关键字: 百度股票 爬虫 文件保存
百度股票 URL :https://gupiao.baidu.com/stock/ + sz300059 +.html,其中以 sh 开头的代表上交所挂牌交易的股票,以 sz 开头的代表深交所挂牌交易的股票。
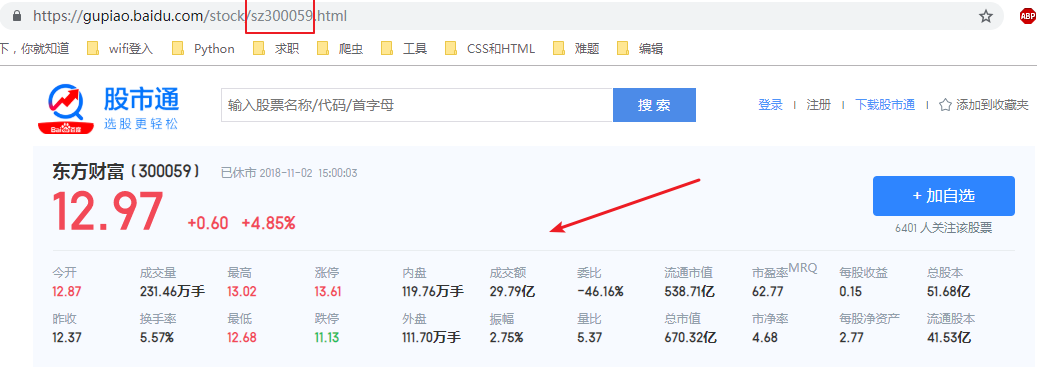
第一步我们要在 东方财富网 爬取类似 sz30059 这样的股票代号:
def getHTML(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""def getStockURL(nameurl, urllist):
html = getHTML(nameurl) #调用HTML下载器
name = re.findall('[s][hz]\d{6}', html)
for item in name:
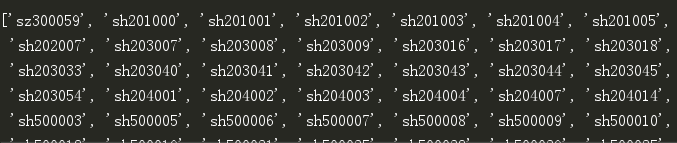
urllist.append("https://gupiao.baidu.com/stock/%s.html" %item)- 从 东方财富网 下载类似
sz30059这样的股票代号,我们调用re库,再用正则表达式[s][hz]\d{6}去完成匹配。
def getStockInfo(urllist, fpath):
for i in range(len(urllist)):
html = getHTML(urllist[i]) #调用HTML下载器
soup = BeautifulSoup(html, "html.parser")
try:
info = {}
title = soup.find_all('a', attrs={'class':'bets-name'})[0]
info.update({'股票名称': title.text.split()[0]}) #初始化股票名称
keylist = soup.find_all('dt')
valuelist = soup.find_all('dd')
lenth = len(keylist)
for i in range(lenth):
key = keylist[i].text
value = valuelist[i].text
info[key] = value
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(info) + '\n')
except:
traceback.print_exc()
continuesoup.find('Tag')返回的是bs4.element.Tag类型。soup.find_all('Tag')返回的是bs4.element.ResultSet类型。soup.find('Tag').children返回的是生成器。trackback库的print_exc()函数可以捕获并打印异常。- 更多
BeautifulSoup信息参考这里:点我
为了让代码不断打印出当前进度,我们可以把这段代码改动一下:
def getStockInfo(urllist, fpath):
count = 0
for i in range(len(urllist)):
html = getHTML(urllist[i]) #调用HTML下载器
soup = BeautifulSoup(html, "html.parser")
try:
info = {}
title = soup.find_all('a', attrs={'class':'bets-name'})[0]
info.update({'股票名称': title.text.split()[0]}) #初始化股票名称
keylist = soup.find_all('dt')
valuelist = soup.find_all('dd')
lenth = len(keylist)
for i in range(lenth):
key = keylist[i].text
value = valuelist[i].text
info[key] = value
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(info) + '\n')
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(urllist)), end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(urllist)), end="")
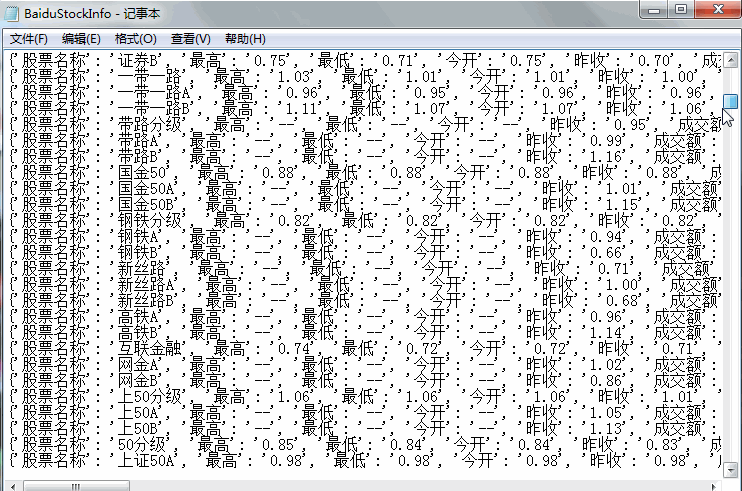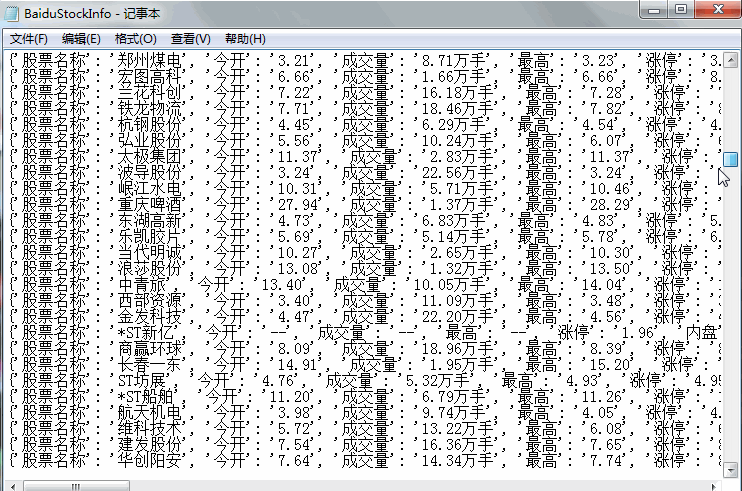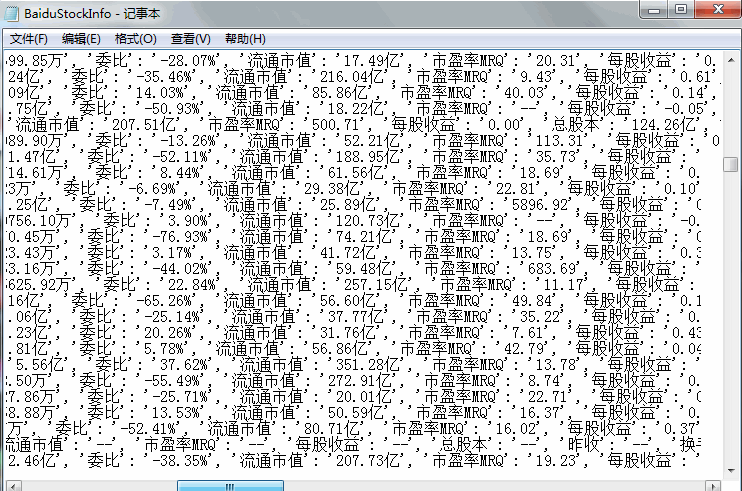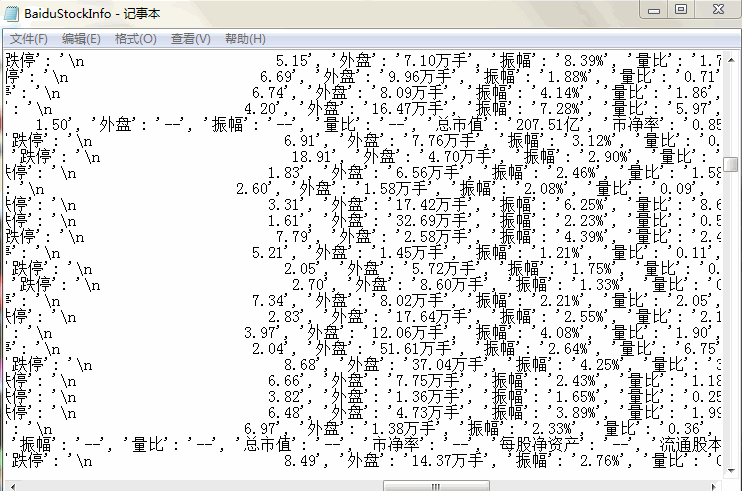
continue最后股票信息会保存在 D 盘的 BaiduStockInfo.txt 中:
import traceback
import requests
import re
from bs4 import BeautifulSoup
def getHTML(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockURL(nameurl, urllist):
html = getHTML(nameurl) #调用HTML下载器
name = re.findall('[s][hz]\d{6}', html)
for item in name:
urllist.append("https://gupiao.baidu.com/stock/%s.html" %item)
def getStockInfo(urllist, fpath):
count = 0
for i in range(len(urllist)):
html = getHTML(urllist[i]) #调用HTML下载器
soup = BeautifulSoup(html, "html.parser")
try:
info = {}
title = soup.find_all('a', attrs={'class':'bets-name'})[0]
info.update({'股票名称': title.text.split()[0]}) #初始化股票名称
keylist = soup.find_all('dt')
valuelist = soup.find_all('dd')
lenth = len(keylist)
for i in range(lenth):
key = keylist[i].text
value = valuelist[i].text
info[key] = value
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(info) + '\n')
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(urllist)), end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(urllist)), end="")
continue
def main():
urllist = []
nameurl = "http://quote.eastmoney.com/stocklist.html"
output_file = 'D:/BaiduStockInfo.txt' #输出地址
getStockURL(nameurl, urllist)
getStockInfo(urllist, output_file)
main()欢迎扫码关注我的公众号:==爬虫小栈==, 一起进步的小栈。
