New function triggers proposal #75
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change | ||||
|---|---|---|---|---|---|---|
| @@ -0,0 +1,198 @@ | ||||||
| <h1>What are Redis Triggers?</h1> | ||||||
|
|
||||||
| Redis triggers are persistent procedures which are executed in response to some keyspace event. Unlike [Redis keyspace Notifications](https://redis.io/docs/manual/keyspace-notifications/) they offer an administrator the ability to place extending logic on simple client operations. Currently redis clients have almost complete ownership of the actions made on the data. The recent addition of [Redis Functions](https://redis.io/docs/manual/programmability/functions-intro/) added the ability to encapsulate logic in a maintainable functions library, thus managing the scope of operations clients are using. According to the function's philosophy, the client will use functions to operate the complete set of actions, making this feature require to migrate the client to use the specific functions and maintain the logic across different function-library versions. Use of functions is also limited to the context of operation initiated by the client, while there are different database related events which are out of any specific client context | ||||||
| (expirations, evictions etc...) | ||||||
| Redis triggers comes to provide the ability to define a specific logic to be executed on a specific keyspace change thus being able to fully own and control the data modifications without requiring the external clients to be aware of the extended logic. | ||||||
| This will allow users to place different actions to follow some keyspace event. | ||||||
| As being integrated in the Redis Functions infrastructure, Triggers are persisted as part of the user data, and replicated. | ||||||
|
|
||||||
| <h2>Can't the same be done with modules?</h2> | ||||||
| Modules have the ability to build logic placed on top of keyspace events. However Modules provide a much more restrictive form of logic which is much harder to implement and dynamically replace. By building this new logic inside the redis function library users will have a much more simple way to create stored procedures which are persistent, managed and replicated. | ||||||
|
|
||||||
| <h2>Triggering Events</h2> | ||||||
|
|
||||||
| Redis already has a feature to report different [keyspace notifications](https://redis.io/docs/manual/keyspace-notifications/) which currently provides the ability to publish keyspace events to registered subscribers. | ||||||
| Redis trigger is basically a function to-be-called whenever a keyspace event is triggered. | ||||||
|
|
||||||
| <h2>Scope of a trigger</h2> | ||||||
|
|
||||||
| Whenever some event triggers an action, we will need this action to be processed in the scope of a specific Redis database and ACL user. | ||||||
|
|
||||||
| <h3>Database context</h3> | ||||||
| Since Redis triggers are built on keyspace events, the DB scope will be the same as the keyspace event was issued on. | ||||||
|
|
||||||
| <h3>ACL User scope</h3> | ||||||
| By default the scope of the user will by the superuser which will not be limited by any authentication restrictions. This makes sense as the triggers might be needed in order to operate a managed operation using some commands which should be otherwise restricted. However in some cases the user might want the trigger to operate under some ACL restrictions. The problem is that triggers might not operate in the scope of a specific external client, so the during trigger registration it will be possible to specifically provide the name of the ACL user to attach to the trigger run context. | ||||||
|
|
||||||
| <h2> Triggers as part of function libraries </h2> | ||||||
| Redis triggers will be implemented as an extension of the Redis 7.0 introduced [Function Libraries](https://redis.io/docs/manual/programmability/functions-intro/) . | ||||||
| A trigger is basically a Redis function which will be called when some specific keyspace event was issued. | ||||||
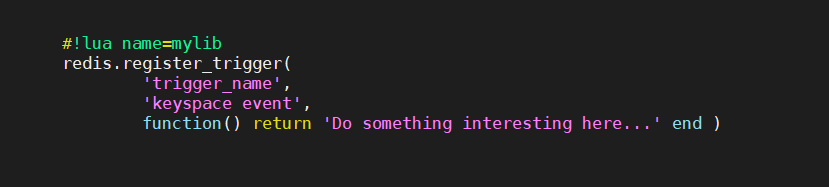
| in order to register a specific function as trigger, one will simply have to use the new **"register_trigger"** redis API which will be available for the different library engines. | ||||||
| For example for the (currently only) LUA engine the registration code will look like: | ||||||
|
|
||||||
|  | ||||||
|
|
||||||
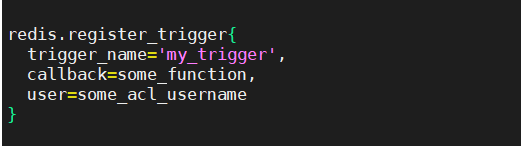
| <h3>Register trigger with named arguments form</h3> | ||||||
| In order to provide some extra arguments to the trigger, the new API will also support the named arguments form. | ||||||
| For example: | ||||||
|
|
||||||
|  | ||||||
|
|
||||||
| <h2>The Trigger code block</h2> | ||||||
| As stated before, a trigger is basically a specific engine function. | ||||||
| The function synopsis will be identical for all triggers which will get the following parameters: | ||||||
|
|
||||||
| **a. key -** the key for which the event was triggered | ||||||
|
|
||||||
| **b. event -** a string specifying the specific event (ie. “expire ”, “set”, “move”, “store” etc...) | ||||||
|
|
||||||
| **c. db -** the id of the db context for which the event is triggered (note it is not necessarily the current db scope the trigger is executed in, ie. MOVE event). | ||||||
|
|
||||||
| For LUA engine based functions, The key will be supplied as the first argument in the keys array (eg KEYS[1]) | ||||||
| The **event** and **db** will be supplied in the ARGS array respectively (event will be provided as ARGS[1] and db as ARGS[2]) | ||||||
|
|
||||||
| <h2>Some Trigger usecases</h2> | ||||||
| Much like scripts and functions, Redis triggers can be used to extend the logic of any atomic Redis command. However since Redis triggers can also be placed on internal out-of-context events like key expiry, and eviction, it can also be used to implement time based actions like implementing timers and scheduled tasks. Lets view some sample trigger based implementation examples: | ||||||
|
|
||||||
| <h3>Stream Keyspace notifications</h3> | ||||||
| It has been long discussed to provide a way to emit keyspace events to redis streams. | ||||||
| Triggers can provide this ability in a very straightforward way. For example, consider the following function library: | ||||||
|
|
||||||
|  | ||||||
|
|
||||||
| In this implementation we will capture each keyspace event and place the relevant key name and event on a dedicated stream called | ||||||
| "keyevent-notifications". | ||||||
|
|
||||||
| ``` | ||||||
| > set a b | ||||||
| OK | ||||||
| > lpush mylist f | ||||||
| (integer) 1 | ||||||
| > xread streams keyevent-notifications 0 | ||||||
| 1) 1) "keyevent-notifications" | ||||||
| 2) 1) 1) "1678974201461-0" | ||||||
| 2) 1) "a" | ||||||
| 2) "new" | ||||||
| 2) 1) "1678974201461-1" | ||||||
| 2) 1) "a" | ||||||
| 2) "set" | ||||||
| 3) 1) "1678974210181-0" | ||||||
| 2) 1) "mylist" | ||||||
| 2) "new" | ||||||
| 4) 1) "1678974210181-1" | ||||||
| 2) 1) "mylist" | ||||||
| 2) "lpush" | ||||||
| ``` | ||||||
|
|
||||||
| <h3>Scheduled tasks</h3> | ||||||
| Another commonly used Redis pattern is scheduled tasks. | ||||||
| In such cases user usually register tasks in a ZSET with the matching executing time as the score. | ||||||
| Usually what is being done is setting a puller job in the application side which periodically reads all items in the set which has score smaller than the current timestamp, and issue an eval/fcall back to redis with the relevant task to run. | ||||||
| This pattern introduce some waste as the application needs to maintain a puller job and perform the roundtrip back to the application in order to execute the scheduled operations. | ||||||
| With Redis triggers this can be achieved without the need to place a puller job by the user. | ||||||
| In order to achieve that we can use: | ||||||
| - ZSET z for for holding scheduled tasks | ||||||
| - Key k to manage the next task execution time | ||||||
|
|
||||||
| The external application code will only have to add tasks to the ZSET **z** with score matching their required execution time. | ||||||
| 1. once the task is added to **z** a trigger code will be executed which will take the minimal score from the ZSET **z**, and apply the diff to the current time to the TTL of key **k**. | ||||||
| 2. once key **k** has expired, a trigger will be executed which will remove and execute all the tasks from the zset **z** | ||||||
|
|
||||||
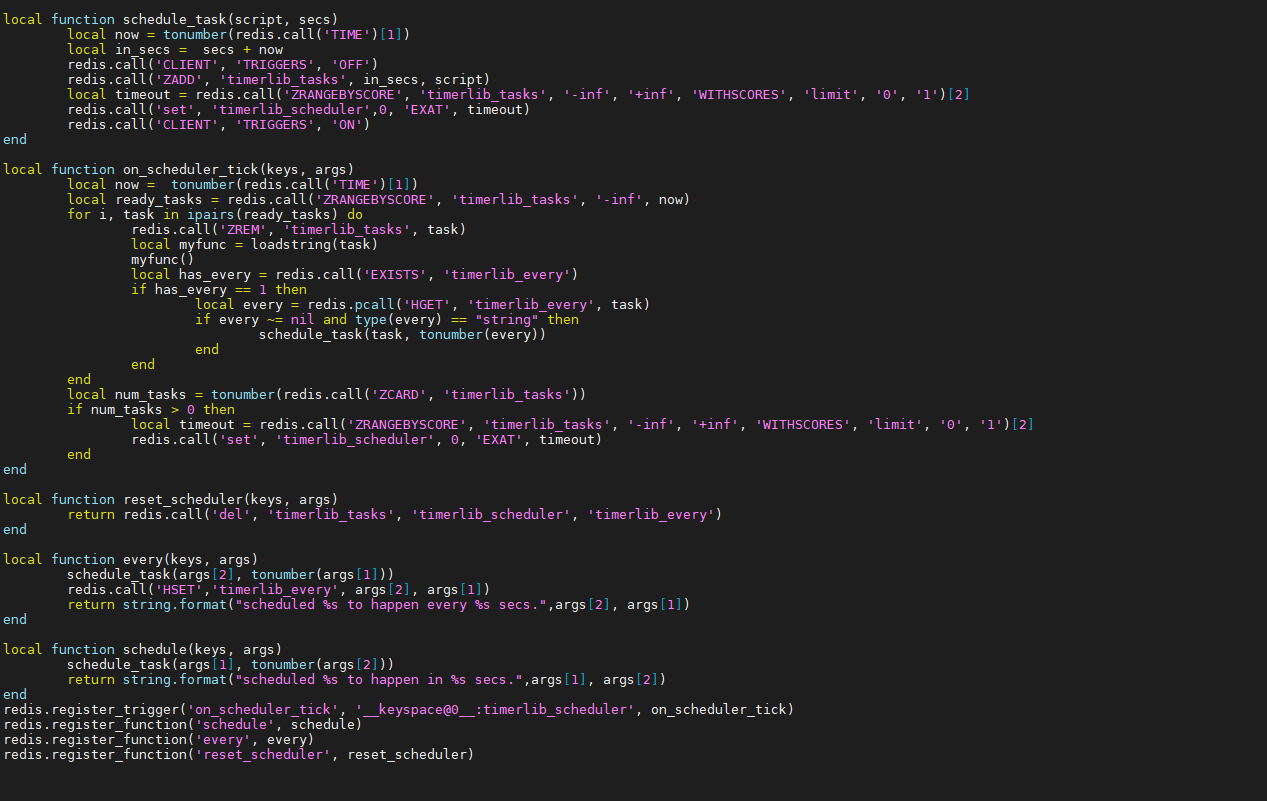
| Here is an example library code to schedule tasks to be executed after/every several seconds | ||||||
|
|
||||||
|  | ||||||
|
|
||||||
| So in order to use them the user can simply register operations to be triggered: | ||||||
|
|
||||||
| ``` | ||||||
| fcall schedule 0 'redis.call("PUBLISH", "scheduled", "this is a msg from the past")' "3" | ||||||
| ``` | ||||||
| Will cause publish of a msg after 3 seconds from the time the fcall was processed. | ||||||
|
|
||||||
| ``` | ||||||
| fcall every 0 "3" 'redis.call("PUBLISH", "scheduled", "this is an annoying msg")' | ||||||
| ``` | ||||||
| Will cause the specified message to be published every 3 seconds. | ||||||
| Note that the same concept can be used to implement HASH members eviction! | ||||||
|
|
||||||
|
|
||||||
| <h2>Atomicity of triggers</h2> | ||||||
| Like all keyspace events, triggers will be executed as part of the operation which triggered them. However, since the triggers are set to be executed when the keyspace event has been triggered, Many issues can be caused by having a write call performed in the middle of operating another command. [This PR](https://github.com/redis/redis/pull/11199) was issued to address the same issue with modules performing write operations on keyspace events. We suggest following the same logic as modules and share the same notification mechanism, to operate the trigger operation during the unit operation completion. | ||||||
|
|
||||||
| <h3>SUGGESTION</h3> | ||||||
|
|
||||||
| Although it makes sense that all the aggregated triggering events will be processed after the "atomic" execution was completed (transaction, script or function call) this does impose some limitation on the Redis trigger since it will operate on a newer version of the keyspace than at the point of the keyspace event was triggered. | ||||||
| We could consider an option to always execute the trigger right after each Redis command was completed, even if it was issued from | ||||||
| a nested context. | ||||||
| The main challenge with this option is to have a nested script calls which is currently not allowed in Redis. | ||||||
| During the development of a preliminary PoC I was able to overcome this limitation by storing the current script context (and the current LUA state in case of LUA engine) and restore them back once processing the triggers execution. | ||||||
| I think that we could explore the option to have triggers execution after each executed command rather than after the complete atomic execution has been completed. | ||||||
|
|
||||||
|
|
||||||
| <h2>Can trigger trigger trigger?</h2> | ||||||
|
|
||||||
| We do not want to reach a nested call of triggers and a potential endless loops. According to this design a trigger execution as a result of some keyspace event is a terminal state. | ||||||
|
There was a problem hiding this comment. On the one hand, allowing execution of one trigger to cause execution of another trigger leads to a variety of problems, including endless loops. On the other hand, my previous experience with triggers in other environments taught me that one of the biggest values of triggers was the ability to think about the system in a declarative manner, instead of an imperative manner. For example, trigger T1 could promise that every LPUSH operation on key JOBS would be accompanied by an LPUSH on key LOG, where the data pushed onto LOG included a timestamp and the user's ID. Trigger T2 could promise that the key LOG_TOO_LONG would be set to TRUE exactly when LLEN LOG > 1000. But this only works if T1 can trigger T2. This area deserves a lot of detailed analysis. |
||||||
| we could keep some recursion depth counter that will stop triggering once it reaches some depth, but that would cause some unexpected behavior for the library developers, and difficulty debugging cases where triggers where not executed. | ||||||
| Another important aspect to consider is if modules based keyspace events calbacks should be triggered from trigger actions and vice versa. | ||||||
| In the scope of this document I will assume that the trigger based actions **WILL NOT** cause matching module calbacks to be called and that module actions performed during it's callback operation **WILL NOT** cause triggering triggers, but each will be executed only in 1 level of nesting. | ||||||
|
|
||||||
| So for example lets say I have a module callback **cb** set on some keyspace event **e1** and a trigger action **t** registered on some event **e2**. | ||||||
|
|
||||||
| when the event **e1** is issued the **cb** will be executed and will cause event **e2** which will **NOT** trigger **t**. | ||||||
|
|
||||||
| Also in case **e2** is issued the **t** is being executed and cause event **e1** which will **NOT** trigger **cb**. | ||||||
|
There was a problem hiding this comment. When a module depends on a callback, this will break the module. There was a problem hiding this comment. It seems to me that we need to choose between a super-safe approach, which will greatly limit what triggers can do, and a super-dangerous approach, which allows triggers to do anything and demands great caution when using them. This feels like the same choice we make between a language like Java and one like C. (Or between using a butter knife and a chain saw. Most of the time I want my knives to be as sharp as possible.) It strikes me as very confusing if we pick something in the middle. What do others want? A bike with or without training wheels? Safety or power? Many of our later decisions will flow from this basic principle. |
||||||
|
|
||||||
|
|
||||||
| <h2>Triggers observability</h2> | ||||||
|
|
||||||
| <h3>Listing existing Triggers</h3> | ||||||
| The **FUNCTION LIST** command output will now include a new part named "triggers". | ||||||
| Much like functions the triggers part will describe a per-trigger information: | ||||||
|
|
||||||
| ``` | ||||||
| "library_name" | ||||||
| "mylib" | ||||||
| "engine" | ||||||
| "LUA" | ||||||
| "functions" | ||||||
| 1) "name" | ||||||
| 2) "myfunc" | ||||||
| 3) "description" | ||||||
| 4) <some description> | ||||||
| 5) "flags" | ||||||
| 6) <relevant flags> | ||||||
| "triggers" | ||||||
| 1) "name" | ||||||
| 2) "trigger_name" | ||||||
| 3) "event" | ||||||
| 4) "__keyspace@0__:*" | ||||||
| 7) "calls" | ||||||
| 8) "<the total number of times the trigger has called>" | ||||||
| 9) "errors" | ||||||
| 10) "<the total number of errors issued during this trigger run>" | ||||||
| 11) "total_duration" | ||||||
| 12) <the aggregated total duration time this trigger run> | ||||||
| ``` | ||||||
|
|
||||||
| <h3>general statistics</h3> | ||||||
| The "Stats" info section will be added with the following statistics: | ||||||
| **total_trigger_calls -** the number of general tri9gger calls. this will not be a teardown list of calls per trigger function (this can be taken from the function list command as will be explained later) | ||||||
|
There was a problem hiding this comment.
Suggested change
|
||||||
| **total_trigger_errors -** The total number of errors during trigger execution. (an error is accounted for each time the afterErrorReply is called) | ||||||
| **total_trigger_duration -** The total time spent running trigger related code. | ||||||
|
|
||||||
| <h3>Per trigger statistics</h3> | ||||||
| The same global statistics will be available on a per-trigger resolution: | ||||||
| "calls" - the total number of times the trigger has called | ||||||
| "errors" - the total number of errors issued during this trigger run | ||||||
| "total_duration" - the aggregated total duration time this trigger run | ||||||
|
|
||||||
| <h3>NOTES regarding statistics</h3> | ||||||
| 1. although these statistics are outlined only with regards to triggers, we can extend the same to Redis functions. | ||||||
| 2. Currently only suggesting the most basic statistics. we can extend the satistics to include, for example, max duration , min duration, average time etc... | ||||||
| 4. While the global trigger statistics will be reset when `CONFIG RESETSTAT` is called. the per trigger statistics will not be reset, and will only be refreshed, when function library is being reloaded. | ||||||
|
|
||||||
| <h2>Debugging triggers</h2> | ||||||
| While Redis functions are executed as part of the FCALL, they are reporting the errors back to the calling client. | ||||||
| Triggers, however, are silently executing which makes it hard for the user to understand why the trigger did not work and what errors occurred during execution of the trigger. | ||||||
| The suggestion here is to push every error msg on a predefined pub/sub channel (defined via dedicated configuration), so that interested users can understand the errors which happened during any trigger execution. it is also possible to setup dedicated channel per trigger. | ||||||
|
|
||||||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
What is a redis?