[Bug] Training on 13B causes loss to be 0, while 7B works fine #170
Comments
|
|
|
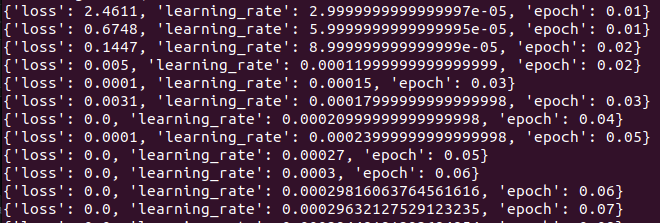
@ElleLeonne , thank you for answering. I also see your loss being 0. Isn't that incorrect? I don't think it should go that low right? I attached a sample training loss. The minimum is 0 and also some spike to some random high value. It should not be truncated for the plot since it’s not being logged to terminal. Edit: eval loss is NAN |

|
I tried running another pass, but was still unsuccessful. Will continue until I resolve my specific problem. |
|
Hello @ElleLeonne , thanks for the reply.
I noticed this issue originally with a custom dataset but was also able to reproduce it with the cleaned dataset in this repo. Does it work for you on the original cleaned dataset? |
|
Yes, the original cleaned version worked fine. After fixing the problem, Loss appears to stay steady for a single epoch. |
@ElleLeonne , may I clarify which model size you used?
Do you mean with a custom dataset in the same instruction/response format or do you mean with a completely new key format? |
|
7bn works with the cleaned alpaca dataset, and
Another dataset of mine that uses a similar, yet not identical, format,
with different key names.
…On Sun, Mar 26, 2023, 9:14 AM NanoCode012 ***@***.***> wrote:
Yes, the original cleaned version worked fine. After fixing the problem,
Loss appears to stay steady for a single epoch.
@ElleLeonne <https://github.com/ElleLeonne> , may I clarify which model
size you used?
If you're using a different dictionary to train, then all it's doing is
adding a blank key that never gets called
Do you mean with a custom dataset in the same instruction/response format
or do you mean with a completely new key format?
—
Reply to this email directly, view it on GitHub
<#170 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AUZTSGDZ6C76OW5FPEWXJJLW6BFLLANCNFSM6AAAAAAWHVRGFU>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
@ElleLeonne , have you tried the 13B on either dataset? Does it work? |
|
I had similar issues w/ training 13b with the cleaned dataset. Loss was zero immediately and eval_loss is nan. After the first epoch, loss dropped to zero again. Finished result: But, when running generate.py and attempting to pass any prompt I get errors: Is anyone able to successfully generate w/ 13b "out of the box"? |
|
@randerzander , I'm surprised your loss ended up well. Mine reached 0, sometimes spiked to some few thousand then back to zero with eval loss being NAN. |
|
Facing the same issue, the loss is 0. for the 13B model and extremely large (more than 10,000 after 0.5 epoch) for the 7B model on the cleaned dataset. I am using V100 32G. When training with a single RTX 3090 GPU, the loss seems fine for now. Follow-up: RTX 3090 and A100 both work for me. But once using V100 32G, the same issue appears... |
I encountered the same problem with V100 32G. |
|
@ElleLeonne what is the loss used inside the model, |
|
yeah, the sample problem!! |
|
Bitsandbytes can be run on 8-bit tensor core-supported hardware, which are Turing and Ampere GPUs (RTX 20s, RTX 30s, A40-A100, T4+). I guess V100 doesn't support for INT8. |
I maybe met the same problem. How do you fix this code? |
|
Your json dataset will have a list of dictionaries. If your output key is
something other than "Reply", (Maybe it's "Output", or "output", they're
case-sensitive) you should change the "Reply" key to that new value.
…On Sat, Apr 1, 2023, 1:06 AM ghqing0310 ***@***.***> wrote:
[image: image]
<https://user-images.githubusercontent.com/87243032/227780494-b6e1b0ea-1487-49b6-9f96-6d66f1074d30.png>
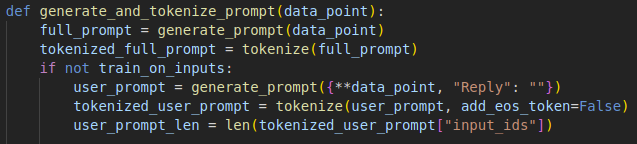
So I discovered an issue where, when switching to a new dataset, the
attention mask actually just sets the dictionary key for the Output to be
"", before calling the generate_prompt function. If you're using a
different dictionary to train, then all it's doing is adding a blank key
that never gets called, resulting in the model learning that every reply
should be empty, as the attention mask always equals the full prompt.
I tried running another pass, but was still unsuccessful. Will continue
until I resolve my specific problem.
I maybe met the same problem. How do you fix this code?
—
Reply to this email directly, view it on GitHub
<#170 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AUZTSGEX7JGNB6VCEWFSAW3W67AX7ANCNFSM6AAAAAAWHVRGFU>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
|
hi, I faced the same problem and I fixed it by reinstalling the peft and transformers package. |
@Dr-Corgi Hi, my problem is training loss always 0.0 when finetuning llama-13B on V100, is same with you? |

|
My training loss on the V100 starts very erratically and then goes to 0 |
|
Could one reasoning be that |
I encountered the same problem with A100 80G. |
|
The loss 0 not comes from int8, but huggingface default fp16 set to True. However, if you using int8 training on V100, it was extremly slow both caused by hf optimization (just ver slow on v100 int8) && v100 itself didn't have int8 tensor cores for speedup. You have to enable deepspeed for loss scale and trim and have to using fp16 training, otherwise it's very slow. |
|
Sometimes the issue is too low lora rank. |
|
Same problem |
I tested LLaMa-7b with bf16 on A100 and I also met the same problem. |
|
This may be due to hardware reasons. On some hardware, the quantization model is not compatible with fp16. You can try set fp16=False. It works for me. |
I solve it by setting |
Hello,
Thank you for your work.
I encountered a weird issue with training LORA. I used the default settings with cleaned dataset and can successfully train the 7B one. However, if I were to change to use the 13B model (and tokenizer) by updating the
base_modelfrom7b->13b, it would cause the output train loss to be 0. The only thing that changed was the model path/name.This was tested on the latest commit d358124 and an older one e04897b
{'loss': 0.0, 'learning_rate': 0.0, 'epoch': 0.03}I have tried to change the micro batch size and context length, but the issue persists.
Is there something else I need to change?
Env:
Edit: I have asked this in Discord. A supposed reasoning was due to padding. However, I did not modify the original code. It was run with default setting.
The text was updated successfully, but these errors were encountered: