We release various convolutional neural networks (CNNs) trained on Places365 to the public. Places365 is the latest subset of Places2 Database. There are two versions of Places365: Places365-Standard and Places365-Challenge. The train set of Places365-Standard has ~1.8 million images from 365 scene categories, where there are at most 5000 images per category. We have trained various baseline CNNs on the Places365-Standard and released them as below. Meanwhile, the train set of Places365-Challenge has extra 6.2 million images along with all the images of Places365-Standard (so totally ~8 million images), where there are at most 40,000 images per category. Places365-Challenge will be used for the Places2 Challenge 2016 to be held in conjunction with the ILSVRC and COCO joint workshop at ECCV 2016.
The data Places365-Standard and Places365-Challenge are released at Places2 website.
- AlexNet-places365:
deploy_alexnet_places365.prototxtweights:[http://places2.csail.mit.edu/models_places365/alexnet_places365.caffemodel] - GoogLeNet-places365:
deploy_googlenet_places365.prototxtweights:[http://places2.csail.mit.edu/models_places365/googlenet_places365.caffemodel] - VGG16-places365:
deploy_vgg16_places365.prototxtweights:[http://places2.csail.mit.edu/models_places365/vgg16_places365.caffemodel] - VGG16-hybrid1365:
deploy_vgg16_hybrid1365.prototxtweights:[http://places2.csail.mit.edu/models_places365/vgg16_hybrid1365.caffemodel] - ResNet152-places365:
deploy_resnet152_places365.prototxtweights:[http://places2.csail.mit.edu/models_places365/resnet152_places365.caffemodel] - ResNet152-hybrid1365:
deploy_resnet152_hybrid1365.prototxtweights:[http://places2.csail.mit.edu/models_places365/resnet152_hybrid1365.caffemodel]
The category index file is categories_places365.txt. Here we combine the training set of ImageNet 1.2 million data with Places365-Standard to train VGG16-hybrid1365 model, its category index file is categories_hybrid1365.txt. To download all the files, you could access here
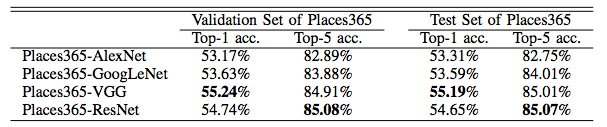
The performance of the baseline CNNs is listed below. ResidualNet's performance will be updated soon. We use the class score averaged over 10-crops of each testing image to classify. Here we also fine-tune the resNet152 on Places365-standard, for 10 crop average it has 85.08% on the validation set and 85.07% on the test set for top-5 accuracy. <img src="http://places2.csail.mit.edu/models_places365/table2.jpg" alt="Drawing"/ style="height: 200px;"/>
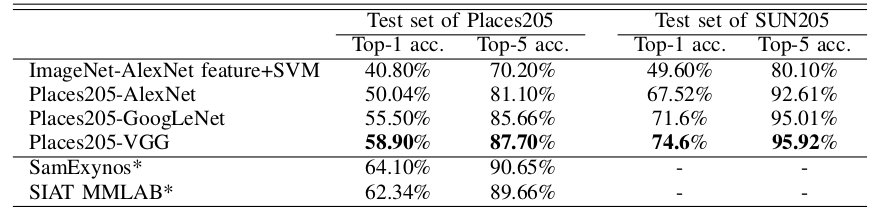
As comparison, we list the performance of the baseline CNNs trained on Places205 as below. There are 160 more scene categories in Places365 than the Places205, the top-5 accuracy doesn't drop much. <img src="http://places2.csail.mit.edu/models_places365/table1.jpg" alt="Drawing"/ style="height: 250px;"/>
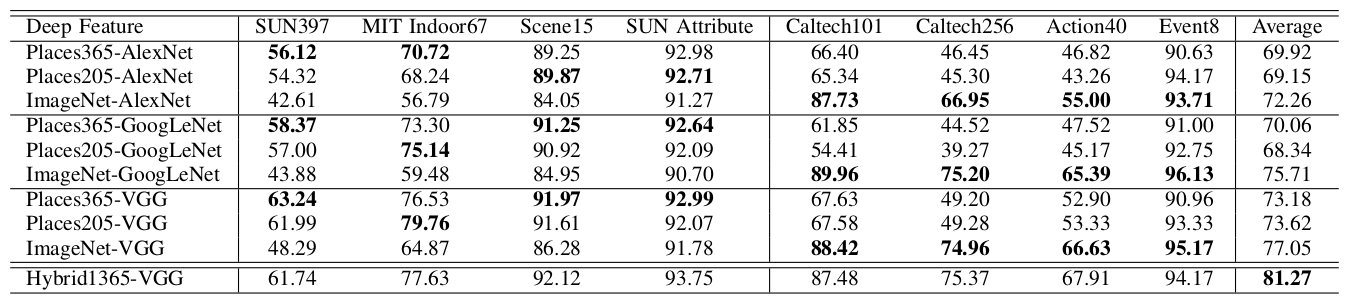
The performance of the deep features of Places365-CNNs as generic visual features is listed below ResidualNets' performances will be included soon. The setup for each experiment is the same as the ones in our NIPS'14 paper
Some qualitative prediction results using the VGG16-Places365:

{kind=link}
{kind=link}
Link: Places2 Database, Places1 Database
Please cite the following paper if you use the data or pre-trained CNN models.
Learning Deep Features for Scene Recognition using Places Database.
B. Zhou, A. Lapedriza, J. Xiao, A. Torralba and A. Oliva
Advances in Neural Information Processing Systems 27 (NIPS), 2014.
Places: An Image Database for Deep Scene Understanding.
B. Zhou, A. Khosla, A. Lapedriza, A. Torralba and A. Oliva
Arxiv, 2016 (pdf coming soon)