Cinematch is a movie/series recommendation platform uses a cutting-edge machine learning model to personalize movie suggestions based on your interests.
- It uses ML model to recommend moviesand web series based on your preference.
- Allow you to create multiple watchlists according to your mood
- Option to share your watchlists with friends
- Provides related movie/series suggestions based on recent films/series you've watched
- Regularly updated library of films and series to explore
- Discover new movies and series with personalized recommendations tailored to your preferences.
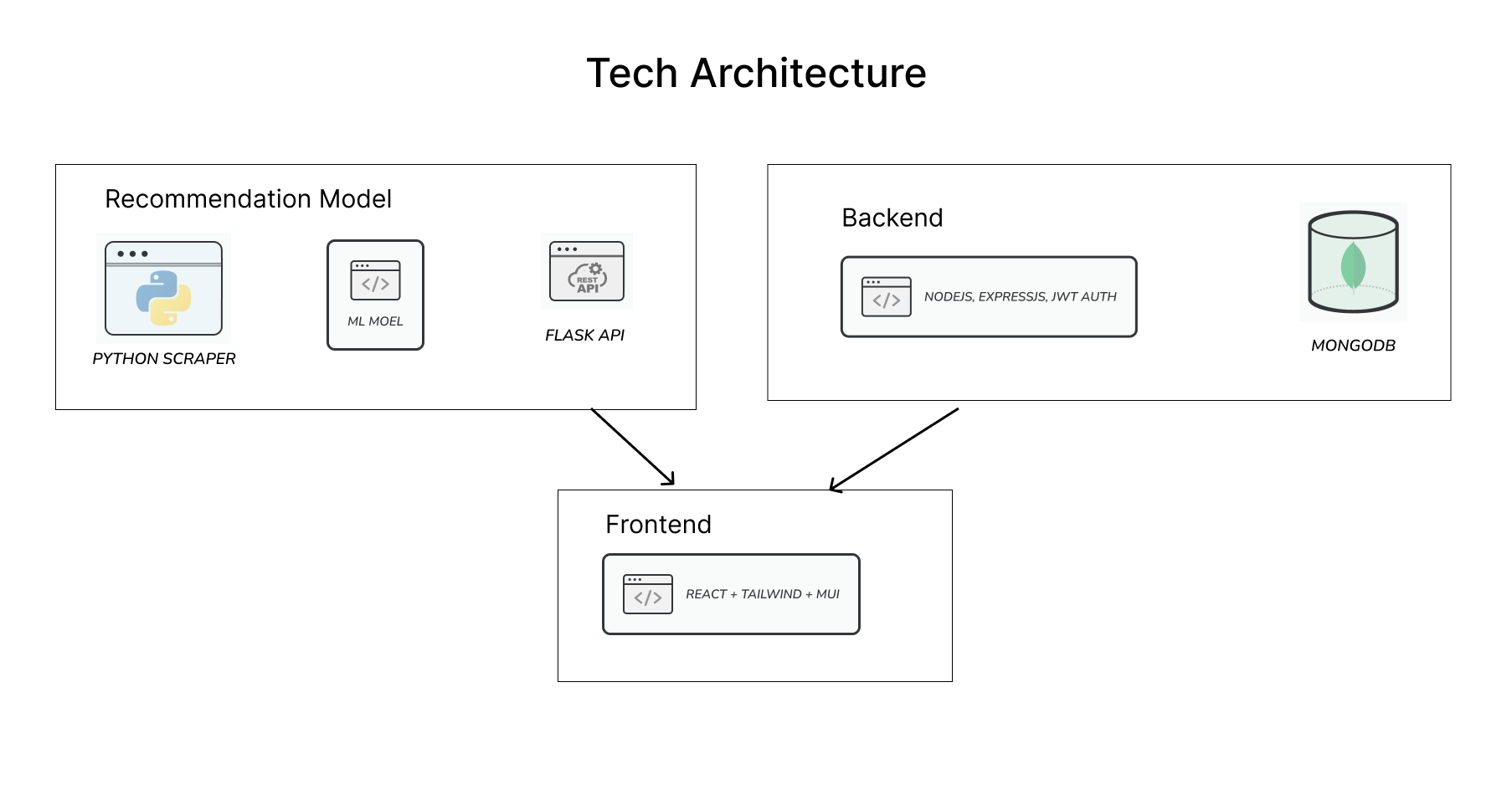
-
This code is used for scraping movie data from the IMDb website. It uses the Python library requests to send GET requests to the IMDb search page, and the library BeautifulSoup to parse the HTML returned by the requests.
-
The script starts by setting the maximum number of pages to scrape (max_tiles) and the base URL for the IMDb search page. It then iterates through a range of page numbers (incrementing by 50 each time) and sends a GET request to the URL with the current page number appended to it.
-
The HTML returned by the request is parsed using BeautifulSoup, and the script looks for specific elements on the page that contain the information we want (such as movie title, year, genre, cast, etc.). The script then retrieves this information and writes it to a csv file, with each row representing a different movie.
-
The script also uses a try-except block to handle any errors that may occur when scraping the data, such as if a specific element is not found on a page.
- Centralized backend to manage all the microservices.
- Routes for auth, follow, unfollow, create llist, get list, profile etc.
- database connection
The process of proposing movies to consumers is called movie recommendation, and it is based on their watching tastes and history. Utilizing cosine similarity is one method of doing this.
- In our Model, We are using CountVectorizer to create a matrix of token counts from a collection of text documents for a movie recommendation. The similarity between the films depending on their genre is then determined using this matrix as input to a similarity measure like cosine similarity. The higher the similarity value, the more similar the movies are considered to be. CountVectorizer is used to create the matrix of token counts by tokenizing the text and counting the number of occurrencesof each token in each document. This allows for a more accurate representation of the text data and more accurate similarity calculations.
- The cosine of the angle between any two non-zero vectors in an inner product space is used to quantify how similar the vectors are. The calculation of text or document similarity is frequently employed in information retrieval andnatural language processing. Cosine similarity may be used to compare moviesbased on its properties, such as genre, narrative, and cas, and to determine how similar various viewers' choices are to one another.

Clone the project
git clone https://link-to-projectGo to the project directory
cd Cinematch/BackendInstall dependencies
npm installStart the server
npm run devGo to the project directory
cd CineMatch/FlaskApiInstall dependencies
pip install requirements.txtStart the server
python app.pyGo to the project directory
cd CineMatch/FrontendInstall dependencies
npm installStart the server
npm run dev