Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
net: replace RwLock<Slab> with a lock free slab (#1625)
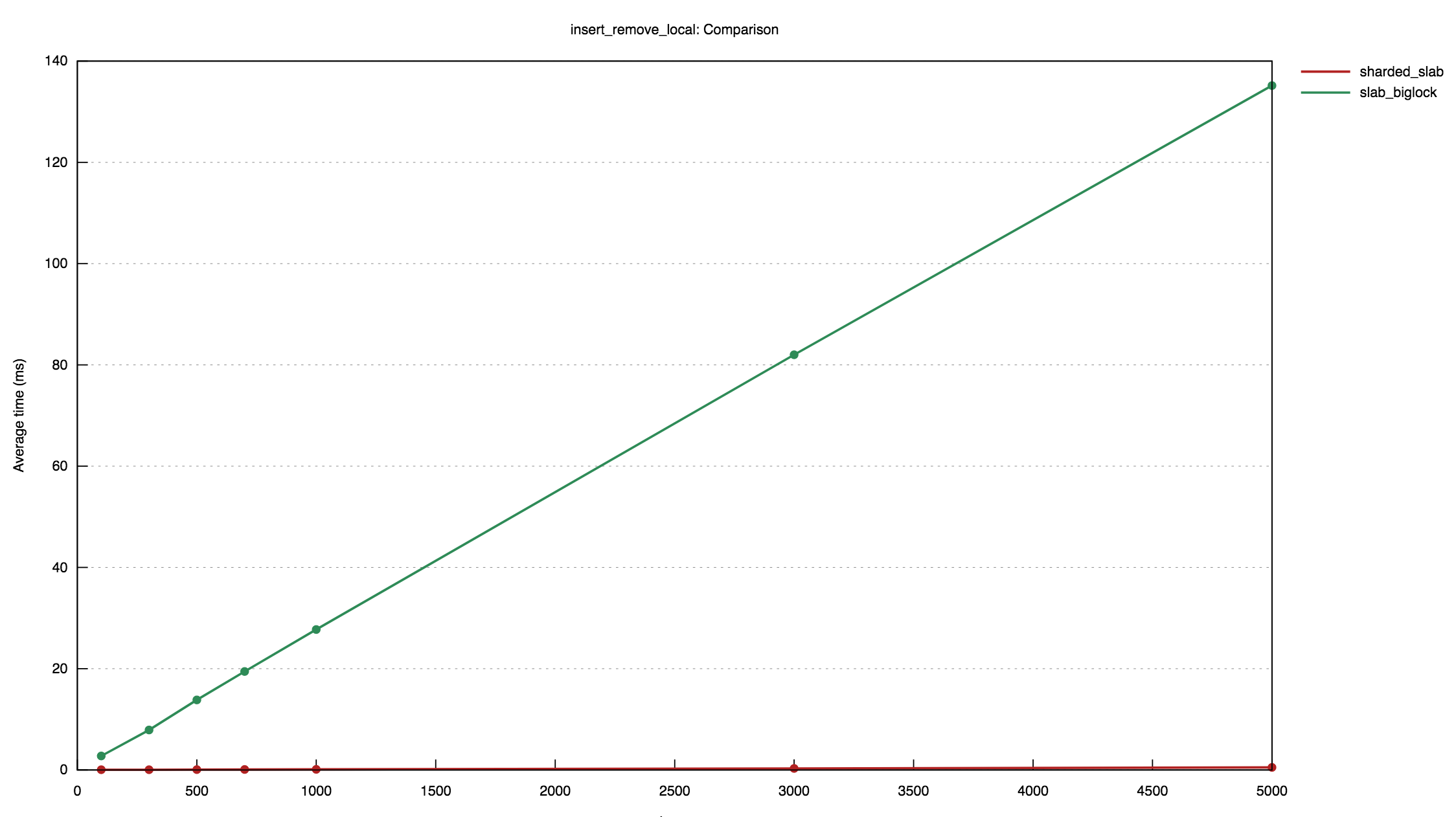
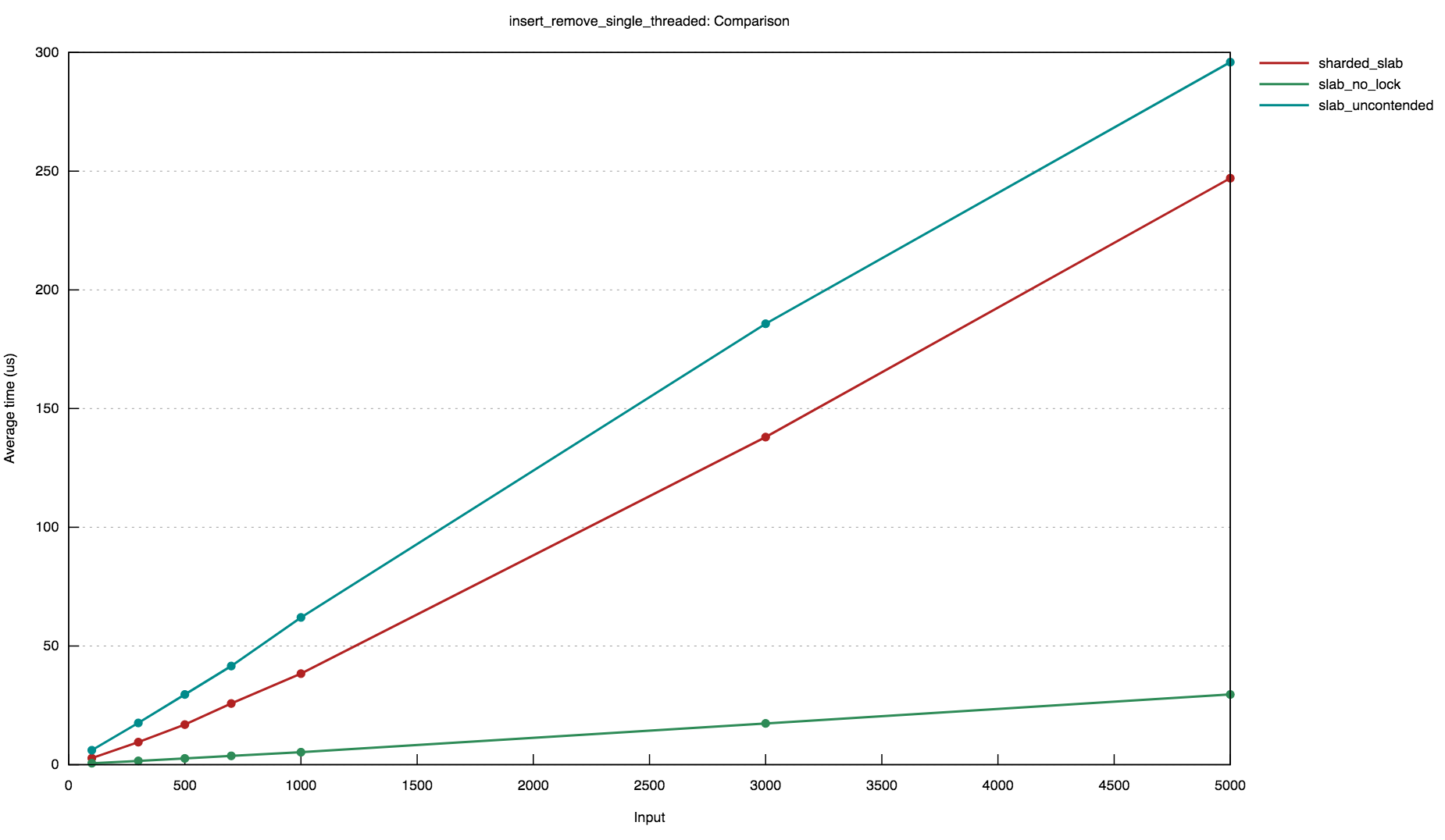
## Motivation The `tokio_net::driver` module currently stores the state associated with scheduled IO resources in a `Slab` implementation from the `slab` crate. Because inserting items into and removing items from `slab::Slab` requires mutable access, the slab must be placed within a `RwLock`. This has the potential to be a performance bottleneck especially in the context of the work-stealing scheduler where tasks and the reactor are often located on the same thread. `tokio-net` currently reimplements the `ShardedRwLock` type from `crossbeam` on top of `parking_lot`'s `RwLock` in an attempt to squeeze as much performance as possible out of the read-write lock around the slab. This introduces several dependencies that are not used elsewhere. ## Solution This branch replaces the `RwLock<Slab>` with a lock-free sharded slab implementation. The sharded slab is based on the concept of _free list sharding_ described by Leijen, Zorn, and de Moura in [_Mimalloc: Free List Sharding in Action_][mimalloc], which describes the implementation of a concurrent memory allocator. In this approach, the slab is sharded so that each thread has its own thread-local list of slab _pages_. Objects are always inserted into the local slab of the thread where the insertion is performed. Therefore, the insert operation needs not be synchronized. However, since objects can be _removed_ from the slab by threads other than the one on which they were inserted, removal operations can still occur concurrently. Therefore, Leijen et al. introduce a concept of _local_ and _global_ free lists. When an object is removed on the same thread it was originally inserted on, it is placed on the local free list; if it is removed on another thread, it goes on the global free list for the heap of the thread from which it originated. To find a free slot to insert into, the local free list is used first; if it is empty, the entire global free list is popped onto the local free list. Since the local free list is only ever accessed by the thread it belongs to, it does not require synchronization at all, and because the global free list is popped from infrequently, the cost of synchronization has a reduced impact. A majority of insertions can occur without any synchronization at all; and removals only require synchronization when an object has left its parent thread. The sharded slab was initially implemented in a separate crate (soon to be released), vendored in-tree to decrease `tokio-net`'s dependencies. Some code from the original implementation was removed or simplified, since it is only necessary to support `tokio-net`'s use case, rather than to provide a fully generic implementation. [mimalloc]: https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf ## Performance These graphs were produced by out-of-tree `criterion` benchmarks of the sharded slab implementation. The first shows the results of a benchmark where an increasing number of items are inserted and then removed into a slab concurrently by five threads. It compares the performance of the sharded slab implementation with a `RwLock<slab::Slab>`: <img width="1124" alt="Screen Shot 2019-10-01 at 5 09 49 PM" src="https://user-images.githubusercontent.com/2796466/66078398-cd6c9f80-e516-11e9-9923-0ed6292e8498.png"> The second graph shows the results of a benchmark where an increasing number of items are inserted and then removed by a _single_ thread. It compares the performance of the sharded slab implementation with an `RwLock<slab::Slab>` and a `mut slab::Slab`. <img width="925" alt="Screen Shot 2019-10-01 at 5 13 45 PM" src="https://user-images.githubusercontent.com/2796466/66078469-f0974f00-e516-11e9-95b5-f65f0aa7e494.png"> Note that while the `mut slab::Slab` (i.e. no read-write lock) is (unsurprisingly) faster than the sharded slab in the single-threaded benchmark, the sharded slab outperforms the un-contended `RwLock<slab::Slab>`. This case, where the lock is uncontended and only accessed from a single thread, represents the best case for the current use of `slab` in `tokio-net`, since the lock cannot be conditionally removed in the single-threaded case. These benchmarks demonstrate that, while the sharded approach introduces a small constant-factor overhead, it offers significantly better performance across concurrent accesses. ## Notes This branch removes the following dependencies `tokio-net`: - `parking_lot` - `num_cpus` - `crossbeam_util` - `slab` This branch adds the following dev-dependencies: - `proptest` - `loom` Note that these dev dependencies were used to implement tests for the sharded-slab crate out-of-tree, and were necessary in order to vendor the existing tests. Alternatively, since the implementation is tested externally, we _could_ remove these tests in order to avoid picking up dev-dependencies. However, this means that we should try to ensure that `tokio-net`'s vendored implementation doesn't diverge significantly from upstream's, since it would be missing a majority of its tests. Signed-off-by: Eliza Weisman <eliza@buoyant.io>
{kind=link}
{kind=link}
- Loading branch information