This project is regarding generating the title and summary from the input paragraph. In this we have used T-5 Model which is text to text generation model.
The title and summary are being generated from pre-trained models.
For Title Generation we have used hugging face model: deep-learning-analytics/automatic-title-generation
For Summary Generation we have used hugging face model: sshleifer/distilbart-cnn-12-6
T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a different prefix to the input corresponding to each task, e.g., for translation: translate English to German: …, for summarization: summarize: ….
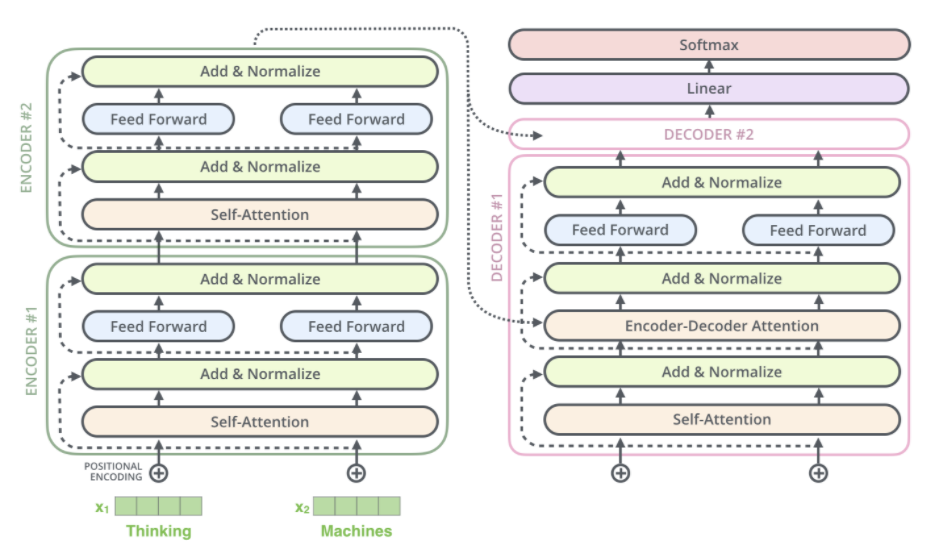
Training T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher forcing. This means that for training, we always need an input sequence and a corresponding target sequence. The input sequence is fed to the model using input_ids. The target sequence is shifted to the right, i.e., prepended by a start-sequence token and fed to the decoder using the decoder_input_ids. In teacher-forcing style, the target sequence is then appended by the EOS token and corresponds to the labels. The PAD token is hereby used as the start-sequence token. T5 can be trained / fine-tuned both in a supervised and unsupervised fashion.
One can use T5ForConditionalGeneration (or the Tensorflow/Flax variant), which includes the language modeling head on top of the decoder.
In this setup, spans of the input sequence are masked by so-called sentinel tokens (a.k.a unique mask tokens) and the output sequence is formed as a concatenation of the same sentinel tokens and the real masked tokens. Each sentinel token represents a unique mask token for this sentence and should start with <extra_id_0>, <extra_id_1>, … up to <extra_id_99>. As a default, 100 sentinel tokens are available in T5Tokenizer.
In this setup, the input sequence and output sequence are a standard sequence-to-sequence input-output mapping. Suppose that we want to fine-tune the model for translation for example, and we have a training example: the input sequence “The house is wonderful.” and output sequence “Das Haus ist wunderbar.”,
- Make a
virtual environment. - Install all the packages of
requirements.txt - Make
srcas your working directory - Run the file
app.py
- Make virtual environment using
python3 venv {virtial env name} - Activate virtual environment using
source {virtial env name}/bin/activate - Run app.py in src folder
python3 app.py
If you are running this project using docker make sure change the path of title and summary model as: resources/summary_token
http://127.0.0.1:5001