Support the lang="ja" attribute
#170
Labels
enhancement
New feature or request
Comments
shuding
pushed a commit
that referenced
this issue
Jan 7, 2023
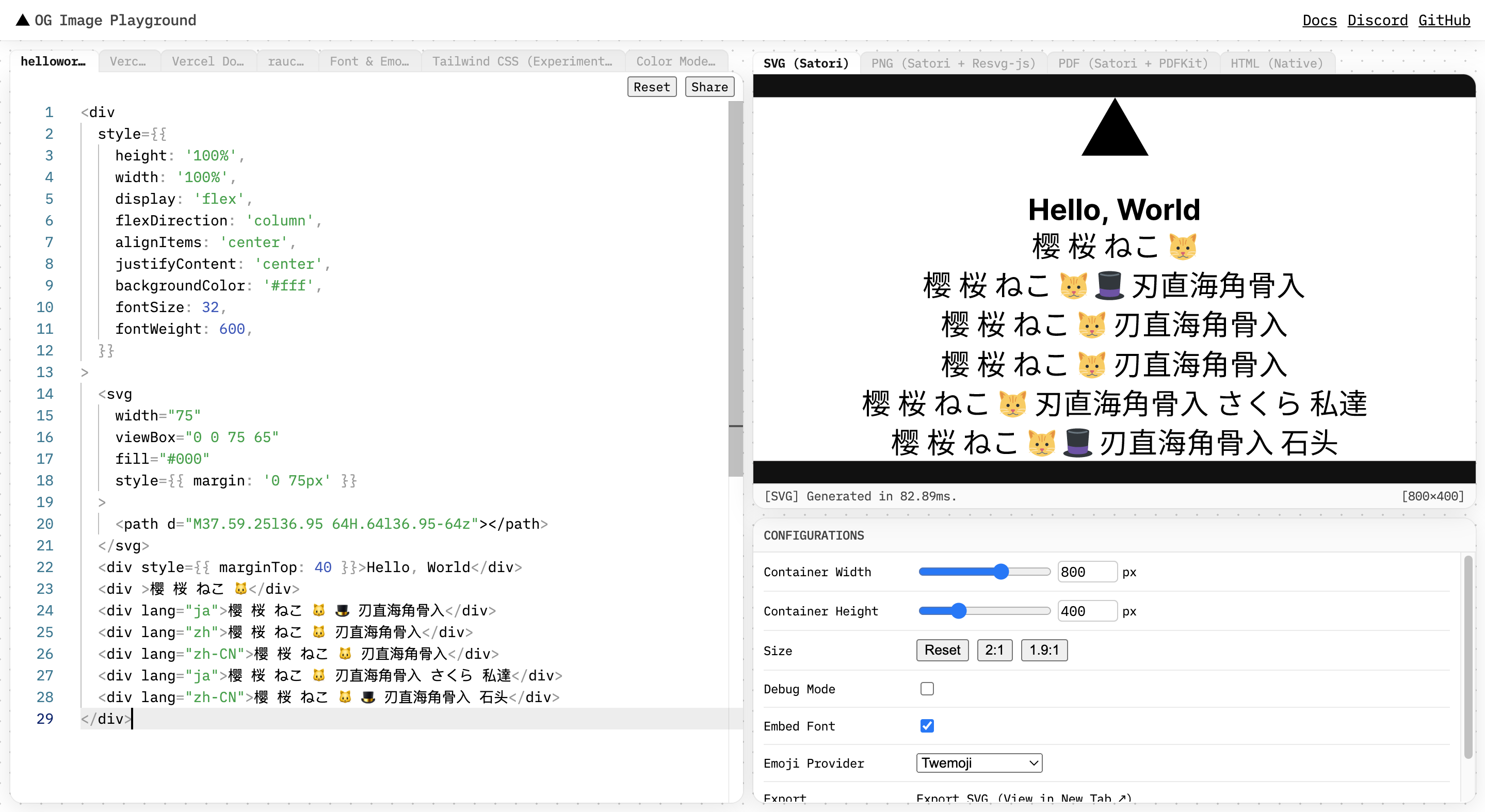
### Description Support the `lang="ja"` attribute. 1. For those words with the same Unicode Code Point but different glyphs (in different languages), different glyphs need to be displayed according to the lang attribute. Such as `刃直海角骨入`. 2. Chinese characters (e.g. `樱`) can also be displayed correctly (through safe fallback) under the label with lang="ja" set. 3. Japenese kanji (e.g. `桜`) can also be displayed correctly (through safe fallback) under the label with lang="zh" set. Because we can't distinguish Chinese hanzi and Japanese kanji by regex, this PR uses some tricky codes when implementing the above feature. So I'm wondering if I need to do this. Are there two other straightforward implementations below that might look better? 1. Give up displaying hanzi when the user sets lang="ja". 2. We download all possible languages when we need to download hanzi(kanji). What do you think? 🤔 ### Additional <img width="1439" alt="image" src="https://user-images.githubusercontent.com/22126563/199142248-05487041-6086-493c-a472-34af5aa75c64.png"> Closes: #170
{kind=link}
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Feature Request
Description
Additional Context
https://heistak.github.io/your-code-displays-japanese-wrong/
https://twitter.com/mandel59/status/1579647588936355841
The text was updated successfully, but these errors were encountered: