The tutorial "Logging and Monitoring Basics with tf.contrib.learn" has error. #7669
Comments
|
@lienhua34 yes it's correct. The interface has been sealed recently. Welcome to submit a pull request! @martinwicke Does the team have any plan to rewrite Monitor tutorial by Hooks? |
|
Sanders, didn't you already do that? |
|
No, I did update this tutorial back in December, but haven't yet switched to use In the meantime, for an example of applying a |
|
@ispirmustafa: FYI regarding our discussion today about
"SingleWorkerEvaluationHook"
|
|
I'm also following this tutorial and having problems with it. I'm using the latest 1.0.1 release.
Is there any working example for these monitors |

|
I have the same problem,and it does not work after changing tf.contrib.learn.metric_spec.MetricSpec/tf.contrib.learn.prediction_key.PredictionKey to tf.contrib.learn.MetricSpec/tf.contrib.learn.PredictionKey.Any one could help? |
|
@terrytangyuan @sandersk |
|
Yes. All Monitors are deprecated. Not all of them have a direct equivalent, but there should be hooks for the main use cases. Except ValidationMonitor, as of today. |
|
I wanted to learn, TF and started off with tf.contrib.learn from https://www.tensorflow.org/get_started/tflearn. However I got stuck in the same problem with ValidationMonitors. I understand that they are depreciated now. I don't have the head to go through the new "hooks" tutorial. for visualizing through tensor board yet. Is there a simple tutorial using iris dataset as a continuation from ~/get_started/fflearn ? |
|
when I run the " iris_monitors.py" AttributeError: module 'tensorflow.contrib.learn' has no attribute 'prediction_key' |
|
@ispirmustafa FYI We should be fixing this as part of our tutorials rewrite for core estimators. |
|
is there any update regarding ValidationMonitor as hook? The documentation seems to not be updated |
|
I am in the same boat as "agniszczotka". |
|
AxenGitHub I managed to run validation through training by using experiment I am not sure how effective is it yet, but it did a job. |
|
@agniszczotka Thanks for your help. When I implement your suggestion, I get the following error: |
|
It was resolved by adding the following lines (see here) |
|
How can I use early_stopping in environment? |
|
@Moymix you can implement early stopping by using the BATCH_SIZE = 10
EARLY_STOP_COUNT = 15
# Model function
def model_fn(features, labels, mode):
# ...
eval_metric_ops = { "accuracy" : accuracy}
return tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
# Early stopping function
accuracy_reg = np.zeros(EARLY_STOP_COUNT)
def early_stopping(eval_results):
# None argument for the first evaluation
if not eval_results:
return True
accuracy_reg[0 : EARLY_STOP_COUNT - 1] = accuracy_reg[1 : EARLY_STOP_COUNT]
accuracy_reg[EARLY_STOP_COUNT - 1] = eval_results["accuracy"]
counts = 0
for i in range(0, EARLY_STOP_COUNT - 1):
if accuracy_reg[i + 1] <= accuracy_reg[i]:
counts += 1
if counts == EARLY_STOP_COUNT - 1:
print("\nEarly stopping: %s \n" % accuracy_reg)
return False
return True
# Main function
def main(unused_argv):
#...
estimator = tf.estimator.Estimator(
#...
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"data": train_data},
y=train_labels,
batch_size=BATCH_SIZE,
num_epochs=None, # Continue until training steps are finished
shuffle=True
)
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"data": validate_data},
y=validate_labels,
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False
)
experiment = tf.contrib.learn.Experiment(
estimator=estimator,
train_input_fn=train_input_fn,
eval_input_fn=eval_input_fn,
train_steps=80000,
eval_steps=None, # evaluate runs until input is exhausted
eval_delay_secs=180,
train_steps_per_iteration=1000
)
experiment.continuous_train_and_eval(
continuous_eval_predicate_fn=early_stopping)
# ...However, have in mind that |
|
@xiejw could you PTAL re: new 1.4 utilities. |
|
Take a look at this example: |
|
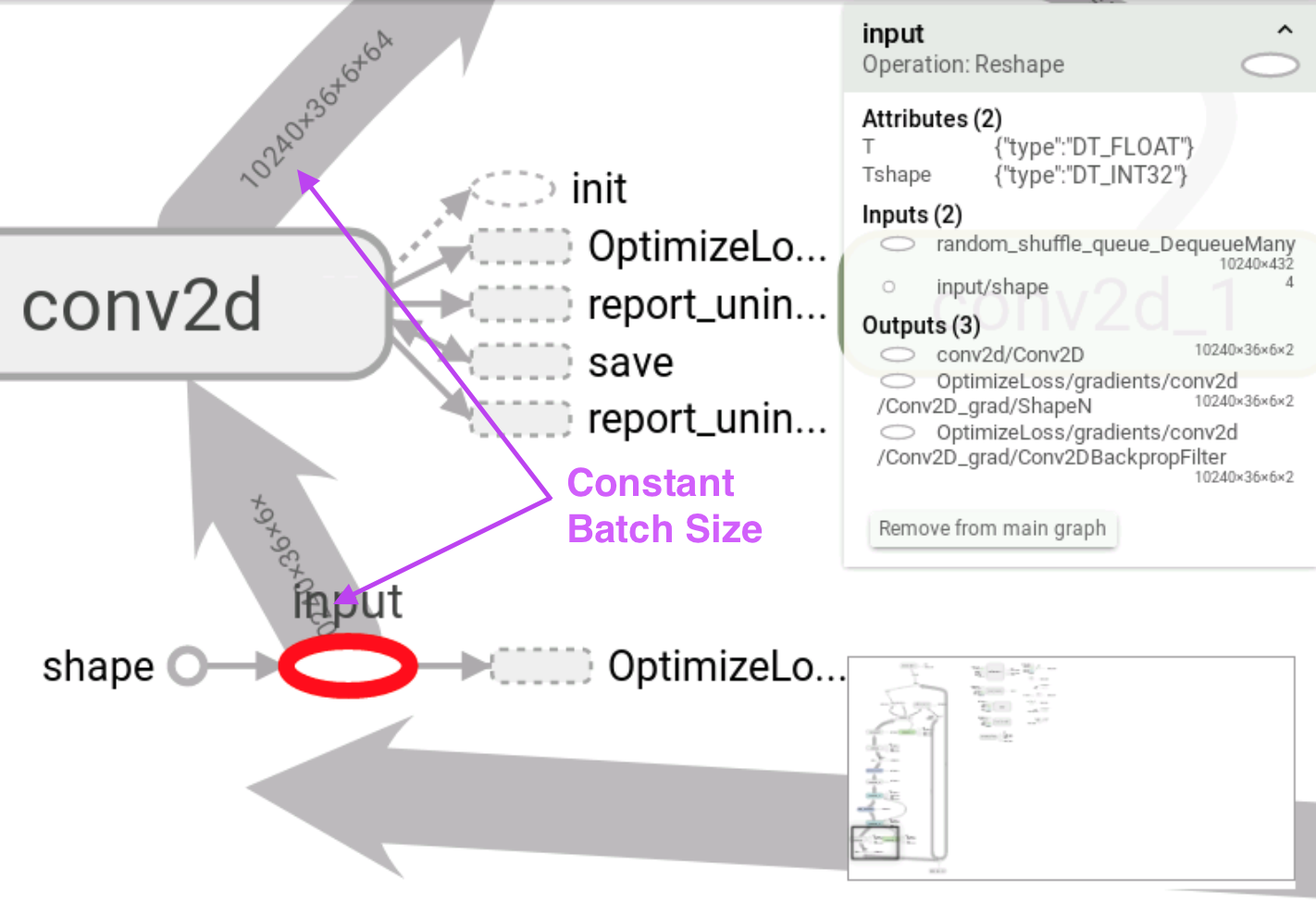
@agniszczotka @alyaxey Using Experiment works and enables me to run validation along with training. However, I've found that the batch size is probably encoded as a constant instead of a symbolic tensor for the input node even though it is coded as a reshape node with variable batch size (i.e, tf.reshape(features["x"], [-1, ...]). As a result, in the Android code, I have to allocate an array of similar size as the batch size to store the output (i.e, fetch()).
|
|
Any updates on this? |
Unfortunately, in TensorFlow 1.5.0 ValidationMonitor is not available ... |
|
@lelugom |
|
I've created a You can attach it as a hook whenever you run |
|
Is this still an issue ? |
|
Closing this out since I understand it to be resolved, but please let me know if I'm mistaken. Thanks! |
When I used the code snippet in the section "Customizing the Evaluation Metrics with MetricSpec" of the tutorial Logging and Monitoring Basics with tf.contrib.learn. the code snippet is
My tensorflow version is r1.0 . When I run my program, it print the following error:
I found that the class
tf.contrib.learn.metric_spec.MetricSpechas been renamed totf.contrib.learn.MetricSpec.The class
tf.contrib.learn.prediction_key.PredictionKeyalso has been renamed totf.contrib.learn.PredictionKey.The text was updated successfully, but these errors were encountered: