



Note
This is one of 199 standalone projects, maintained as part of the @thi.ng/umbrella monorepo and anti-framework.
🚀 Please help me to work full-time on these projects by sponsoring me on GitHub. Thank you! ❤️
- About
- Status
- Support packages
- Installation
- Dependencies
- Usage examples
- API
- Core vocabulary
- Authors
- License
Pointfree functional composition via lightweight (~3KB gzipped), stack-based embedded DSL.
This module implements the language's core components in vanilla ES6 and is perfectly usable like that. The related @thi.ng/pointfree-lang module defines an actual language with a powerful and more concise syntax around this module and might be better suited for some use cases.
Current features:
- words implemented as tiny vanilla JS functions (easily extensible)
- optimized pre-composition/compilation of custom user defined words (see word.ts)
- dual stack (main & stash/scratch space)
- nested execution environments (scopes)
- arbitrary stack values
- nested quotations (static or dynamically generated programs stored on stack)
- includes 100+ operators:
- conditionals
- looping constructs
- 20+ dataflow / quotation combinators (
dip,keep,bietc.) - array / tuple ops
- math, binary & logic ops
- currying quotations
- higher order combinators
- environment manipulation etc.
- stack comments & documentation for most ops/words
- over 330 test cases
For a great overview & history of this type of this type of programming, please see:
- Concatenative Programming: From Ivory to Metal (John Purdy's talk @ Stanford Computer Systems Colloquium)
- Concatenative.org Wiki
- Thinking Forth E-book
Originally, this project started out as precursor of the Charlie Forth VM/REPL (JS) and @thi.ng/synstack VM (C11), but has since been refactored to be more generally useful as environment for building data processing pipelines in a pointfree / concatenative programming style rather than acting as full-blown VM. Some words and concepts have been ported from Factor and Popr.
(details explained further below)
import * as pf from "@thi.ng/pointfree";
// define word to compute dot product of two vectors
const dotp = pf.word([pf.vmul, [pf.add], 0, pf.foldl]);
// another word to normalize a vector (uses `dotp`)
const normalize = pf.word([pf.dup, pf.dup, dotp, pf.sqrt, pf.vdiv]);
// `word(...)` creates a functional composition of given body
// each stack function accepts & returns a stack context tuple
// i.e. normalize = vdiv(sqrt(dotp(dup(dup(ctx)))));
// `unwrap` retrieves a value/section of the result stack
pf.unwrap(dotp([[ [1, 2, 3], [4, 5, 6] ]]))
// 32
pf.unwrap(normalize([[ [10, -10, 0] ]]))
// [ 0.7071067811865475, -0.7071067811865475, 0 ]The same in standard imperative style:
function dotp(a, b) {
let sum = 0;
for(let i = 0; i < a.length; i++) {
sum += a[i] * b[i];
}
return sum;
}
function normalize(v) {
const mag = Math.sqrt(dotp(v, v));
for(let i = 0; i < v.length; i++) {
v[i] /= mag;
}
return v;
}
dotp([1,2,3], [4,5,6]);
// 32
normalize([10, -10, 0])
// [ 0.7071067811865475, -0.7071067811865475, 0 ]In terms of composing processing pipelines, this approach is somewhat related to transducers, however the pointfree method and use of a stack as sole communication medium between different sub-processes can be more flexible, since each function ("word" in Concatenative-programming-speak) can consume or produce any number of intermediate values from/on the stack. Furthermore, on-stack quotations and dataflow combinators can be used for dynamic programming approaches and conditionals can be used to cause non-linear control flow.
STABLE - used in production
Search or submit any issues for this package
- @thi.ng/pointfree-lang - Forth style syntax layer/compiler & CLI for the @thi.ng/pointfree DSL
yarn add @thi.ng/pointfreeESM import:
import * as pf from "@thi.ng/pointfree";Browser ESM import:
<script type="module" src="https://esm.run/@thi.ng/pointfree"></script>For Node.js REPL:
const pf = await import("@thi.ng/pointfree");Package sizes (brotli'd, pre-treeshake): ESM: 3.23 KB
Note: @thi.ng/api is in most cases a type-only import (not used at runtime)
Two projects in this repo's /examples directory are using this package:
| Screenshot | Description | Live demo | Source |
|---|---|---|---|
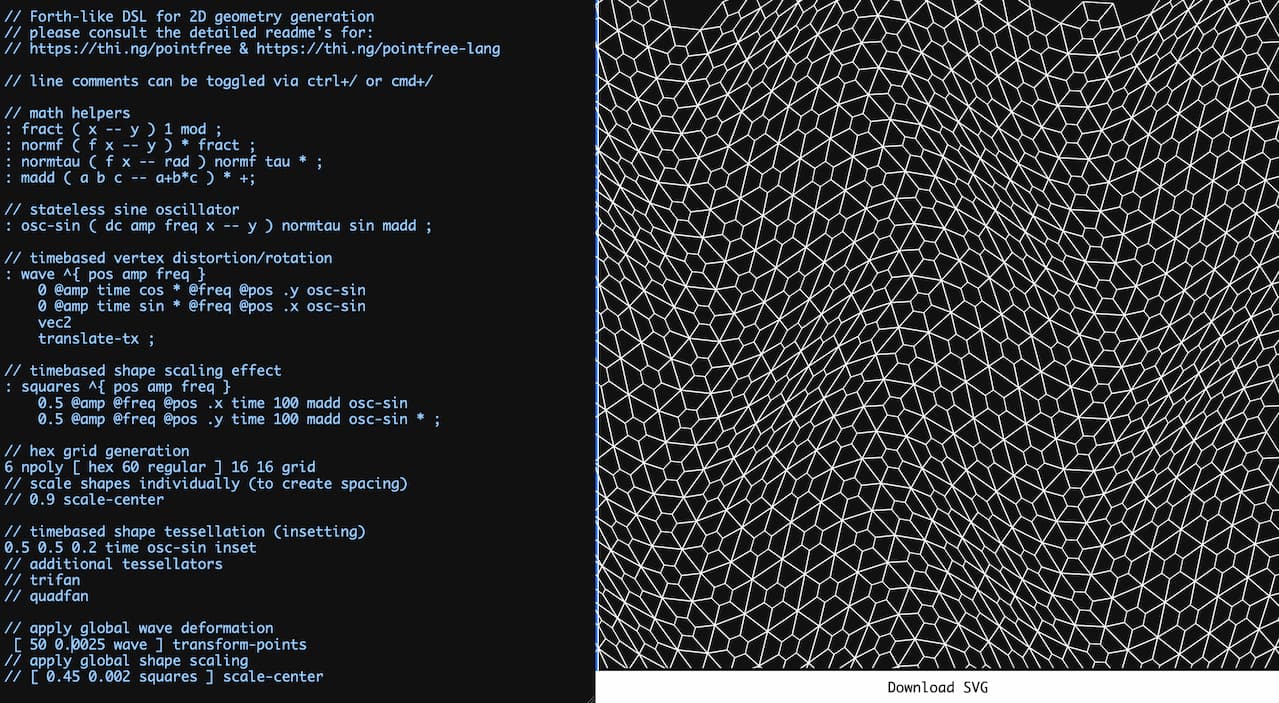 |
Live coding playground for 2D geometry generation using @thi.ng/pointfree-lang | Demo | Source |
 |
Generate SVG using pointfree DSL | Source |
The main type aliases used by this DSL are:
type Stack = any[]
type StackEnv = any
type StackFn = (ctx: StackContext) => StackContext
type StackProgram = any[]
type StackProc = StackFn | StackProgram
type StackContext = [Stack, Stack, StackEnv?]The StackContext tuple consists of:
- d-stack - main data stack
- r-stack - "return stack" (in Forth speak), mainly used as scratch space for internal data
- env - arbitrary data object defining the current environment
Each program function ("word") accepts a StackContext tuple and can
arbitrarily modify both its stacks and/or environment and must return
the updated context (usually the same instance as passed in, but could
also produce a new one). Any side effects are allowed.
A StackProgram is an array of stack functions and non-function values.
The latter are replaced by calls to push which pushes the given value
on the stack as is. Therefore, a stack program like: [1, 2, pf.add]
compiles to:
import * as pf from "@thi.ng/pointfree";
pf.add(pf.push(2)(pf.push(1)(/* <initial context> */)))Most concatenative languages use stack effect comments as the standard approach to document the effect a word has on the stack structure.
( x y -- x )The items in front of the -- describe the relevant state of the stack
before the execution of a word (the args expected/consumed by the word).
The part after the -- is the state of the stack after execution (the
results). If no args are given on the LHS, the word consumes no args. If
no args are given on the RHS, no result values are produced.
(Note: TOS = Top Of Stack)
run(program: StackProgram, stack?: StackContext)
The main user function of this library. It takes a stack program and
optional StackContext with initial stacks and environment (an
arbitrary object). It executes the program and returns the updated
context.
Alternatively, we can use runU() to return an unwrapped value or
section of the result stack. This is merely syntax sugar and we use this
for some of the examples below.
import * as pf from "@thi.ng/pointfree";
// calculate (1 + 2 + 3) * 10
pf.run(
// a pointfree stack program w/ stack effects
[
10, 1, 2, 3, // initial data values
pf.add, // ( 10 1 2 3 -- 10 1 5 )
pf.add, // ( 10 1 5 -- 10 6 )
pf.mul, // ( 10 6 -- 60 )
]
)
// [ [ 60 ], [], {}]
// this is the same as this functional composition:
pf.mul(pf.add(pf.add(pf.ctx([10, 1, 2, 3]))))
// [ [ 60 ], [], {}]Custom words can be defined via the word() and wordU() functions.
The latter uses runU() to execute the word and returns unwrapped
value(s) from result context.
Important: Unwrapped words cannot be used as part of larger stack programs. Their use case is purely standalone application.
import * as pf from "@thi.ng/pointfree";
// define new word to compute multiply-add:
// ( x y z -- x*y+z )
const madd = pf.word([pf.invrot, pf.mul, pf.add]);
// compute 3 * 5 + 10
madd([[3, 5, 10]]);
// [ [ 25 ] ]
// unwrapped version
const maddU = pf.wordU([madd]);
// compute 3 * 5 + 10
maddU([3, 5, 10]);
// 25Factoring is a crucial aspect of developing programs in concatenative languages. The general idea is to decompose a larger solution into smaller re-usable units, words, quotations. These often extremely small words can be much easier tested and reused.
import * as pf from "@thi.ng/pointfree";
// compute square of x
// ( x -- x*x )
const pow2 = pf.word([pf.dup, pf.mul]);
// test word with given (partial) stack context
pf.unwrap(pow2([[-10]]))
// 100
// compute magnitude of 2d vector (using `pow2`)
// ( x y -- mag )
const mag2 = pf.wordU([
// `bia` is a combinator,
// which applies quotation to both inputs
[pow2], pf.bia, // ( x*x y*y )
pf.add, // ( x*x+y*y )
pf.sqrt // ( sqrt(x*x+y*y) )
]);
mag2([[-10, 10]])
// 14.142135623730951A StackProgram residing as data on the stack is called a quotation.
Quotations enable a form of dynamic meta programming and are used by
several built-in words and combinators. Quoations are used like lambdas
/ anonymous functions in traditional functional programming, are
executed in the current environment, but needn't be complete units of
execution. Quotations can be nested, composed and are executed via
exec.
This example uses a quoted form of the above pow2 word:
import * as pf from "@thi.ng/pointfree";
pf.runU(
[
// push quotation on stack
[pf.dup, pf.mul],
// execute
pf.exec,
],
// initial (partial) stack context
[[10]]
);
// 100Quoations can be used to define (or dynamically construct) JS function calls. For that a quotation needs to take the form of an S-expression, i.e. the first element of the quotation is the actual function to be called and all other values in the quotation are passed as arguments. The result of the function call is placed back on the stack.
import * as pf from "@thi.ng/pointfree";
pf.runU(
[
[(a,b) => a + b, 1, 2],
pf.execjs
]
);
// 3Since quoatations are just arrays, we can treat them as data, i.e. the functional composition of two quotations is the same as concatenating two arrays:
import * as pf from "@thi.ng/pointfree";
const add10 = [10, pf.add];
const mul10 = [10, pf.mul];
// `cat` is used to concatenate arrays
// the result quotation computes: `(x+10)*10`
pf.runU([ add10, mul10, pf.cat, pf.exec ], [[1]])
// 110As with partial
application in
functional programming, we can "curry" quotations and use pushl to
prepend (or pushr to append) arguments to a given quotation (array).
Also see the section about combinators for more
advanced options.
import * as pf from "@thi.ng/pointfree";
// build & execute curried quotation
pf.run([10, [pf.add], pf.pushl, pf.exec], [[13]]);
// 23Furthermore, the ES6 spread operator can be used to dissolve a quotation in a larger word/program (i.e. as a form of inlining code).
import * as pf from "@thi.ng/pointfree";
// a quotation is just an array of values/words
// this function is a quotation generator
const tupleQ = (n) => [n, pf.collect];
// define another quotation which takes an id and
// when executed stores TOS under `id` key in current environment
const storeQ = (id) => [id, pf.store]
// define word which inlines both `tupleQ` and `storeQ`
const storeID = (id, size) => pf.word([...tupleQ(size), ...storeQ(id)]);
// transform stack into tuples, stored in env
// `runE()` only returns the result environment
pf.runE(
[storeID("a", 2), storeID("b", 3)],
// (`ctx()` creates a complete StackContext tuple)
pf.ctx([1, 2, 3, 4, 5])
);
// { a: [ 4, 5 ], b: [ 1, 2, 3 ] }Combinators are higher-order constructs, enabling powerful data processing patterns, e.g. applying multiple quotations to single or multiple values, preserving/excluding stack values during processing etc.
Most of these combinators have been ported from the Factor language.
Btw. the number suffixes indicate the number of values or quotations each combinator deals with... not all versions are shown here.
dip / dip2 / dip3 / dip4
Removes one or more stack values before applying quotation, then
restores them again after. Most other combinators are internally built
on dip and/or keep.
import * as pf from "@thi.ng/pointfree";
// remove `20` before executing quot, then restores after
// with the effect of apply qout to 2nd topmost value (here: 10)
pf.run([10, 20, [pf.inc], pf.dip])[0]
// [11, 20]
// dip2 removes & restores 2 values
pf.run([1, 2, 3, [10, pf.add], pf.dip2])[0]
// [11, 2, 3]keep / keep2 / keep3
Calls a quotation with a value on the d-stack, restoring the value after quotation finished.
import * as pf from "@thi.ng/pointfree";
// here `add` would normally consume two stack values
// but `keep2` restores them again after the quot has run
pf.run([1, 2, [pf.add], pf.keep2])[0]
// [3, 1, 2]bi/bi2/bi3tri/tri2/tri3
bi takes one value and two quotations. Applies first quot to the
value, then applies second quot to the same value.
import * as pf from "@thi.ng/pointfree";
pf.run([2, [10, pf.add], [10, pf.mul], pf.bi])[0]
// [12, 20]
// `bi3` takes 3 stack values and 2 quots (hence "bi")
pf.run([2, 10, 100, [pf.add, pf.add], [pf.mul, pf.mul], pf.bi3])[0]
// [112, 2000]tri takes 3 quotations, else same as bi:
import * as pf from "@thi.ng/pointfree";
pf.run([10, [pf.dec], [pf.dup, pf.mul], [pf.inc], pf.tri])[0]
// [9, 100, 11]bis/bis2tris/tris2
bis applies first quot p to x, then applies 2nd quot q to y.
( x y p q -- px qy )
import * as pf from "@thi.ng/pointfree";
pf.run([10, 20, [pf.inc], [pf.dec], pf.bis])[0]
// [11, 19]
// bis2 expects quotations to take 2 args
// computes: 10+20 and 30-40
pf.run([10, 20, 30, 40, [pf.add], [pf.sub], pf.bis2])[0]
// [30, -10]bia/bia2tria/tria2
Applies the quotation q to x, then to y.
( x y q -- qx qy )
import * as pf from "@thi.ng/pointfree";
pf.run([10, 20, [pf.inc], pf.bia])[0]
// [11, 21]
// tria2 takes 6 values and applies quot 3x pairwise
// i.e. 10+20, 30+40, 50+60
pf.run([10, 20, 30, 40, 50, 60, [pf.add], pf.tria2])[0]
// [30, 70, 110]See tests for more examples...
The DSL includes several array transforming words and constructs, incl.
array/vector math ops, splitting, deconstructing, push/pull (both
LHS/RHS) and the mapl & mapll words, both of which act as
generalization for map, filter, mapcat and reduce. The only
difference between mapl and mapll is that the former does not
produce a result array (only flat results pushed on stack), whereas
mapll always produces a new array.
mapl takes an array and a quotation. Loops over array, pushes each
value on the stack and applies quotation for each.
import * as pf from "@thi.ng/pointfree";
// multiply each array item * 10
pf.runU([[1, 2, 3, 4], [10, pf.mul], pf.mapll]);
// [ 10, 20, 30, 40 ]
// same packaged as standalone function
const map_mul10 = pf.word([[10, pf.mul], pf.mapll, pf.unwrap]);
map_mul10([[[1, 2, 3, 4]]]);
// [ 10, 20, 30, 40 ]
// the above case can also be solved more easily via vector math words
// multiply vector * scalar
pf.runU([[1, 2, 3, 4], 10, pf.vmul]);
// [ 10, 20, 30, 40 ]
// multiply vector * vector
pf.runU([[1, 2, 3, 4], [10, 20, 30, 40], pf.vmul]);
// [ 10, 40, 90, 160 ]
// drop even numbers, duplicate odd ones
// here using nested quotations (`condq` is explained further below)
pf.runU([[1, 2, 3, 4], [pf.dup, pf.even, [pf.drop], [pf.dup], pf.condq], pf.mapll])
// [ 1, 1, 3, 3 ]
// reduction example (using `mapl`)
// the `0` is the initial reduction result
pf.runU([0, [1, 2, 3, 4], [pf.add], pf.mapl])
// 10
// using `foldl` allows a different (better) argument order
// for reduction purposes (uses `mapl` internally)
// ( arr q init -- reduction )
pf.runU([[1, 2, 3, 4], [pf.add], 0, pf.foldl])
// 10bindkeys takes an array of keys and target object, then pops & binds
deeper stack values to their respective keys in object. Pushes result
object back on stack at the end. Throws error if there're less remaining
stack values than keys in given array.
import * as pf from "@thi.ng/pointfree";
pf.runU([1, 2, 3, ["a","b","c"], {}, pf.bindkeys])
// { c: 3, b: 2, a: 1 }import * as pf from "@thi.ng/pointfree";
// helper word to extract a 8bit range from a 32bit int
// `x` is the orig number, `s` bit shift amount
// ( x s -- x byte )
const extractByte = pf.word([
pf.over, // ( x s x )
pf.swap, // ( x x s )
pf.lsru, // ( x x>>>s )
0xff, // ( x x>>>s 0xff )
pf.bitand // ( x (x>>>s)&0xff )
]);
// decompose a number into 4 bytes
// the 1st array defines the bitshift offsets for each byte
// ( x -- a b c d )
const splitBytes = pf.word([[24, 16, 8, 0], [extractByte, pf.swap], pf.mapl, pf.drop]);
// decompose the number 0xdecafbad into 4 bytes
splitBytes([[0xdecafbad]]);
// [ [ 222, 202, 251, 173 ] ]
// in hex: [ [ 0xde, 0xca, 0xfb, 0xad ] ]See cond documentation further below...
import * as pf from "@thi.ng/pointfree";
// negate TOS item ONLY if negative, else do nothing
const abs = pf.wordU([pf.dup, pf.isneg, pf.cond(pf.neg)]);
// test w/ negative inputs
abs([[-42]])
// 42
// test w/ positive inputs
abs([42])
// 42import * as pf from "@thi.ng/pointfree";
// `cases()` is similar to JS `switch() { case ... }`
const classify = (x) =>
pf.unwrap(
pf.cases({
0: ["zero"],
1: ["one"],
default: [
pf.dup,
pf.ispos,
pf.cond(["many"], ["invalid"])
]
})([[x]]));
classify(0);
// "zero"
classify(1);
// "one"
classify(100);
// "many"
classify(-1);
// "invalid"loop takes two quotations (a test and a body). Executes body as long
as test produces a truthy result. There's also loopq which reads its
arguments (same as loop) from the stack.
import * as pf from "@thi.ng/pointfree";
// print countdown from 3
pf.run(
[
// test
[pf.dup, pf.ispos], // ( x -- x bool )
// loop body
["counter: ", pf.over, pf.add, pf.print, pf.dec], // ( x -- x-1 )
pf.loopq
],
// initial stack context
[[3]]
);
// counter: 3
// counter: 2
// counter: 1
// [ [ 0 ] ]Alternatively, the dotimes construct is more suitable for simple
counter based iterations. Like loopq it's not an higher-order word and
works with a body quotation, which is executed n times.
import * as pf from "@thi.ng/pointfree";
pf.run([3, ["counter: ", pf.swap, pf.add, pf.print], pf.dotimes])
// counter: 0
// counter: 1
// counter: 2loop/loopq and dotimes can be used to create more complex/custom
looping constructs:
import * as pf from "@thi.ng/pointfree";
// 2D range/grid loop
//
// (cols rows body -- ? )
//
// iterates over `rows` as outer and `cols` as inner loop
// executes body quotation with this stack effect
// ( x y -- )
const loop2 = pf.word([
pf.maptos(pf.word), // first compile body
pf.movdr, // move body move to r-stack
[
pf.over,
[pf.over, pf.cprd, pf.exec], pf.dotimes,
pf.drop,
], pf.dotimes,
pf.drop, // cleanup both stacks
pf.rdrop,
]);
pf.run([2, 3, [pf.vec2, pf.print], loop2]);
// [ 0, 0 ]
// [ 1, 0 ]
// [ 0, 1 ]
// [ 1, 1 ]
// [ 0, 2 ]
// [ 1, 2 ]
// [ [], [], {} ]
// To keep/collect the grid coordinates for future use
// use `vec2` and `invrot` to rotate them 2 places down the stack
// the last 2 words `dsp, collect` are used to group
// all stack items into a single tuple
pf.runU([2, 3, [pf.vec2, pf.invrot], loop2, pf.dsp, pf.collect]);
// [ [ 0, 0 ], [ 1, 0 ], [ 0, 1 ], [ 1, 1 ], [ 0, 2 ], [ 1, 2 ] ]The maptos(), map2() higher order words can be used to transform
stack items in place using vanilla JS functions:
maptos(f)- replaces TOS with result of given function.map2(f)- takes top 2 values from stack, calls function and writes back result. The arg order is (TOS, TOS-1) - this is how all primitive math ops are implemented
The second stack ("R-stack") is useful to store interim processing state without having to resort to complex stack shuffling ops. There're several words available for moving data between main ("D-stack") and the r-stack and to manipulate the structure of the R-stack itself.
import * as pf from "@thi.ng/pointfree";
// this example partitions the main stack into triples
// helper word to check if there're values on d-stack
// (`dsp` return d-stack pointer, i.e. the current depth of the stack)
notempty = pf.word([pf.dsp, pf.ispos])
// helper word to collect max `n` items into a tuple
// ( ... n -- [...] )
collectmax = pf.word([pf.dsp, pf.dec, pf.min, pf.collect])
pf.runU([
// create result array
[],
// desired partition size
3,
// move both values onto r-stack
pf.movdr2,
// start loop
pf.loop(
// test if there're more items on d-stack
notempty,
[
// copy r-stack TOS to d-stack (partition size)
pf.cprd,
// create tuple
collectmax,
// swap r-stack values
pf.rswap,
// copy result array from r-stack to d-stack
pf.cprd,
// push tuple into result array
pf.pushl,
// drop result array from d-stack
pf.drop,
// swap r-stack vals again to restore orig order
pf.rswap
]),
// drop partition size from r-stack
pf.rdrop,
// move result array from r-stack to d-stack
pf.movrd
],
// initial stack context (to be partitioned)
pf.ctx([1,2,3,4,5,6,7,8])
);
// [ [ 1, 2 ], [ 3, 4, 5 ], [ 6, 7, 8 ] ]TODO more examples forthcoming
By default, each word checks for stack underflow and throws an error if
there are insufficient values on the stack. These checks can be disabled
by calling pf.safeMode(false).
Note: Some of the words are higher-order functions, accepting arguments at word construction time and return a pre-configured stack function.
| Word | Stack effect | Description |
|---|---|---|
drop |
( x -- ) |
remove TOS |
drop2 |
( x y -- ) |
remove top 2 vals |
dropif |
( x -- ? ) |
remove only if TOS truthy |
dsp |
( -- stack.length ) |
push d-stack depth |
dup |
( x -- x x ) |
duplicate TOS |
dup2 |
( x y -- x y x y ) |
duplicate top 2 vals |
dup3 |
( x y z -- x y z x y z ) |
duplicate top 3 vals |
dupif |
( x -- x x? ) |
dup only if TOS truthy |
maptos(fn) |
( x -- f(x) ) |
transform TOS w/ f |
map2(fn) |
( x y -- f(y, x) ) |
reduce top 2 vals with f, single result |
nip |
( x y -- y ) |
remove x from stack |
over |
( x y -- x y x ) |
push dup of x |
pick |
( n -- stack[n] ) |
dup deeper stack value |
push(...args) |
( -- ...args ) |
push args on stack |
rot |
( x y z -- y z x ) |
rotate top 3 vals down/left |
invrot |
( x y z -- z x y ) |
rotate top 3 vals up/right |
swap |
( x y -- y x ) |
swap top 2 vals |
swap2 |
( a b c d -- c d a b ) |
swap top 2 pairs |
tuck |
( x y -- y x y ) |
insert dup of TOS |
| Word | Stack effect | Description |
|---|---|---|
rdrop |
( x -- ) |
drop TOS from r-stack |
rdrop2 |
( x y -- ) |
remove top 2 vals from r-stack |
rswap |
( x y -- y x ) |
swap top 2 vals on r-stack |
rswap2 |
( a b c d -- c d a b ) |
swap top 2 pairs on r-stack |
rsp |
( -- stack.length ) |
push r-stack depth on d-stack |
movdr |
( x -- ) (d-stack effect) |
push d-stack TOS on r-stack |
movrd |
( -- x ) (d-stack effect) |
push r-stack TOS on d-stack |
cpdr |
( x -- x ) (d-stack effect) |
copy d-stack TOS on r-stack |
cprd |
( -- x ) (d-stack effect) |
copy r-stack TOS on d-stack |
| Word | Stack effect | Description |
|---|---|---|
exec |
( w -- ? ) |
call TOS as (compiled) word w/ curr ctx |
dip |
( x q -- .. x ) |
|
dip2 |
( x y q -- .. x y ) |
|
dip3 |
( x y z q -- .. x y z ) |
|
dip4 |
( x y z w q -- .. x y z w ) |
|
keep |
( x q -- .. x ) |
|
keep2 |
( x y q -- .. x y ) |
|
keep3 |
( x y z q -- .. x y z ) |
|
bi |
( x p q -- pres qres ) |
|
bi2 |
( x y p q -- pres qres ) |
|
bi3 |
( x y z p q -- pres qres ) |
| Word | Stack effect | Description |
|---|---|---|
add |
( x y -- x+y ) |
|
sub |
( x y -- x-y ) |
|
mul |
( x y -- x*y ) |
|
div |
( x y -- x/y ) |
|
mod |
( x y -- x%y ) |
|
inc |
( x -- x+1 ) |
|
dec |
( x -- x-1 ) |
|
neg |
( x -- -x ) |
|
even |
( x -- bool ) |
true, if x is even |
odd |
( x -- bool ) |
true, if x is odd |
min |
( x y -- min(x, y) ) |
|
max |
( x y -- max(x, y) ) |
|
log |
( x -- log(x) ) |
|
pow |
( x y -- pow(x, y) ) |
|
rand |
( -- Math.random() ) |
|
sqrt |
( x -- sqrt(x) ) |
|
sin |
( x -- sin(x) ) |
|
cos |
( x -- cos(x) ) |
|
atan2 |
( x y -- atan2(y, x) ) |
|
lsl |
( x y -- x<<y ) |
|
lsr |
( x y -- x>>y ) |
|
lsru |
( x y -- x>>>y ) |
|
bitand |
( x y -- x&y ) |
|
bitor |
( x y -- x|y ) |
|
bitxor |
( x y -- x^y ) |
|
bitnot |
( x -- ~x ) |
| Word | Stack effect |
|---|---|
eq |
( x y -- x===y ) |
equiv |
( x y -- equiv(x,y) ) |
neq |
( x y -- x!==y ) |
and |
( x y -- x&&y ) |
or |
( x y -- x||y ) |
not |
( x -- !x ) |
lt |
( x y -- x<y ) |
gt |
( x y -- x>y ) |
lteq |
( x y -- x<=y ) |
gteq |
( x y -- x>=y ) |
iszero |
( x -- x===0 ) |
ispos |
( x -- x>0 ) |
isneg |
( x -- x<0 ) |
isnull |
( x -- x==null ) |
| Word | Stack effect | Description |
|---|---|---|
load |
( k -- env[k] ) |
pushes env[k] on d-stack |
store |
( x k -- ) |
stores TOS as env[k] |
loadkey(k) |
( -- env[k] ) |
like load w/ predefined key |
storekey(k) |
( x -- ) |
like store w/ predefined key |
pushenv |
( -- env ) |
pushes curr env on d-stack |
| Word | Stack effect | Description |
|---|---|---|
at |
( obj k -- obj[k] ) |
obj can be array/obj/string |
bindkeys |
(v1 v2 .. [k1 k2 ..] obj -- obj ) |
bind key/value pairs in obj |
collect |
( ... n -- [...] ) |
tuple of top n vals |
foldl |
( arr q init -- x ) |
like mapl, but w/ init val for reduction |
length |
( x -- x.length ) |
length of arraylike |
list |
( -- [] ) |
create new empty array |
mapl |
( arr q -- ? ) |
transform array w/ quotation (no explicit result array) |
mapll |
( arr q -- ? ) |
transform array w/ quotation |
obj |
( -- {} ) |
create new empty object |
pushl |
( x arr -- arr ) |
push x on LHS of array |
pushr |
( arr x -- arr ) |
push x on RHS of array |
popr |
( arr -- arr arr[-1] ) |
extract RHS of array as new TOS |
pull |
( arr -- x arr ) |
short for: [popr, swap] |
pull2 |
( arr -- x y arr ) |
short for: [pull, pull] |
pull3 |
( arr -- x y z arr ) |
short for: [pull2, pull] |
pull4 |
( arr -- a b c d arr ) |
short for: [pull2, pull2] |
split |
( arr x -- [...] [...] ) |
split array at index x |
setat |
( val obj k -- obj ) |
obj can be array/obj |
tuple(n) |
( ... -- [...] ) |
HOF, like collect, but w/ predefined size |
vec2 |
( x y -- [x, y] ) |
same as tuple(2) |
vec3 |
( x y z -- [x, y, z] ) |
same as tuple(3) |
vec4 |
( x y z w -- [x, y, z, w] ) |
same as tuple(4) |
vadd |
( a b -- c ) |
add 2 arrays (or array + scalar) |
vsub |
( a b -- c ) |
subtract 2 arrays (or array + scalar) |
vmul |
( a b -- c ) |
multiply 2 arrays (or array + scalar) |
vdiv |
( a b -- c ) |
divide 2 arrays (or array + scalar) |
op2v(f) |
( a b -- c ) |
HOF word gen, e.g. vadd is based on |
| Word | Stack effect | Description |
|---|---|---|
ismatch |
( str re -- bool ) |
Test regexp against string |
fromjson |
( str -- x ) |
Parse JSON string |
tojson |
( x -- str ) |
JSON stringify |
| Word | Stack effect | Description |
|---|---|---|
print |
( x -- ) |
console.log(x) |
printds |
( -- ) |
print out D-stack |
printrs |
( -- ) |
print out R-stack |
There's currently only one error handling construct available:
$try expects a body and error handler quotation on stack. Executes
body within an implicit try .. catch and if an error was thrown pushes
it on stack and executes error quotation.
import * as pf from "@thi.ng/pointfree";
pf.runU([
// body quotation
[pf.div],
// error handler
[pf.drop, "eek", pf.print],
pf.$try
]);
// eekcond(_then: StackFn | StackProgram, _else?: StackFn | StackProgram)
Higher order word. Takes two stack programs: truthy and falsey branches, respectively. When executed, pops TOS and runs only one of the branches depending if TOS was truthy or not.
Note: Unlike JS if() {...} else {...} constructs, the actual
conditional is not part of this word (only the branches are).
Non-HOF version of cond, expects test result and both branches on
d-stack. Executes thenq word/quotation if test is truthy, else runs
elseq.
( test thenq elseq -- ? )cases(cases: IObjectOf<StackFn | StackProgram>)
Higher order word. Essentially like JS switch. Takes an object of
stack programs with keys in the object being used to check for equality
with TOS. If a match is found, executes corresponding stack program. If
a default key is specified and no other cases matched, run default
program. In all other cases throws an error.
Important: The default case/branch has the original TOS re-added to the stack before execution.
loop(test: StackFn | StackProgram, body: StackFn | StackProgram)
Takes a test and body stack program. Applies test to TOS and
executes body. Repeats while test is truthy.
Non-HOF version of loop. Expects test result and body quotation/word
on d-stack.
( testq bodyq -- ? )( n body -- ? )Pops n and body from d-stack and executes given body word /
quotation n times. In each iteration pushes current counter on d-stack
prior to executing body. With empty body acts as finite range generator
0 .. n.
word(prog: StackProgram, env?: StackEnv, mergeEnv = false)
Higher order word. Takes a StackProgram and returns it as StackFn to
be used like any other built-in word. Unknown stack effect.
If the optional env is given, uses a shallow copy of that environment
(one per invocation) instead of the current one passed by run() at
runtime. If mergeEnv is true (default), the user provided env will be
merged with the current env (also shallow copies). This is useful for
providing external configuration (or local variables) or in conjunction
with pushenv and store or storekey to save results of sub
procedures in the main env.
Note: The provided (or merged) env is only active within the execution scope of the word.
wordU(prog: StackProgram, n = 1, env?: StackEnv, mergeEnv = true)
Like word(), but uses runU() for execution and returns n unwrapped
values from result stack.
unwrap(ctx: StackContext, n = 1)
Takes a result tuple returned by run() and unwraps one or more items
from result stack. If no n is given, defaults to single value (TOS)
and returns it as is. Returns an array for all other n.
ctx(stack: Stack = [], env: StackEnv = {}): StackContext
Creates a new StackContext tuple from given d-stack and/or environment only (the r-stack is always initialized empty).
run(prog: StackProc, ctx?: StackContext = [[], [], {}]): StackContext
Executes given stack word or program using (optional) context.
runU(prog: StackProc, ctx?: StackContext, n = 1): any
Like run(), but returns unwrapped result. Syntax sugar for:
unwrap(run(...),n)
runE(prog: StackProc, ctx?: StackContext): any
Like run(), but returns result environment. Syntax sugar for:
run(...)[2]
If this project contributes to an academic publication, please cite it as:
@misc{thing-pointfree,
title = "@thi.ng/pointfree",
author = "Karsten Schmidt",
note = "https://thi.ng/pointfree",
year = 2015
}© 2015 - 2024 Karsten Schmidt // Apache License 2.0