- 統計資料出現頻率(用字典存,key:數字,value:出現次數) (第一次掃描整個資料集)
- 剔除字典內出現頻率(支持度)太低的數字
- 滿足support >= 0.1 (出現次數>=813) 與 confidence>=0.8
- 生成header_table
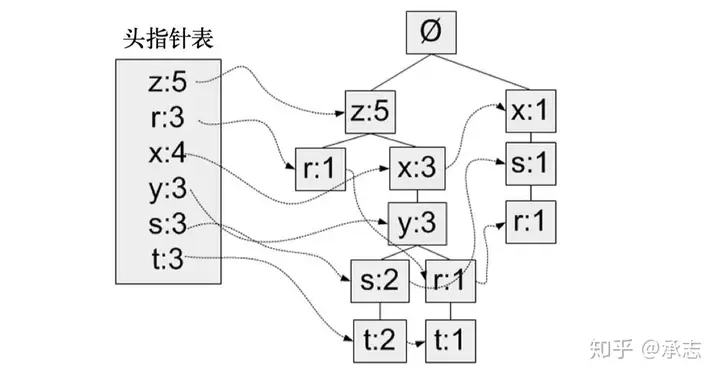
1、2 透過 function filter_unfreq_items 完成 3 透過 function dataset_to_header_table 完成 4 移到生成樹底下
- 將每筆交易集合(每行資料為一交易集合)依照出現頻率排序(根據huffman樹的想法,將出現頻率高的數字盡量往根節點放,加快遍歷時間) (第二次掃描整個資料集)
- 剔除每筆交易集合中,出現頻率太低的數字
- 設定節點物件
- 使用funtion filter_sort_row_data將每筆交易集合進行過濾及按照出現頻率排序(高到低)
1 要處理第一次建立樹時要讀取是檔案,之後跑遞要讀取遞迴是list //要解決之後建樹時傳入的是list,所以不能用readlines() //樹建立的時候應該只需要建一次?
# mushroom.dat跟代碼放到同一個資料夾底下,或是改路徑
# 應該可以更精簡
def filter_unfreq_items(min_freq):
with open('mushroom.dat', 'r') as fp:
dataset = {}
# 統計出現數字頻率,存到字典
for line in fp.readlines():
tmp = line.split(' ')
# del '\n'
del tmp[-1]
for item in tmp:
if item.isdigit() == True:
item = int(item)
if item in dataset:
dataset[item] += 1
else:
dataset[item] = 1
freq_dataset = {}
for i, j in dataset.items():
if j >= min_freq:
freq_dataset[i] = j
return freq_dataset
min_freq = 813
freq_dataset = {}
freq_dataset = filter_unfreq_items(min_freq)
def dataset_to_header_table(dataset):
# value: list[0]:freq,list[1]:NULL pointer
return {i: [j, None] for i, j in dataset.items()}
header_table = {}
header_table = dataset_to_header_table(freq_dataset)
def filter_sort_row_data(row_data, freq_dataset):
filter_data = {}
for item in row_data:
item=int(item)
# 留下出現頻率高的數字
if item in freq_dataset:
filter_data[item] = freq_dataset[item]
sort_dict = {}
# 根據出現頻率由高到低排序
sort_dict = sorted(filter_data.items(), key=lambda x: x[1], reverse=True)
# 回傳排序過的數字list
return [i[0] for i in sort_dict]
row_data = []
with open('mushroom.dat', 'r') as fp:
for line in fp.readlines():
tmp = line.split(' ')
# del '\n'
del tmp[-1]
row_data = filter_sort_row_data(tmp, freq_dataset)
# print(row_data)
class Node:
def __init__(self, item, freq, father):
self.item = item
self.freq = freq
self.father = father # father節點指標
self.ptr = None # 定義指標
self.children = {} # children節點,用dict儲存,方便根據item查詢
# 更新頻次
def update_freq(self):
self.freq += 1
# 新增children
def add_child(self, node):
self.children[node.item] = node
def create_FP_tree(header_table, min_freq):
freq_dataset = filter_unfreq_items(min_freq)
root = Node('Null', 0, None)
with open('mushroom.dat', 'r') as fp:
for line in fp.readlines():
tmp = line.split(' ')
del tmp[-1]
# 根據整體出現次數進行排序
row_data = filter_sort_row_data(tmp, freq_dataset)
head = root
# 按照排序順序依次往樹上插入
for item in row_data:
# print(item)
if item in head.children:
head = head.children[item]
else:
new_node = Node(item, 0, head)
head.add_child(new_node)
# 頭指標指向的位置為空,那麼我們直接讓頭指標指向當前位置
if header_table[item][1] is None:
header_table[item][1] = new_node
else:
# 否則的話,我們將當前元素新增到連結串列的末尾
insert_table(header_table[item][1], new_node)
head = new_node
head.update_freq()
return root
def up_forward(node):
path = []
while node.father is not None:
path.append(node)
node = node.father
return path# 過濾樹根
def insert_table(head_node, node):
while head_node.ptr is not None:
head_node = head_node.ptr
head_node.ptr = node
min_freq = 813
freq_dataset = {}
freq_dataset = filter_unfreq_items(min_freq)
header_table = {}
header_table = dataset_to_header_table(freq_dataset)
root = create_FP_tree(header_table, min_freq)