved_model/" with open(tflite_model_path, 'wb') as f: #6. """inference tflite""" pose_post_model_file = 'backbone.tflite' interpreter = tflite.Interpreter(model_path=pose_post_model_file) input_details = interpreter.get_input_details() x = np.load('input.npy') interpreter.invoke() output_pytorch = np.load('output_pytorch.npy') each output is output_.npy( is pytorch, onnx, pb, tflite) |
|
Same issue with custom CenterNet model based on PyTorch. My pipeline for conversion is follows: PyTorch-> ONNX -> Keras -> TFLite. Interestingly, that error(Absolute and squared errors) between output tensors of PyTorch and Keras(after conversion) models is near zero. But, when conversion from Keras to TFLite is done the error is big. |
thank you for comment. Can you tell me how many errors occurred specificantly? |
|
@Xhark @liufengdb @ebrevdo @jianlijianli I am seeing mobilenet_v2 tflite(quatized) that I generated from pytorch is not working as expected. //github link |
|
@Xhark @liufengdb @ebrevdo @jianlijianli : Gentle reminder.! |
|
Same issue with a Resnet based backbone feature extractor model initialized and trained from timm in pytorch. Pytorch > Onnx > Tensorflow PB with all minimal accuracy loss. Tflite FP32 and Dynamically quantized INT8 works fine as well, but statically quantized INT8 model totally fails with 0AP |
|
@JunhoohnuJ ! @nyadla-sys ! |
|
Same issue for all the YOLOX family models. TFLite FP32 and FP16 works perfectly. But the output discrepancies are large between the tflite models and the quantized ones to the degree that they are unusable.
|
|
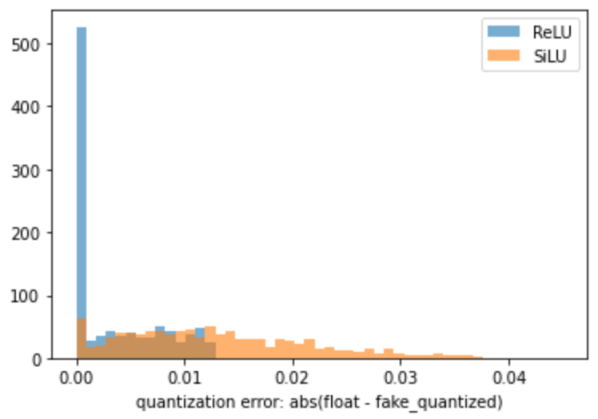
YOLOX's INT8 outputs now match within almost an acceptable margin of error. Sorry for the trouble. Therefore, I have deleted my post immediately preceding the misleading one. It is an issue of ML model structure. A quote from an issue of a conversion tool I am creating. Thus, differences in the route of conversion were not related to accuracy degradation. It is a matter of model structure. The activation function, kernel size and stride for
|






|
No, it is more of a SiLU issue. |
|
Will try to replace all the SiLU modules by ReLU. Should be straight forward. Then retrain of course... |
|
|
|
Btw, what is the Y axis @PINTO0309 ? |
|
If your issue is resolved, could you please close this issue. Thanks! |
|
This issue is stale because it has been open for 7 days with no activity. It will be closed if no further activity occurs. Thank you. |
|
This issue was closed because it has been inactive for 7 days since being marked as stale. Please reopen if you'd like to work on this further. |
Please make sure that this is an issue related to performance of TensorFlow.
As per our
GitHub Policy,
we only address code/doc bugs, performance issues, feature requests and
build/installation issues on GitHub. tag:performance_template
System information
You can collect some of this information using our environment capture
script
You can also obtain the TensorFlow version with:
python -c "import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)"python -c "import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)"Describe the current behavior
I convert resnet50 pytorch -> onnx -> tflite with int8 quantization.
output value validation between pytorch <-> onnx, pytorch <-> pb, pytorch <-> tflite, pb <-> tflite
input is same image with size 256, check output value "np.testing.assert_allclose(output1, output2, rtol=1e-3, atol=1e-05)"
(using tflite interpreter only when i inference tflite "https://www.tensorflow.org/lite/guide/python?hl=ko")
Max absolute difference: 0.00076199 in pytorch <-> onnx
Max absolute difference: 0.00112534 in pytorch <-> pb
Max absolute difference: 13.387602 in pytorch <-> tflite(quantized)
Max absolute difference: 13.387438 in pb <-> tflite(quantized)
it's same max absolute difference between tflite(no quantized) and something(pytorch, onnx, pb)
ex) 0.0076~ in pytorch <-> tflite(no quant), 0.0011~ in pytorch <-> tflite(no quant)
i don't know why occur this difference
Standalone code to reproduce the issue
Provide a reproducible test case that is the bare minimum necessary to generate
the problem. If possible, please share a link to Colab/Jupyter/any notebook.
Other info / logs Include any logs or source code that would be helpful to
diagnose the problem. If including tracebacks, please include the full
traceback. Large logs and files should be attached.
pb to tflite log
2021-10-13 09:18:56.162936: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2021-10-13 09:18:57.485452: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcuda.so.1
2021-10-13 09:18:57.511230: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.511916: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3090 computeCapability: 8.6
coreClock: 1.86GHz coreCount: 82 deviceMemorySize: 23.68GiB deviceMemoryBandwidth: 871.81GiB/s
2021-10-13 09:18:57.511955: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2021-10-13 09:18:57.513717: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11
2021-10-13 09:18:57.513767: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11
2021-10-13 09:18:57.514354: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcufft.so.10
2021-10-13 09:18:57.514537: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcurand.so.10
2021-10-13 09:18:57.515198: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusolver.so.11
2021-10-13 09:18:57.515720: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusparse.so.11
2021-10-13 09:18:57.515866: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudnn.so.8
2021-10-13 09:18:57.515918: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.516398: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.516976: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
2021-10-13 09:18:57.517199: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-10-13 09:18:57.517766: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.518224: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3090 computeCapability: 8.6
coreClock: 1.86GHz coreCount: 82 deviceMemorySize: 23.68GiB deviceMemoryBandwidth: 871.81GiB/s
2021-10-13 09:18:57.518272: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.518814: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.519243: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
2021-10-13 09:18:57.519268: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2021-10-13 09:18:57.810376: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-10-13 09:18:57.810410: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264] 0
2021-10-13 09:18:57.810420: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1277] 0: N
2021-10-13 09:18:57.810591: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.811162: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.811684: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:57.812186: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1418] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 21512 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:01:00.0, compute capability: 8.6)
2021-10-13 09:18:58.498192: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:345] Ignored output_format.
2021-10-13 09:18:58.498225: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:348] Ignored drop_control_dependency.
2021-10-13 09:18:58.498234: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored change_concat_input_ranges.
2021-10-13 09:18:58.498881: I tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: backbone_saved_model/
2021-10-13 09:18:58.515289: I tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2021-10-13 09:18:58.515331: I tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: backbone_saved_model/
2021-10-13 09:18:58.515383: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-10-13 09:18:58.515393: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264]
2021-10-13 09:18:58.527926: I tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2021-10-13 09:18:58.546224: I tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 3699850000 Hz
2021-10-13 09:18:58.563849: I tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: backbone_saved_model/
2021-10-13 09:18:58.577967: I tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 79088 microseconds.
2021-10-13 09:18:58.657933: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:210] disabling MLIR crash reproducer, set env var
MLIR_CRASH_REPRODUCER_DIRECTORYto enable.2021-10-13 09:18:58.675431: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:58.675985: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3090 computeCapability: 8.6
coreClock: 1.86GHz coreCount: 82 deviceMemorySize: 23.68GiB deviceMemoryBandwidth: 871.81GiB/s
2021-10-13 09:18:58.676068: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:58.676635: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:58.677107: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
2021-10-13 09:18:58.677148: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-10-13 09:18:58.677157: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264] 0
2021-10-13 09:18:58.677165: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1277] 0: N
2021-10-13 09:18:58.677253: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:58.677779: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-10-13 09:18:58.678280: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1418] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 21512 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:01:00.0, compute capability: 8.6)
fully_quantize: 0, inference_type: 6, input_inference_type: 0, output_inference_type: 0
The text was updated successfully, but these errors were encountered: