
House Loan Prediction (Python)
Jupyter Notebook: Model EDA, Training and Testing
Object Oriented Programming: .py file
Dream Housing Finance company provides mortgage lending solutions to home buyers. Using this partial dataset, the company wants to automate the loan eligibility process based on customer information upon submission of the online application and determine whether person will be approved for loan or not. These details include Gender, Marital Status, Education, Number of Dependents, Income, Loan Amount, Credit History and others. To this end, I'll explore three classification models in this notebook and demonstrate how to deal with imbalanced class problem.
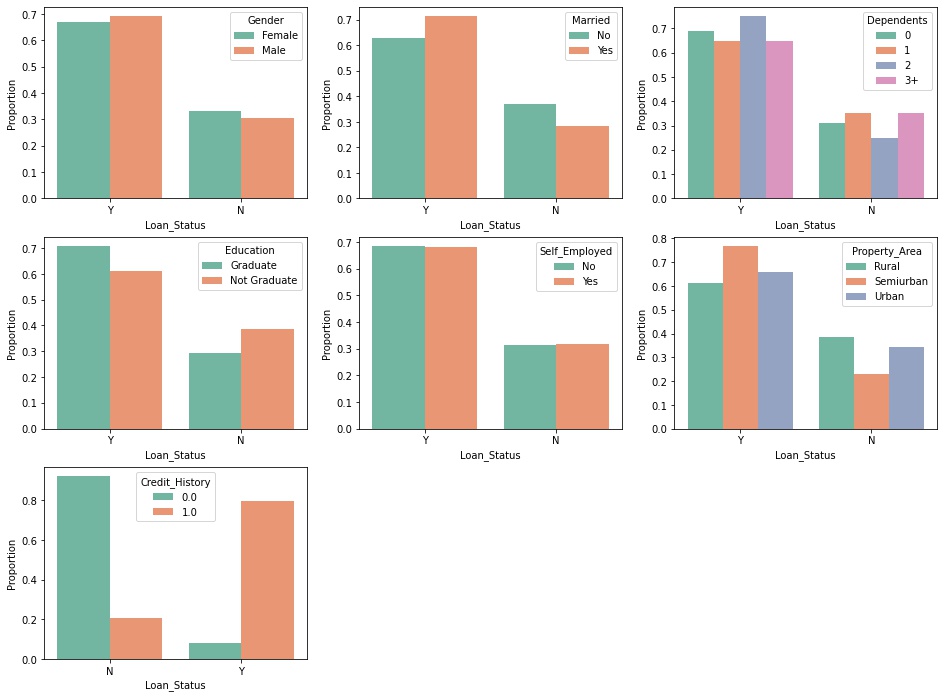
Summary
- distribution of values for each categorical feature are close given the loan status class labels!
- credit history seems to have an explanatory power because
- vast majority (95%+) of rejected applications have no credit history
- approximately, 80% of approved applications have a prior credit history
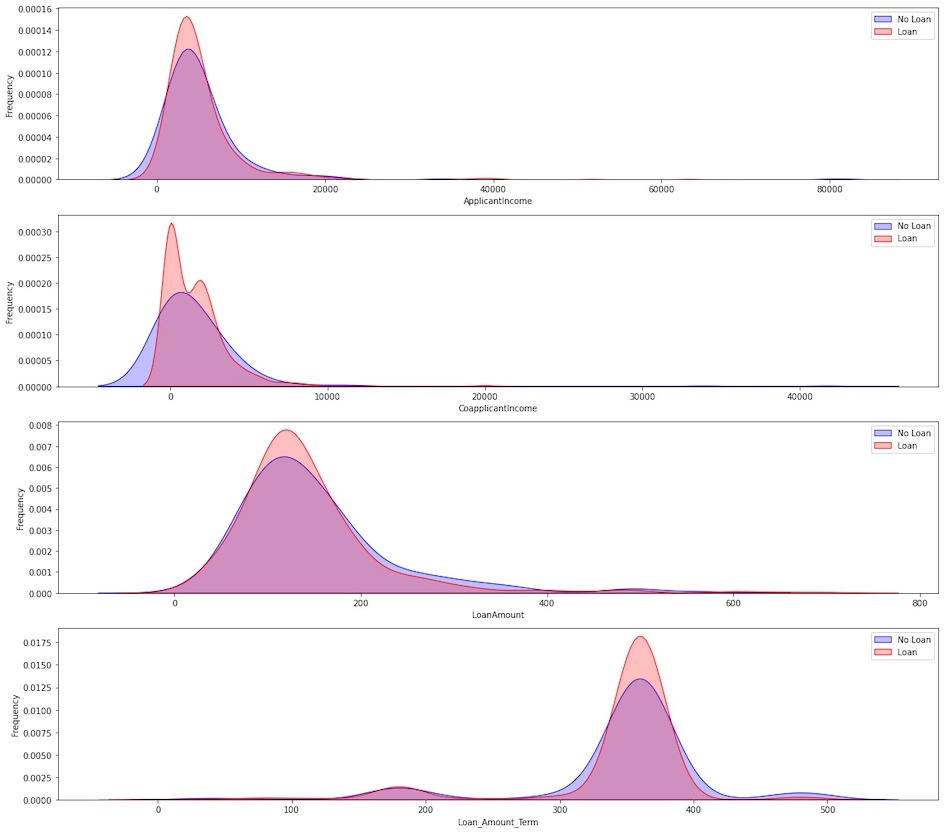
Summary:
- Distributions are skewed to the left and right suggesting many outliers. Coapplicantincome and Loan_Amount_Term have bimodal distributions.
- Average Applicant Income for approved and rejected loans are about the same.
- Those who are approved had either zero or ~ 2500 of Coapplicant income.
- Requested loan amounts for approved and rejected loans are equal on average
- Loan applications are either for 180 or 360 months term.
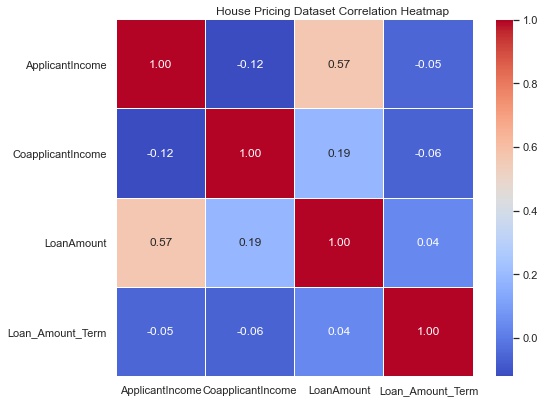
Summary
- There is no collinearity between the features
- Highest correlation coefficient is 0.57 between the Loan Amount and Applicant Income which makes sense.
I will use ROC-AUC classifcation metric, thus, I will develop DummyClassifier to predict a stratified random class.
dummy_clf = DummyClassifier(strategy="stratified", random_state=1)
dummy_clf.fit(X_train, y_train)
roc_auc_score(y_test, dummy_clf.predict_proba(X_test)[:, 1])
I'll explore the following three classifiers to predict loan eligibility
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(random_state=1)
First, we need to deal with the class imbalance of 69% (Y) and 31% (N) before diving into model development process.
Y 0.687296
N 0.312704
Name: Loan_Status, dtype: float64
To this end, I'll use the imblearn package to apply oversampling (i.e., SMOTE) and undersampling (i.e, RandomUnderSampler) techniques:
Original dataset shape Counter({1: 337, 0: 154})
Oversampled dataset shape Counter({1: 337, 0: 337})
Undersampled dataset shape Counter({0: 154, 1: 154})
I built a base Logistic Regression model and determined that SMOTE technique results in better performance compared to other two techniques.
Based on the 5x2CV nested cross-validation, Random Forest Classifier seems to be performing the best. However, there is some overfitting.
Fitting 5 folds for each of 5 candidates, totalling 25 fits
ROC-AUC 0.90 (average over k-fold CV test folds)
Best Parameters: {'n_estimators': 10000}
Training ROC-AUC: 1.00
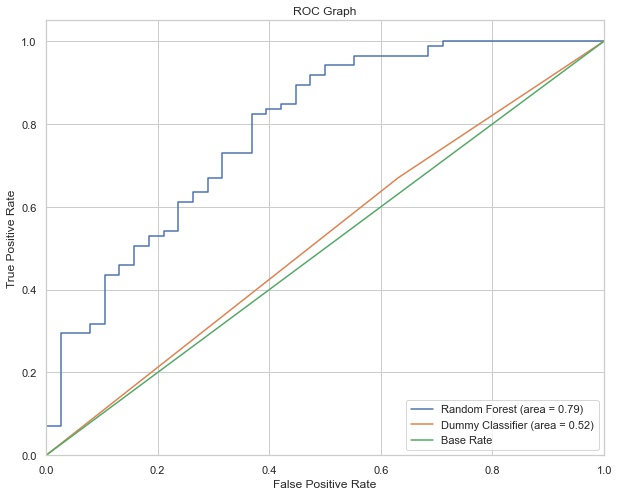
Test ROC-AUC: 0.79
Below ROC graph shows an 52% improvement compared to baseline Dummy Classifier in terms of the AUC score.
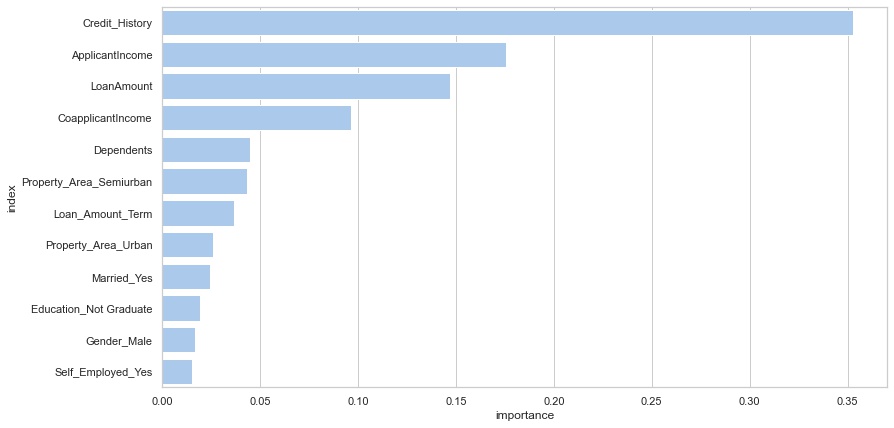
According to the feature importance graph top four features are Credit History, ApplicantIncome, LoanAmount and CoapplicantIncome.
I can also optimize a different metric such as Recall or Precision. It depends on how much cost/weight we want on two types of errors: (1) False Positives or (2) False Negatives. What's the cost of having a FN and FP? Do we want to value loss due to revenue or loss due to mortgage default more? This is a business and setting specific goal.
Optimize Recall When:
- You want to limit false negatives
- FN > FP
Optimize Precision When:
- You want to limit false positives
- FP > FN
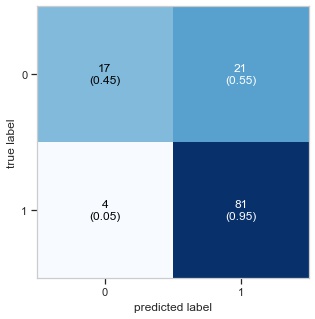
Given the confusion matrix, there seem to be more false negatives than true negatives, so it might be worthwhile to optimize the Recall, provided that mortgage defaults are of concern.
As a future work, I can do feature engineering and use a different hyperparameter tuning technique (e.g., Random Search or Bayesian Optimization) which can potentially result in better classification model. In addition to ROC-AUC, I can optimize model performance with respect to Recall and Balanced Accuracy scores. Finally, I can try stacking several classifiers in an aim to improve the model accuracy.