Design discussion #14
Comments
|
Also, I want to emphasize that, with the help of Regarding multiplexing, I think it's better up to the underlying protocol to decide whether to terminate a connection.
I don't recommend using multiplexing because it seems that GFW closes long |
|
Well, all you said is exactly what I considered, your design is really perfect. I will continue pay attention to this issue, but I'm going to be busy until the end of December, that means I could not contribute to this project during this period. And another thing I care about is that, GFW seems to RST a tls connection after large flow, which could be reproducted by downloading large file in sftp. So, is it possible to forge a certificate which make our handshake very similar to Microsoft.com or any other whitelist website, and do our real handshake behind it? This may need to re-inplement tls layer. (Actually I do not familar with tls, and I don't know is it necessary to do so) |
Yes or no? You can say it with confidence by checking for TTLs in RST packets.
Is there a typo in here? SFTP is not related to TLS. (Edit: did you mean FTPS?)
You can. You can create a self-signed CA and use it to sign an identical certificate of *.microsoft.com, which though will not trusted by your browser unless your own CA is added to the trust list. Realtime DPI will not be able to catch this fake certificate but this forged one will be a very distinct feature for offline analysis (Facebook study found only 0.2% of the SSL connections used forged certificates). |
|
Interesting.......and valuable idea. BTW: It's a bad feature when anti-package length analysis. but i think we can have another good idea to make a multiplexing protocol. |
|
A size of zero doesn't mean that the tcp packet size is zero. It means that the TLS decrypted packet size is zero; they are different. But yes, it might leave some pattern and we can use some other indicators to indicate EOF of a connection. |
|
Good News: 36.68% of SSL certificates are issued by let's encrypt. Therefore, SSL traffic with let's encrypt certificate will be common. |
|
I means that, if we use a fixed or similar package who has special length or other feature, this will became a feature to be tracked. |
It's quite different from 36.68% of the traffic having Let's Encrypt certs. A while ago it's reported 96.7% of LE certs were issued for phishing sites.
The idea about chunked encoding is not this. Look at the example https://en.wikipedia.org/wiki/Chunked_transfer_encoding#Encoded_data. "A size of zero" means two nul bytes as the size field in the TCP stream. This idea is orthogonal to traffic obfuscation. Having these extra bytes in the stream also doesn't mean there has to be extra packets. |
|
Some notes. There was a lot of work for MitM proxies (1 2 3) in http/2 drafts during 2014 but it ended up a big no-no because NSA and "MitM" is basically the word of evil. But really, TLS-in-TLS is pretty bad in terms of performance. Why you don't want to implement your own TLS 1.3 0-RTT: check all the MUST NOTs in https://tools.ietf.org/html/draft-ietf-tls-tls13-22#section-8 and https://tools.ietf.org/html/draft-ietf-tls-tls13-22#appendix-E.5. What about HPACK compression for TLS headers? Security implications? |
|
@klzgrad |
|
GreaterFire: Performance is a major part of usability. Latency is a major part of performance. Throughput is a solved problem long ago. HTTP/2 with its reinvention of TCP, TLS 1.3, TLS False Start, SPDY, all these things try to reduce the initial startup latency. TLS-in-TLS is a problem if it happens for every connections. We were discussing connection multiplexing. I tested Chromium's usage of a plain http/2 proxy: chromium --proxy-server=https://ip:port -> nghttpx -> squid. Some intense multimedia browsing of many websites used only 2 TCP connections, which implies http/2 multiplexing was working very well (defeats flow-based statistical fingerprinting, and amortizes TCP and TLS startup cost). Better yet, the h2 spec also provides for packet padding. A plain h2 proxy does not meet our requirements though. It uses challenge-response authentication which is prone to probing. It does not forward to a regular web service if auth fails. And the CONNECT tunnel adds an extra round trip. We need: 1) PSK auth in the first request of the h2 connection, 2) runtime backend selection using the PSK, 3) tunneled payload follows CONNECT immediately without waiting for HTTP/2 200 OK (I'm not sure if the h2 spec allows this??! Do we have something like CONNECT False Start?), 4) start the h2 tunnel connection with a dummy preamble GET request for obfuscation (maybe put the PSK in this GET request). Further extensions include: packet padding, proxy auto-selection using Chromium's network quality estimator, HPACK compression for TLS headers. |
|
@klzgrad in HTTP/1.1 we can send tunneled payload immediately after CONNECT without waiting for HTTP/1.1 200 Connection established. I don't know but would assume that HTTP/2 does the same, for the sake of performance. According to RFC 7540 Section 8.3, it seems that the client does not need to wait for the 2xx status code. Actually I am not very sure. |
|
This wording made it ambiguous. Before the HEADERS frame containing a 2xx status code is sent, does a DATA frame correspond to data sent on the TCP connection? This may not be as rigorous though as the wording first came out here https://www.ietf.org/mail-archive/web/httpbisa/current/msg15023.html which came from Google people and the spec about CONNECT is basically what they have implemented, which is true to this day. This "CONNECT Fast Open" mechanics seems overlooked. There is no reason to forbid it. Btw, RFC 2617 HTTP Authentication: Basic and Digest Access Authentication provides So yeah, h2 auth doesn't have to be challenge-response. |
|
It's awesome that h2 auth doesn't have to be challenge-response! We could even make trojan client-less because the active detection of the protocol just doesn't work! |
|
But wait... we need the browser to send the credentials in the initial proxy request... which I don't know whether they implement it. |
|
In another test I replaced nghttpx with Haproxy. According to https://github.com/http2/http2-spec/wiki/Implementations, only 3 open-source http/2 reverse proxies are available. Among them Haproxy should be the most common (less discriminating information) and of the best quality. Nginx doesn't support http/2 reverse proxying. So it appears Haproxy is the only choice. Haproxy can select backends using http headers, calling it content switching. I configured it as haproxy + squid + nginx. Authentication uses
Eventually we should use some other http header than user-agent. The next steps are to create a socks2https gateway (Trojan client) and a http proxy gateway (Trojan server) based on Chromium. The architecture should look like The hop between Browser and Trojan client and the hop between Haproxy and Trojan server both work in respective localhosts so the performance cost of separating them into separate processes should be negligible - the real optimization target is the hop between Trojan client and Haproxy typically with latency >150ms. Haproxy is a necessary front to mitigate |
|
Is an HTTP/2 CONNECT tunnel doing TCP-over-TCP? This confuses people:
-- Hypertext Transfer Protocol Version 2 (Hacker News)
-- http/2 & hpack protocol review
-- Performance and Opportunities of HTTP 2.0 (Hacker News) Any new tunnel/proxy using HTTP will have to answer the same question:
-- Chisel – A fast TCP tunnel over HTTP The answer is no. There is no double congestion control and it is not doing TCP-over-TCP. TCP = Retransmission + Checksum + Flow control + Congestion control. HTTP/2 has no retransmission, no checksum, no congestion control, and its flow control can be effectively turned off (with a 2^31-1 window, in practice usually large windows applied). The argument against TCP-over-TCP is that the retransmission timers in the two TCP stacks work against each other, but the argument is irrelevant to HTTP/2 because HTTP/2 does not do retransmission, again because HTTP/2 streams operate at a reliable, ordered, and error-free session layer. Its stream multiplexing is essentially just data prioritization and nothing more. So no, HTTP/2 is not TCP-over-TCP. |
|
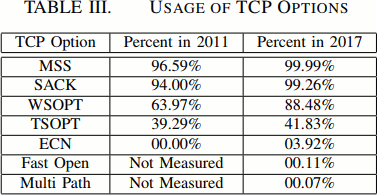
Here are some latest data points about the general internet traffic characteristics, providing arguments for using TLS.
Datasets: collected at a university network, uncompressed headers, 500GB/day, 7 days in May 2017.
Also, yeah, TCP Fast Open be damned.
|

|
PKI and TLS parameter policies. Still, the rationale is to reduce discriminating information/increase anonymity: find and use the most common configurations, and when that is not possible, specify as little number of parameters as possible (require user configuration instead). Ideally, zero conf and zero spec.
According to https://trends.builtwith.com/ssl Let's Encrypt is used a lot among top websites proving its prevalence. The problem is it requires a domain name and a lot of config: 1. Register a free/$1 domain (subdomains okay) because the user probably wants to separate his blog from his vpn; 2. Use some LE clients to get a cert; 3. Renew the cert in 3 months. LE recommends automation but getting it automated is even more work. In a system of censorship by "trustworthiness" ranking, free or cheap domains are among the most suspicious, and free and cheap certs are among the most suspicious. (Consider this: free domains and free certs are used by malware a lot.) In this sense it is actually not certain if LE is a lot better than the two self-signing schemes in reducing discriminating information. LE is also not as impregnable in terms of collateral damage. Consider: if the GFW blocks all LE certs now Chinese users probably would perceive nothing. Self-signed CAs and related proper private PKI practices sound good in theory because it is actually used by corporations (even 12306.cn) while OpenVPN uses it too. The problem is there are too many parameters (and standards) in configuring this PKI making each config quite unique and there is no single PKI toolchain that can be considered "common" (This is assuming configuring PKI (or anything as is being discussed here) is so complicated for the user that we have to automate, during which we must choose some defaults which then become the only parameters ever used hence the fingerprints. There are good reasons not to specify defaults when those are not already widely used.). What parameters to use must be based on actual stats, and I haven't found such data yet. Self-signed certs don't have the problem of too many parameters and don't have the problem of requiring registering a domain. Its problem is browser interactions with self-signed websites are fairly distinct too: browsers have made it increasingly difficult to access websites with self-signed certs by warning the users away, and if the browser keeps doing traffic with self-signed certs that becomes an anomaly. Basically it's not considered legitimate by browsers in any case. In conclusion I think Let's Encrypt is probably equal to private PKI in terms of anonymity if the latter is configured with ideal parameters, and private PKI is a lot more flexible than Let's Encrypt. Self-signed certs are theoretically worse than the previous two in terms of anonymity but how much is unknown.
For the client, we use Chromium's code with its bundled parameters. For the server, Haproxy is a very common server and its Debian/Ubuntu distribution's default config recommends Mozilla SSL Configuration Generator, so that is a common template (not sure if intermediate or modern). Another is Cloudflare's sslconfig. Also, according to https://www.ssllabs.com/ssl-pulse/, we should use 2048-bit key certs (LE tends to encourage 4096-bit) and don't have to worry about HSTS headers, DNS CAA, and OCSP Stapling yet.
|
|
The rate of HTTP/2 deployment is surprisingly huge to me. However, I am currently satisfied with the status quo of trojan and won't be doing many modifications to it in a fair amount of time. If we want to look like an HTTP/2 server, we can simply put a supported web server on port 80 and add "h2" to the server alpn configuration. Then trojan client would act like a browser that doesn't support HTTP/2. (Be sure to remove "h2" in client alpn configuration, of course.) We can do HTTP 301 to port 443 on port 80, but then the remote_addr of trojan server shouldn't be pointed to 80 because it'll cause an infinite redirection. (or we can stop redirecting connections from localhost) I always think that circumventing GFW is very subtle, so it's ok to be complicated (domain names and SSL certificates and all that shit) as long as it works and works well. Now that trojan is very flexible and fully-configurable, I might step back for a while in this field and wait for things to be settled down (like TLS 1.3, HTTP/2, Chromium version, mobile porting, etc.) and make changes when necessary. |
I'm not sure if I understand this. But Haproxy + Squid basically implements another Trojan server (similar to how it's done in Nginx). Yesterday I was testing Haproxy with Cloudflare's sslconfig but I got different ciphers in SSL Labs from Cloudflare servers because Cloudflare was using BoringSSL while I was using OpenSSL, and BoringSSL removes some ciphers. This is saying servers' TLS stacks will also have many identifying fingerprints (need active probing though), and care is needed to choose a server/TLS implementation to normalize those TLS fingerprints.
These are a concern because they increase the attack surface for statistical analysis. But again, they are also part of the profile of a regular website so that's the argument for having them.
This will take quite a while. The QUIC spec also depends on it. I won't expect to use TLS 1.3 0-RTT any time soon though. It is very tricky to implement because of many security considerations.
There are a lot of performance arguments in using h2 comparing to per-connection proxying. Stuff like this https://github.com/shadowsocks/shadowsocks/wiki/Optimizing-Shadowsocks won't be much necessary any more because h2 reduces TCP costs a lot with multiplexing. Similarly for TCP Fast Open, 0-RTT, all kinds of RTT hacks.
This yes. I've got some toy binaries running. Am working on the minimum implementation. The Chromium version will also automatically have QUIC tunneling capabilities.
@fqrouter has got a great design doc for this http://fqrouter.tumblr.com/post/51474945203. But the core idea is quite simple: |
|
Good news. QUIC proxy support is just added in Chromium https://chromium-review.googlesource.com/c/chromium/src/+/858603. Uber has made a QUIC reverse proxy https://chromium-review.googlesource.com/c/chromium/src/+/677880. |
I would like to invite you to the discussion of the rationales and ideas for a better circumvention protocol.
Many of the points below can have better context with citations but I try to keep it informal this time.
Why use TLS
Security
The Shadowsocks specification has been reinventing cryptography to make up for apparent vulnerabilities from various probing attacks. It among other similar protocols try to recommend specific cipher suites and cryptographic configurations without professional analysis and audit. The fact that the Shadowsocks spec was fixed again and again with faulty cryptographic designs shows how hard it is to reinvent cryptography and why obfuscation is not possible without certain level of security.
This subject has been much better researched and engineered for years as TLS. TLS provides confidentiality, authentication, and integrity. It protects against replay attack. It has mature and high performance and cross-platform implementations. It is only sensible to adopt commonly used best practices. Those who do not understand TLS are doomed to reinvent it, poorly.
Obfuscation
What Shadowsocks is doing is no different from Tor's pluggable transports, e.g. ScrambleSuit and obfs4, which have designed custom cryptographic protocols to replace Tor's default TLS stack, except that Tor's protocols are scholarly peer-reviewed.
The assumption of these Tor PT protocols is that if the wire data look as random as possible (above the transport layer) it would be impossible to identify or classify. This assumption has its limitation. It is shown that random packet padding actually becomes a feature in itself and enables new entropy-based attacks.
The bigger picture is that most traffic on the Internet does not look random. If an obfuscation protocol makes the data too random it attracts additional scrutiny. A thought experiment: the GFW intercepts 60% HTTP, 30% TLS, and 10% unrecognized high-entropy traffic. After the initial coarse traffic classification, the 10% traffic gets redirected for additional analysis, where more advanced methods become affordable.
The obvious solution is to obfuscate above the transport layer inside real TLS. By moving the protocol up the layer, traffic classification at the transport layer is less effective and the obfuscated traffic is less likely to be scrutinized by being of a larger traffic class. (Note that it must be real TLS. Mimicry of HTTP (or TLS) has been shown to be easily detected.) I think this is part of the reason Meek (plain HTTPS proxy with fake TLS SNI) is given more attention at Tor. As more traffic moves to TLS this effect becomes more pronounced.
Problems of TLS
Information leak
TLS is much more complex than TCP and give off much more information, mostly in TLS parameters in ClientHello and ServerHello, state transition, and certificates.
In principles these protocol behaviors can be imitated perfectly by reusing a browser's TLS stack and it is easy to verify the imitation locally.
GFW people have proposed to prioritize traffic for more advanced analysis by a "trustworthiness" ranking of the certificates. This is essentially network-layer host behavior analysis applied at the TLS layer and the certificates are the new IP addresses. Indeed IP addresses can also have "trustworthiness" used to prioritize traffic for analysis, e.g. if 99% traffic of a foreign host is with a single domestic host, select it for advanced tunnel traffic classifiers; well-known IP addresses are whitelisted, etc.
Traffic selection is always happening and it's a matter of degree of uniqueness of the certificates. In this sense CA-signed certificates (Let's Encrypt) can be even more unique than self-signed certificates because the former may represent less traffic than the latter. There are no clear wrong options here for circumvention but the choice of best practice remains an open question.
Performance
TLS handshakes introduce additional RTT on top of TCP handshakes. Latency is critical for network performance.
The Shadowsocks protocol has no handshakes and its implementation uses TCP Fast Open which reduces even more handshake RTT. Although TCP Fast Open is not always usable as it is commonly obstructed by middleboxes.
Speaking of RTT, VPNs at the network layer would have the least RTT among proxy schemes, but VPNs' usability is harmed by its requirement to configure the OS network stack. In this sense Shadowsocks' success is partly due to the fact that it requires little sysadmin work which is a reasonable tradeoff for TCP handshake RTT.
There are remedies in TLS for the RTT problem. TLS 1.2 False Start extension reduces handshakes to 1-RTT. TLS 1.3 (draft) introduces a 0-RTT mode. But TLS 1.3 implementations are still not production-ready to match the 0-RTT performance in Shadowsocks protocol (I tried Chromium/BoringSSL, Nginx. Though HAProxy just put out 0-RTT support in 1.8-rc3, I was working with Nginx because it's easier for scripting. I hope I can get them working soon.)
About TCP Fast Open, I found neither Nginx nor HAProxy has implemented it in client mode. Nginx gave an interesting reason: it's better to use persistent connections instead of creating new connections very fast. Shadowsocks creates a new proxy connection for each client request. It is arguable whether multiplexing would be better than that for Shadowsocks, but the benefit is obvious in the case of TLS where the cost of creating new connections is high.
There are two schemes of multiplexing: one is multiplexing multiple streams into a single TCP connection, the other is connection reuse/connection pooling. Mux.Cool used by V2Ray is of the first scheme. The first scheme has a head-of-line blocking problem which increases latency, see this. The second one is used by Nginx as "keepalives." It works like this: For a new client connection, try to use an idle proxy connection in the pool or create a new connection; after the client connection is closed, do not close the proxy connection instead save it into the pool as idle (with an idle timeout).
The Shadowsocks protocol does not allow multiplexing because it cannot distinguish the start and end of streams. Neither does the Trojan protocol but Trojan can be extended to allow this enhancement. To enable multiplexing the protocol can use a similar scheme as HTTP chunked transfer encoding:
Traffic analysis
I agree this is a legitimate threat and deserves attention. There has been a report of a specific TLS-in-TLS proxy being repeatably detected by traffic analysis, but at the same time GFW people have also admitted the limitation of practical traffic analysis (classifiers do not generalize, concept drift, etc.).
The difficulty at the circumvention side is that there is no way to verify the effectiveness of any proposed traffic obfuscation technique in real-world setting and similarly there is no way to compare their relative effectiveness.
Despite the theoretical trouble I think the current recommendation is to implement any basic packet padding scheme, which will be always better than no padding. More adversarial implementations of detectors of traffic obfuscators may prove useful in measuring the strength of them.
Other rationales
@GreaterFire @micooz @WANG-lp @bosskwei @wongsyrone
The text was updated successfully, but these errors were encountered: