In this fork of pycaskdb a basic Bitcask storage engine is designed and developed. Check my blogpost for more details on this design.
CaskDB is a disk-based, embedded, persistent, key-value store based on the Riak's bitcask paper, written in Python. It is more focused on the educational capabilities than using it in production. The file format is platform, machine, and programming language independent. Say, the database file created from Python on macOS should be compatible with Rust on Windows.
What is done:
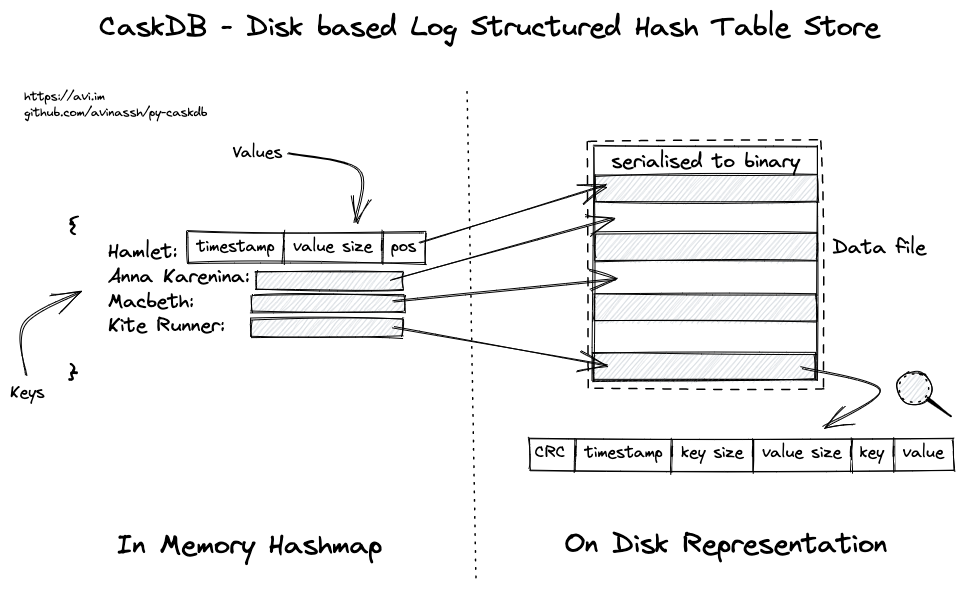
- Implemented the fixed-sized header, which can encode timestamp (uint, 4 bytes), key size (uint, 4 bytes), value size (uint, 4 bytes) together
- Implemented the key, value serialisers, and pass the tests from
test_format.py - Figured out how to store the data on disk and the row pointer in the memory
- Implemented the get/set operations. Tests for the same are in
test_disk_store.py - Implemented compaction
- Added a JSON registry for directory with datafiles
- Unbundled to different components - keydir, registry, descriptor table
- Heavily refactored tests
- Moved to Poetry and Python 3.11
- Implemented range scans
- Introduced property-based tests with Hypothesis to ensure correctness of implentation
- Low latency for reads and writes
- High throughput
- Easy to back up / restore
- Simple and easy to understand
- Store data much larger than the RAM
Most of the following limitations are of CaskDB. However, there are some due to design constraints by the Bitcask paper.
- Single file stores all data, and deleted keys still take up the space
- CaskDB does not offer range scans
- CaskDB requires keeping all the keys in the internal memory. With a lot of keys, RAM usage will be high
- Slow startup time since it needs to load all the keys in memory
poetry install
poetry run make test lint
The MIT license. Please check LICENSE for more details.