경마 산업은 국내 합법 사행산업의 큰 비중을 차지한다. 그러나 사행성 도박이라는 인식, 타 스포츠 산업에 비해 분석 미미하다.
데이터 분석 모델을 제공하여 정보 활용 극대화, 건전한 국민 여가 스포츠로 인식 개선을 목표로 하고 있다.
연령, 성별, 경주거리, 부담중량, 상금 등 정해진 조건하에서 2두 이상의 말을 달리게 하여 승부를 겨루는 경기에 돈을 걸고 즐기는 성인 레저
별명은 ‘왕들의 스포츠’(Sports of Kings). 결승지점에 도달한 것은 일반적으로 말의 코끝이 결승선을 통과했을 때로 봄
- 단승 : 1등하는 말
- 연승 : 3등 안으로 들어온 말
- 복승 : 순서와 상관없이 1,2등
- 복연승식 : 3등 이내 말 2마리
- 삼복승식 : 순서와 상괎없이 1,2,3등
- 쌍승식 : 순서대로 1,2등
- 삼쌍승식 : 순서대로 1,2,3등
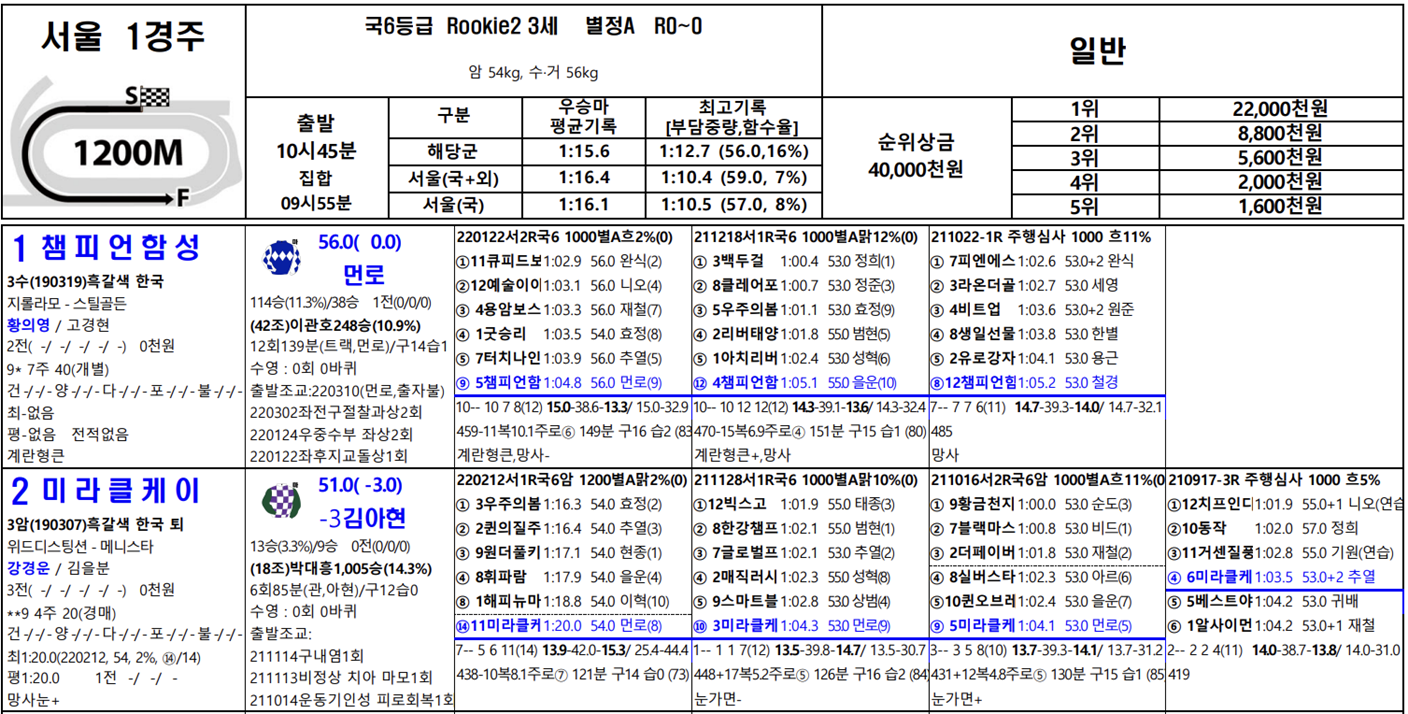
- 한국 마사회 오늘의경주에서 경주 2~3일 전에 출전 마, 기수 등의 정보를 제공
- 출전표, 조교사별 출전 현황, 출전마 장구 사용현황, 종합 정보 제공

-
3등 이내로 들어온 말 (연승) 을 맞추는 모델 생성
-
3등 이내로 들어온 경우는 1 아닌 경우는 0 이기 때문에 분류 (Classication) 모델을 사용해야 함
-
한국마사회에서 제공하는 다양한 데이터와 부모마 수득상금 데이터를 활용한 높은 정확도의 연승 예측 모델 제공
-
본 프로젝트 에서는 가치에 중점을 둔 비즈니스 모델뿐만 아니라, 수익에 중점을 둔 수익 모델의 역할도 목표로 함
2년치 데이터 (2020년 10월 16일 ~ 2022년 09월 25일)의경주 결과, 경주마 정보, 기수 정보, 부모마 수득상금 데이터
-
BeautifulSoup를 이용한 정적 크롤링 으로 경주성적, 기수 데이터 크롤링
-
Selenium을 이용한 동적 크롤링으로 부모마 수득상금, 경주마 데이터 크롤링
크롤링 코드 라인이 매우 많아 따로 링크로 빼둠 : https://github.com/Inhatc-Bigdata-Project/RacingClassificationModel/blob/magnet9805/crawling.ipynb
- 원화 시세는 서울외국환중개(http://www.smbs.biz/) 기준 2019~2021년 평균 환율 데이터
fd feature USD, JPY, AUD, GBP, NZD, RUB, EUR, CAD 포함 행 데이터 가져오기
md feature USD, JPY, AUD, GBP, NZD, RUB, EUR, CAD 포함 행 데이터 가져오기
- 실행 순서
수득상금 종류 별 idx, fd, md 가져와서 외화 제거 후 환율 곱 후 스트링으로 변환 후 sql update 하는 방법
- 아래 코드에 원화 종류, fd, md 변경
2019~2021 년 평균 환율
USD 1163.37 / JPY 10.72 / AUD 827.52 / GBP 1524.88 / NZD 781.07 / RUB 16.66 / EUR 1334.53 / CAD 890.57























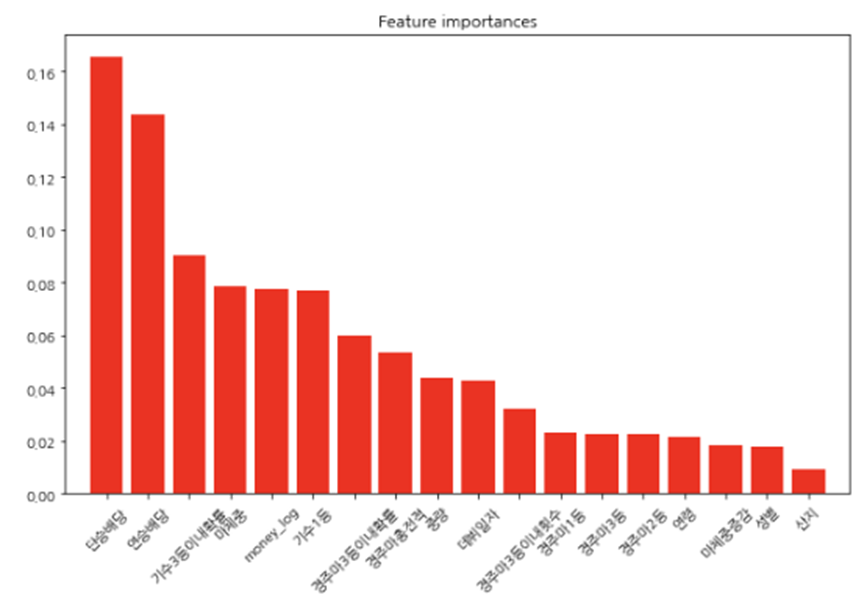
- 변수 선택을 하기에 앞서 이 전 상관관계 시각화 결과 상관관계가 매우 높았던 기수 feature(3등이내 확률, 1등 수 제외)는 이용하지 않음
- 18개의 독립변수 중 변수 선택법을 활용하여 feature 삭제 예정
- 변수 선택 방법으로 총 4가지 방법 사용
- 4가지의 변수 선택 방법에서 랜덤포레스트 정확도가 가장 높은 변수 선택법의 독립변수를 채택







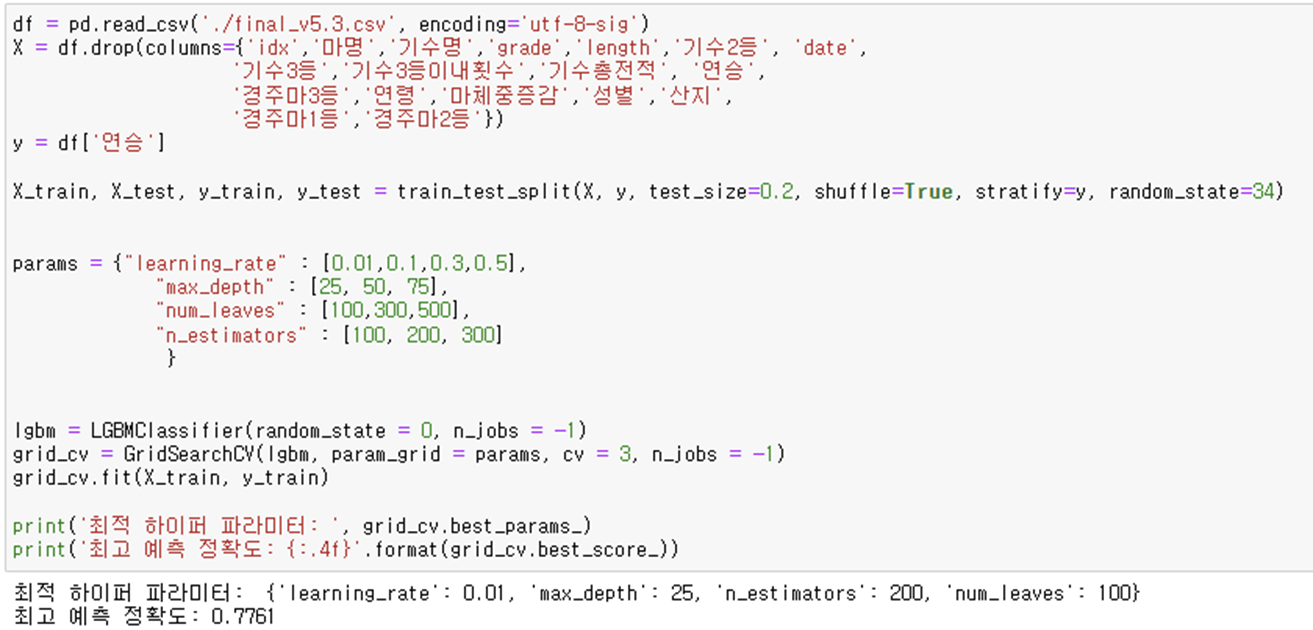
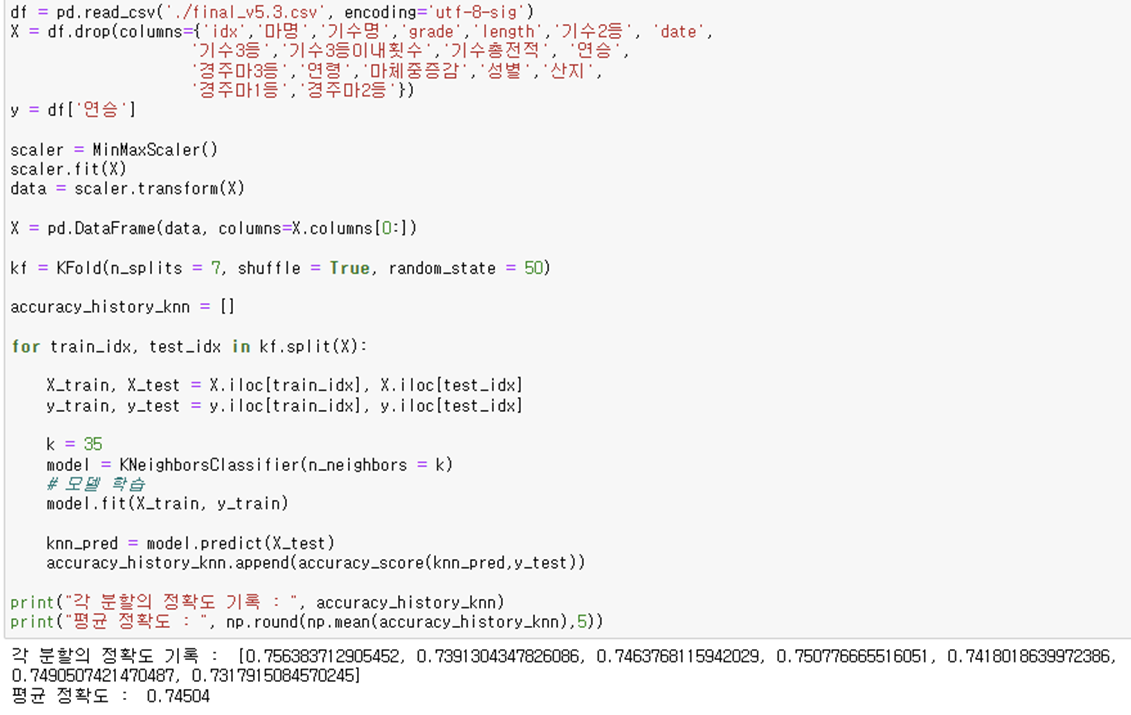
- Random Forest Classifier
- Light Gradient Boosting Model Classifier
- K Neighbors Classifier
- Support Vector Machine Classifier
해당 4가지 분석 모델은 모두 파이썬 scikit-learn 라이브러리를 이용하며 따라서 분석 할 모든 feature를 수치화 해야 함.
모두 분류(Classification) 모델로 연승이냐(1) 아니냐(0) 를 예측하기 위함.


경마 데이터 분석 논문
- https://www.kci.go.kr/kciportal/ci/sereArticleSearch/ciSereArtiView.kci?sereArticleSearchBean.artiId=ART002068008
로지스틱 회귀를 통한 경마의 입상확률모형
- https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE09762520
a href 크롤링
- https://toentoi.tistory.com/43
셀레니움 크롤링
- https://coding-kindergarten.tistory.com/27),
- https://devyurim.github.io/python/crawler/2018/08/13/crawler-3.html
- https://m.blog.naver.com/PostView.naver?blogId=yug311861&logNo=222423444065&targetKeyword=&targetRecommendationCode=1
타이타닉 데이터 분석
- https://dsbook.tistory.com/181
랜덤 포레스트
- https://todayisbetterthanyesterday.tistory.com/51