ReleaseNotes
This page keeps the most up-to-date release notes.
- IN DEVELOPMENT
- Jul 07 2019 - V4.1.0
- Oct 29 2018 - V4.0.0
- June 19 2018 - V3.05.02
- June 1 2017 - V3.05.01
- February 16 2017 - V3.05.00
- February 16 2016 - V3.04.01
- July 11 2015 - V3.04.00
- February 4 2014 - V3.03(rc1)
- October 23 2012 - V3.02.02
- October 21 2011 - V3.01
- September 30 2010 - V3.00
- June 30 2009 - V2.04
- April 22 2008 - V2.03
- April 21 2008 - V2.02
- August 30 2007 - V2.01
- July 18 2007 - V2.00
- May 15 2007 - V1.04
- February 03 2007 - V1.03
- October 04 2006 - V1.02
- September 07 2006 - V1.01
- June 17 2006 - V1.00

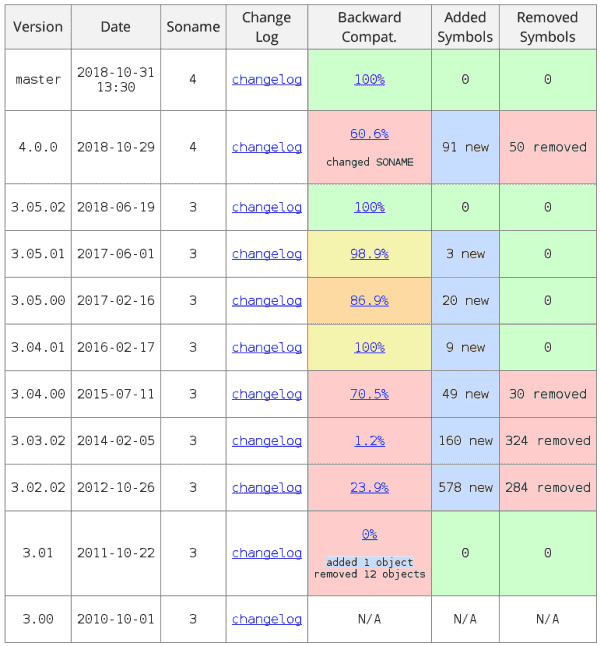
- Binary compatibility report for Tesseract: 4.0.0 vs 4.1.0 (maybe not updated for the latest code)
- Binary compatibility report for Tesseract: 3.05.02 vs 4.0.0
- master is using 5.0.0 versioning because of code modernization cause API compatibility issues with 4.x release
- Added the parameter
tessedit_do_invert, which can speed up tesseract execution, when set totrue. - Reorganized Tesseract's source tree. All public headers are now placed in the
include/tesseractdirectory.
- Backward compatible release with 4.0.0
- Added a new output option formatted in the ALTO standard. Command line usage:
tessaract imagename outputbase alto. This output is experimental and might be changed a bit before the next release. - Added new renders LSTMBox, WordStrBox to simplify training
- Added character boxes in hOCR output.
- Added Python training scripts (experimental) as alternative shell scripts.
- Fixed locale handling issue. libtesseract now works with any locale.
- Better support AVX / AVX2 / SSE.
- Disable OpenMP support by default (see e.g. #1171, #1081).
- Fix for bounding box problem.
- Implemented support for whitelist/blacklist in LSTM engine.
- Made user-words and user-patterns files work with lstm. #2328
- Improved CMake configuration.
- Code modernization and improvements.
- A lot of bug fixes...
-
New OCR engine
- Added a new OCR engine that uses neural network system based on LSTMs, with major accuracy gains.
- This includes new training tools for the LSTM OCR engine. A new model can be trained from scratch or by fine tuning an existing model.
- Added trained data that includes LSTM models to 123 languages.
- Added optional accelerated code paths for the LSTM recognizer:
- Using OpenMP
- Using SIMD: AVX2 / AVX / SSE4.1
- Added a new parameter
lstm_choice_modethat allows to include alternative symbol choices in the hOCR output.
-
Other OCR engines
- The pattern matching OCR engine that was the primary OCR engine in previous versions is still available in this version.
- Removed the 'Cube' OCR engine from the codebase. It was used for Hindi and for Arabic. The New LSTM engine performs much better, thus the Cube engine was no longer needed.
-
Updated build system
- Tesseract now uses semantic versioning.
- Added an option to compile Tesseract without the code of the legacy OCR engine.
-
Updated requirements
- For building Tesseract from source code, a compiler with good C++ 11 support is required. See here for a list of officially supported compilers.
- Tesseract now requires Leptonica 1.74.0 or a higher version.
- Update minimum required autoconf version to 2.63.
- Training tools dependencies - Update minimum required versions: ICU 52.1, Pango 1.22.0.
-
Bug fixes and enhancements
- Fixed many issues that triggered compiler warnings.
- Fixed many issues reported by Coverity Scan or LGTM.
- Fixes to trainingdata rendering.
- Fixed damage to binary images when processing PDFs.
- Don't trigger a deliberate segmentation fault for fatal errors in release code (Commit 5338a5a8d).
- Fixed some issues in OpenCL code. OpenCL now works for the legacy Tesseract OCR engine, but does not improve the performance. It is not implemented for the LSTM OCR engine.
- Improved multi-page TIFF handling.
- Improvements to PDF rendering.
- Added version information and improved help texts to the training tools.
- Added faster version of log2().
- Documented in
tesseractman page the option to use an input text file which contains lists of images. - Made 'osd' the default traineddata when psm 0 is requested (currently this feature is only implemented in the command line interface, but not in the API).
- Removed
tessedit_pageseg_mode 1from hocr, pdf, and tsv config files. The user should explicitly use--psm 1if that is desired (Commit ecfee53ba). - The list of available languages and scripts is now sorted alphabetically.
- Parameter
unlv_tilde_crunchingchanged tofalse, because of default values cause issues (#948, #1449) in cases of unlv output in Tesseract 4. - Added parameter:
min_characters_to_try.
-
Misc.
- Reorganized Tesseract's source tree. Most sources are now below the
srcdirectory. - Added unit tests to the main repo. The unit tests require Git submodules and the code for training.
- Removed obsolete code.
- Reorganized Tesseract's source tree. Most sources are now below the
-
Important notes
- The new LSTM engine still does not support all features from the old legacy engine (see missing features).
- Tesseract now requires the so called "C" locale. This has mainly implications when Tesseract is used as a library from programming languages like Java or Python. The locale stands for several settings which depend on a language (or language variant) or country. Some of those setting determine the classification of symbols (for example "Is this character a blank (space) character?") or the way how numbers are printed (for example "3.141" or "3,141"). The current Tesseract code implicitly expects some fixed settings, otherwise it fails. Therefore the code fails right at the beginning with an assertion if it cannot be sure that the settings work. This is not a problem with C or C++ programs which by default get a "C" locale with the right settings. All other use cases must currently make sure that they switch to the "C" locale before running Tesseract code. Fixed in version 4.1.0.
This release fixed a few bugs, backported from 4.0.0.
- Added an option to render only the invisible text layer (without the full input image) for PDF output.
- Made some optimizations to GenericVector.
- Fixed --disable-graphics build.
- Fixed --enable-visibility build (including training tools).
- Fixed reading config files with '\r\n' as line break.
- OpenCL - Fixed some issues. Removed a large part of the code.
- Removed dead code.
- Tesseract now requires Leptonica 1.74.0 or a higher version.
- Made some fine tuning to the hOCR output.
- Added TSV as another optional output format.
- Fixed ABI break introduced in 3.04.00 with the AnalyseLayout() method.
- text2image tool - Enable all OpenType ligatures available in a font. This feature requires Pango 1.38 or newer.
- Training tools - Replaced asserts with tprintf() and exit(1).
- Fixed Cygwin compatibility.
- Improved multipage TIFF processing.
- Improved embedded PDF font (pdf.ttf).
- Enable selection of OCR engine mode from the command line.
- Changed tesseract command line parameter '-psm' to '--psm'.
- Added new C API for orientation and script detection, removed the old one.
- Increased minimum autoconf version to 2.59.
- Removed dead code.
- Fixed many compiler warnings.
- Fixed memory and resource leaks.
- Fixed some issues with the 'Cube' OCR engine.
- Fixed some OpenCL issues.
- Added option to build Tesseract with CMake build system.
- Implemented CPPAN support for easy Windows building.
- Added OSD renderer for psm 0. Works for single page and multi-page images.
- Improved tesstrain.sh script.
- Simplify build and run of ScrollView.
- Improved PDF output for OS X Preview utility.
- INCOMPATIBLE fix to hOCR line height information - commit 134ebc3.
- Added option to build Tesseract without Cube OCR engine (-DNO_CUBE_BUILD).
- The project uses Travis CI and AppVeyor Continuous Integration services.
- Tesseract development is now done with Git and hosted at github.com (Previously we used Subversion as a VCS and code.google.com for hosting).
- Tesseract now requires Leptonica 1.71 or a higher version.
- Removed official support for VS2008.
- Major updates to training system as a result of extensive testing on 100 languages.
- New training data for over 100 languages. Added support for 39 additional scripts/languages: amh, asm, aze_cyrl, bod, bos, ceb, cym, dzo, fas, gle, guj, hat, iku, jav, kat, kat_old, kaz, khm, kir, kur, lao, lat, mar, mya, nep, ori, pan, pus, san, sin, srp_latn, syr, tgk, tir, uig, urd, uzb, uzb_cyrl, yid.
- Added a backup adaptive classifier to take over from primary when it fills on a large document.
- Improved performance with PIC compilation option.
- Significant change to invisible font system in PDF output to improve correctness and compatibility with external programs, particularly ghostscript.
- Improved font identification.
- Major change to improve layout analysis for heavily diacritic languages: Thai, Vietnamese, Kannada, Telugu etc.
- Fixed problems with shifted baselines so recognition can recover from layout analysis errors.
- Major refactor to improve speed on difficult images, especially when running a heap checker.
- Moved params from global in page layout to tesseractclass.
- Improved single column layout analysis.
- Allow OCR output to multiple formats using tesseract command line executable.
- Fixed issues with mixed eng+ara scripts.
- Improved script consistency in numbers.
- Major refactor of control.cpp to enable line recognition.
- Added tesstrain.sh - a master training script.
- Added ability to text2image training tool to just list available fonts.
- Added ability to text2image to underline words.
- Improved efficiency of image processing for PDF output.
- Added parameter description for each parameter listed with 'print-parameters' command line option.
- Added font info to hOCR output.
- Enabled streaming input and output of multi-page documents.
- Many bug fixes.
- Tesseract now requires Leptonica 1.70 or a higher version.
- Added OpenCL support (experimental).
- Added new training tool text2image to generate box/tif file pairs from text and truetype fonts.
- Added support for PDF output with searchable text.
- Removed entire IMAGE class and all code in image directory.
- Tesseract executable: support for output to stdout; limited support for one page images from stdin (especially on Windows)
- Added Renderer to API to allow document-level processing and output of document formats, like hOCR, PDF.
- Major refactor of word-level recognition, beam search, eliminating dead code.
- Refactored classifier to make it easier to add new ones.
- Generalized feature extractor to allow feature extraction from greyscale.
- Improved sub/superscript treatment.
- Improved baseline fit.
- Added set_unicharset_properties to training tools.
- Many bug fixes.
- More training source data included.
- Tesseract now requires Leptonica 1.69 or a higher version.
- Moved ResultIterator/PageIterator to ccmain.
- Added Right-to-left/Bidi capability in the output iterators for Hebrew/Arabic.
- Added paragraph detection in layout analysis/post OCR.
- Fixed inconsistent xheight during training and over-chopping.
- Added simultaneous multi-language capability.
- Refactored top-level word recognition module.
- Added experimental equation detector.
- Improved handling of resolution from input images.
- Blamer module added for error analysis.
- Cleaned up externally used namespace by removing includes from baseapi.h.
- Removed dead memory management code.
- Tidied up constraints on control parameters.
- Added support for ShapeTable in classifier and training.
- Refactored class pruner.
- Fixed training leaks and randomness.
- Major improvements to layout analysis for better image detection, diacritic detection, better textline finding, better tabstop finding.
- Improved line detection and removal.
- Added fixed pitch chopper for CJK.
- Added UNICHARSET to WERD_CHOICE to make mult-language handling easier.
- Fixed problems with internally scaled images.
- Added page and bbox to string in tr files to identify source of training data better.
- Fixes to Hindi Shiroreka splitter.
- Added word bigram correction.
- Reduced stack memory consumption and eliminated some ugly typedefs.
- Added new uniform classifier API.
- Added new training error counter.
- Fixed endian bug in dawg reader.
- C API (thanks to Tobias Müller)
- New solution for VS 2008 (thanks to Tom Powers)
- Fixed the way in which the chopper finds chops and messes with the outline while it does so.
- Many other fixes.
- Thread-safety! Moved all critical globals and statics to members of the appropriate class. Tesseract is now thread-safe (multiple instances can be used in parallel in multiple threads.) with the minor exception that some control parameters are still global and affect all threads.
- Added
Cube, a new experimental recognizer for Arabic and Hindi. Cube can also be used in combination with normal Tesseract for a few other languages with an small improvement in accuracy at the cost of much lower speed. There is no training module for Cube. -
OcrEngineModeinInitreplacesAccuracyVSpeedto control cube. - Greatly improved segmentation search with consequent accuracy and speed improvements, especially for Chinese.
- Added
PageIteratorandResultIteratoras cleaner ways to get the full results out of Tesseract, that are not currently provided by any of theTessBaseAPI::Get*methods. All other methods, such as theETEXT_STRUCTin particular are deprecated and will be deleted in the future. - ApplyBoxes totally rewritten to make training easier. It can now cope with touching/overlapping training characters, and a new boxfile format allows word boxes instead of character boxes, BUT to use that you have to have already boostrapped the language with character boxes. "Cyclic dependency" on traineddata.
- Auto orientation and script detection added to page layout analysis.
- Deleted lots of dead code.
- Fixxht module replaced with scalable data-driven module.
- Output font characteristics accuracy improved.
- Removed the double conversion at each classification.
- Upgraded oldest structs to be classes and deprecated PBLOB.
- Removed non-deterministic baseline fit.
- Added fixed length dawgs for Chinese.
- Handling of vertical text improved.
- Handling of leader dots improved.
- Table detection greatly improved.
- Fixed a couple of memory leaks.
- Fixed font labels on output text. (Not perfect, but a lot better than before.)
- Cleanup and more bug fixes
- Special treatments for Hindi.
- Support for build in VS2010 with Microsoft Windows SDK for Windows 7 (thanks to Michael Lutz)
- Preparations for thread safety:
- Changed TessBaseAPI methods to be non-static
- Created a class hierarchy for the directories to hold instance data, and began moving code into the classes.
- Moved thresholding code to a separate class.
- Added major new page layout analysis module.
- Added hOCR output.
- Added Leptonica as main image I/O and handling. Currently optional, but in future releases linking with Leptonica will be mandatory.
- Ambiguity table rewritten to allow definite replacements in place of fix_quotes.
- Added TessdataManager to combine data files into a single file.
- Some dead code deleted.
- VC++6 no longer supported. It can't cope with the use of templates.
- Many more languages added.
- Doxygenation of most of the function header comments.
- Integrated patches for portability and to remove some of the "access" macros.
- Removed dependence on lua from the viewer making it a lot faster. Also the viewer now compiles and works (on Linux.) Also works on windows via a pre-built ScrollView.jar.
- Fixed the following issues: 1, 63, 67, 71, 76, 79, 81, 82, 84, 106, 108, 111, 112, 128, 129, 130, 133, 135, 142, 143, 145, 146, 147, 153, 154, 160, 165, 169, 170, 175, 177, 187, 192, 195, 199, 201, 205, 209.
- This is the last version to support VC++6!
- This may also be the last version to compile without Leptonica!
- Windows version now outputs to stderr by default, fixing a lot of the problems with lack of visible meaningful error messages.
2.02 was unrunnable, due to a last-minute "simple" change.
2.03 fixes the problem.
It also adds an include check for leptonica
to make it more usable.
- Improvements to clustering, training and classifier.
- Major internationalization improvements for large-character-set languages, eg Kannada.
- Removed some compiler warnings.
- Added multipage tiff support for training and running.
- Updated graphics output to talk to new java-based viewer.
- Added ability to save n-best lists.
- Added Leptonica support for more file types.
- Improved Init/End to make them safe.
- Reduced memory use of dictionaries.
- Added some new APIs to TessBaseAPI.
- Fixed namespace collisions with jpeg library (INT32).
- Portability fixes for Windows for new code.
- Updates to autoconf system for new code.
(See also release notes for 2.00 below for usage information)
No major functionality change. Just a bunch of bug fixes.
- Fixed UTF8 input problems with box file reader.
- Fixed various infinite loops and crashes in dawg code.
- Removed include of config_auto.h from host.h.
- Added automatic wctype encoding to unicharset_extractor.
- Fixed dawg table too full error.
- Removed svn files from tarball.
- Added new functions to tessdll.
- Increased maximum utf8 string in a classification result to 8.
- Added new functionality to TessBaseAPI for Ocropus.
No new data files for the original 6 languages. Use the files from v2.00. There are new data files for German Fraktur (deu-f) and Brazillian Portuguese (por).
STOP PRESS There is a minor bug in unicharset_extractor. Since this is only applicable to training, the main tarball is fine unless you need to run training, in which case, overwrite your unicharset_extractor.cpp and unicharset_extractor.exe with the ones in tesseract-2.01.patch1.tar.gz.
(See also release notes for 1.04 below for additional usage information)
First release of the International version. This version recognizes the following languages:
- English - eng
- French - fra
- Italian - ita
- German - deu
- Spanish - spa
- Dutch - nld
The language codes follow ISO 639-2. The default language is English. To recognize another language:
tesseract inputimage outputbase -l langcode
To train on a new language, see TrainingTesseract2. More languages will be appearing over time.
List of changes in this release:
- Converted internal character handling to UTF8.
- Trained with 6 languages.
- Added unicharset_extractor, wordlist2dawg.
- Added boxfile creation mode.
- Added UNLV regression test capability.
- Fixed problems with copyright and registered symbols.
- Fixed extern "C" declarations problem.
- Made some improvements to consistency of accuracy across platforms.
- Added VC++ express support.
Warning: Tesseract 2.00 has undergone more compatibility testing than any previous version. There have even been fixes to make the accuracy more consistent across platforms. Having said that, there have been many changes to the code, and portability may have been broken, so 64 bit and Mac platforms may not work or even build as well as before.
Tesseract development is now done with Subversion and hosted at code.google.com (Previously we used CVS as a VCS and sourceforge.net for hosting).
Windows users only
Added a dll interface for windows. Thanks to Glen at Jetsoft for contributing this. To use the dll, include tessdll.h, import tessdll.lib and put tessdll.dll somewhere where the system can find it. There is also a small dlltest program to test the dll. Run with:
dlltest phototest.tif phototest.txt
It will output the text from phototest.tif with bounding box information.
New for Windows
The distribution now includes tesseract.exe and tessdll.dll which might work out of the box! There are no guarantees as you need VC++6 versions of MFC and CRT (at least) for it to work. (Batteries not included, and certainly no installshield.)
Important note for anyone building with make: i.e. anyone except devstudio users
This release includes new standardization for the data directory. To enable Tesseract to find its data files, you must either:
./configure
make
make install
to move the data files to the standard place, or:
export TESSDATA_PREFIX="directory in which your tessdata resides/"
(or equivalent) in your .profile or whatever or setenv to set the environment variable. Note that the directory must end in a /
HAVING tesseract and tessdata IN THE SAME DIRECTORY DOES NOT WORK ANY MORE.
All users
Fixed a bunch of name collisions - mostly with STL.
Made some preliminary changes for unicode compatibility. Includes a new data
file (unicharset) and renaming of the other data files to eng. to support
different languages.
There are also several other minor bug fixes and portability improvements
for 64 bit, the latest visual studio compiler etc.
Thanks to all who have contributed these fixes.
NOTE: This is likely to be the last English-only release! Apologies in advance to non-windows users for bloating the distribution with windows executables. This will probably get fixed in the next release with the multi-language capability, since that will also bloat the distribution.
- Added mftraining and cntraining.
- Added baseapi with adaptive thresholding for grey and color.
- Fixed many memory leaks.
- Fixed several bugs including lack of use of adaptive classifier.
- Added ifdefs to eliminate graphics code and add embedded platform support.
- Incorporated several patches, including 64-bit builds, Mac builds.
- Minor accuracy improvements.
- Removed dependency on Aspirin.
- Fixed a few missing Apache license headers.
- Removed $log.
- Added mfcpch.cpp and getopt.cpp for VC++.
- Fixed problem with greyscale images and no libtiff.
- Stopped debug window from being used for the usage output.
- Fixed load of inttemp for big-endian architectures.
- Fixed some Mac compilation issues.
First open source version of Tesseract!
Hosted at sourceforge.net. CVS is used for version control.