Reproducing training code #10
Comments
|
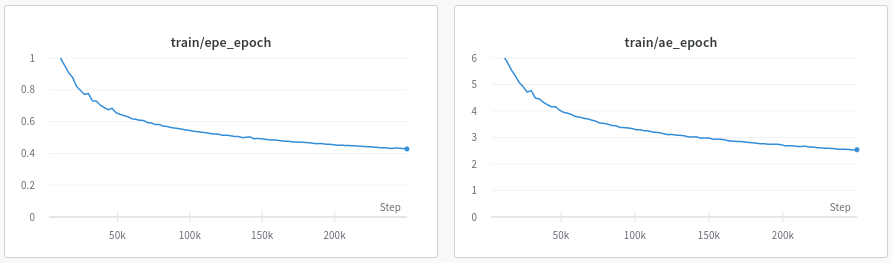
Hi @eugenelyj Sorry for the late reply. I reimplemented the method for a follow-up project and reached pretty much exactly the same performance but using a simpler One-Cycle LR schedule. Specifically, I used a learning rate of 0.0001, 250k steps, batch size of 3. In addition to the cropping you mentioned, I used 50% prob for horizontal flipping and also 10% prob for vertical flipping (have not tested without). These are the training metrics:
Nowadays, I would go with the One-Cycle LR schedule to keep it simple. |
|
@magehrig |
|
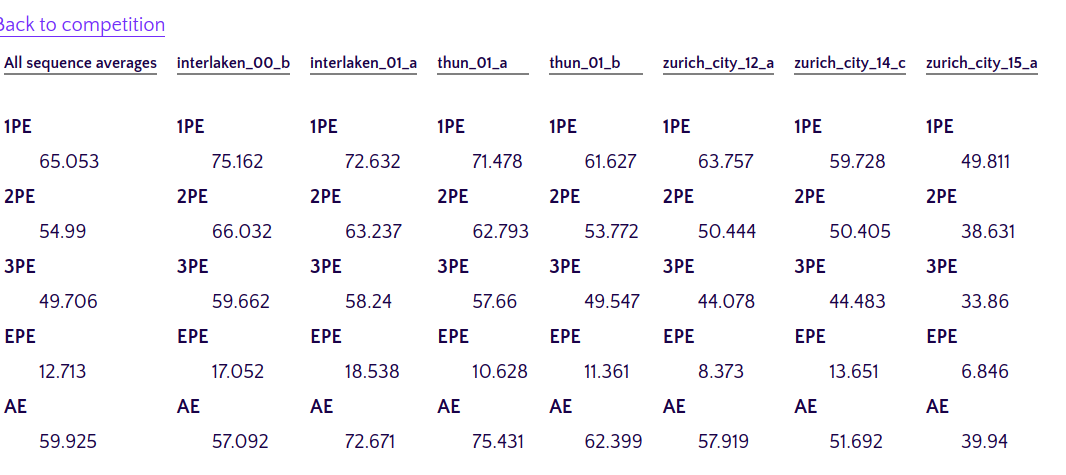
I don't have an evaluation in the loop because I am training on the full training set here. In general, the checkpoint at the last step is performing the best. In this case, the last checkpoint achieves 0.786 EPE and 2.74 AE on the test set. |
|
Actually i also employ One-Cycle LR schedule because my training code is migrated from RAFT. I will re-train once again because some of my settings are different. For example, my batch size is 6 and i ignore the data augmentation of flipping. Thansk for the information. |
|
I still think something else must be wrong with your code, because your training EPE is so high. |
|
@eugenelyj Hi, have you reproduced the results on the benchmark ? |
|
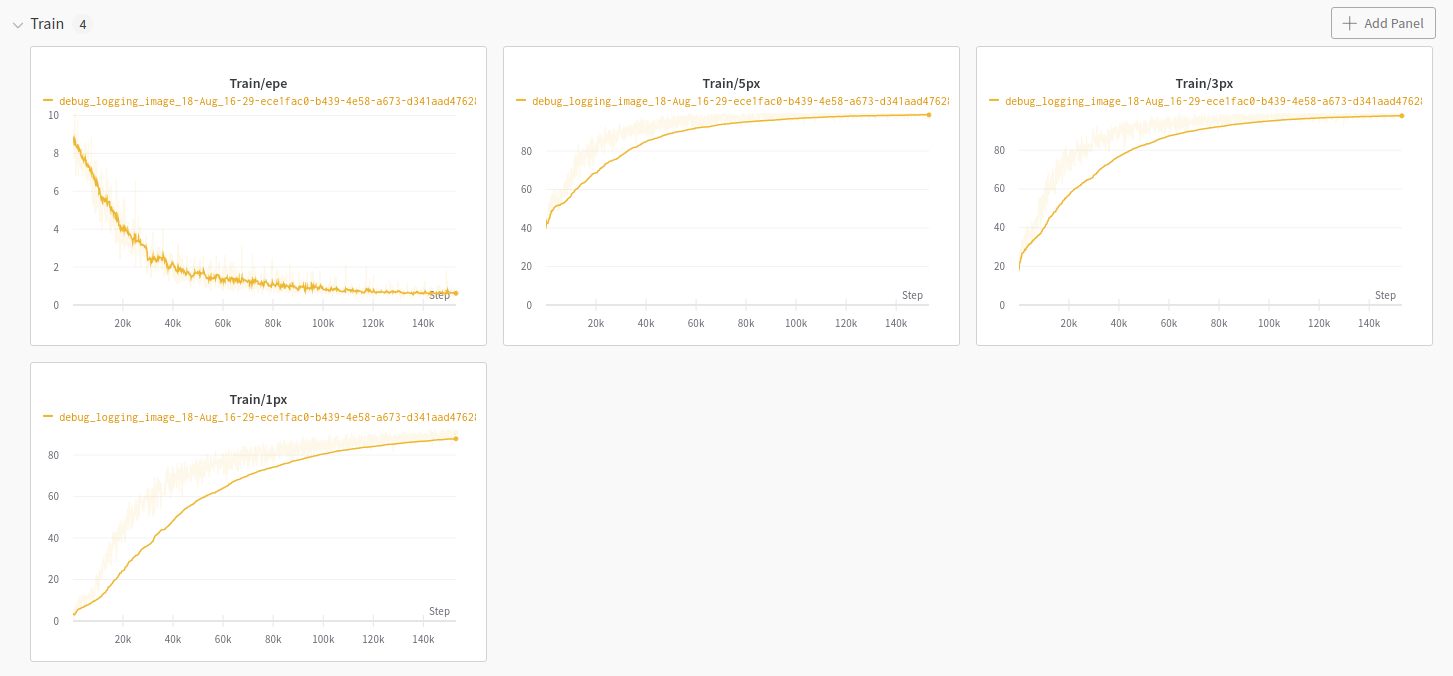
@HTLeoo Some details:
|

|
@magehrig |
|
Are you correctly augmenting the flow labels when flipping? E.g. horizontal flipping -> invert x channel direction, and vertical flipping -> invert y channel? I think wrong data is the most likely explanation for your train-test difference in performance. Such overfitting is basically impossible with this model on this dataset. |
|
@magehrig Thank you, i did mistaken the flow image during data augmentation (that is, forget to modify flow value but only flipping the flow image as what i do to a RGB image). |

Hi,
Thanks for your amazing work!! I am currently trying to reproduce train.py (mainly copy from RAFT project). Some training details are listed as following:
However, the performance is not satisfying even on training set (e.g. 1.207 epe on croped image/events and 2.913 epe on full image/events).
Did this happen to you while training? Looking forward to your reply.
The following are screenshots of my training status. Notice that 1px/3px/5px means the ratio of pixels whose epe is smaller than xx px compared with all valid pixels.
The text was updated successfully, but these errors were encountered: