{kind=link}
arXiv link: https://arxiv.org/abs/2305.17080
Authors:
Yung-Sung Chuang,
Wei Fang,
Shang-Wen Li,
Scott Wen-tau Yih,
James Glass
To be published in ACL 2023 (findings)
Pre-trained models can be downloaded here: https://drive.google.com/file/d/1ueepl7Yh2RFThH_tcuoK8rkOHaWBUsGJ/view?usp=sharing
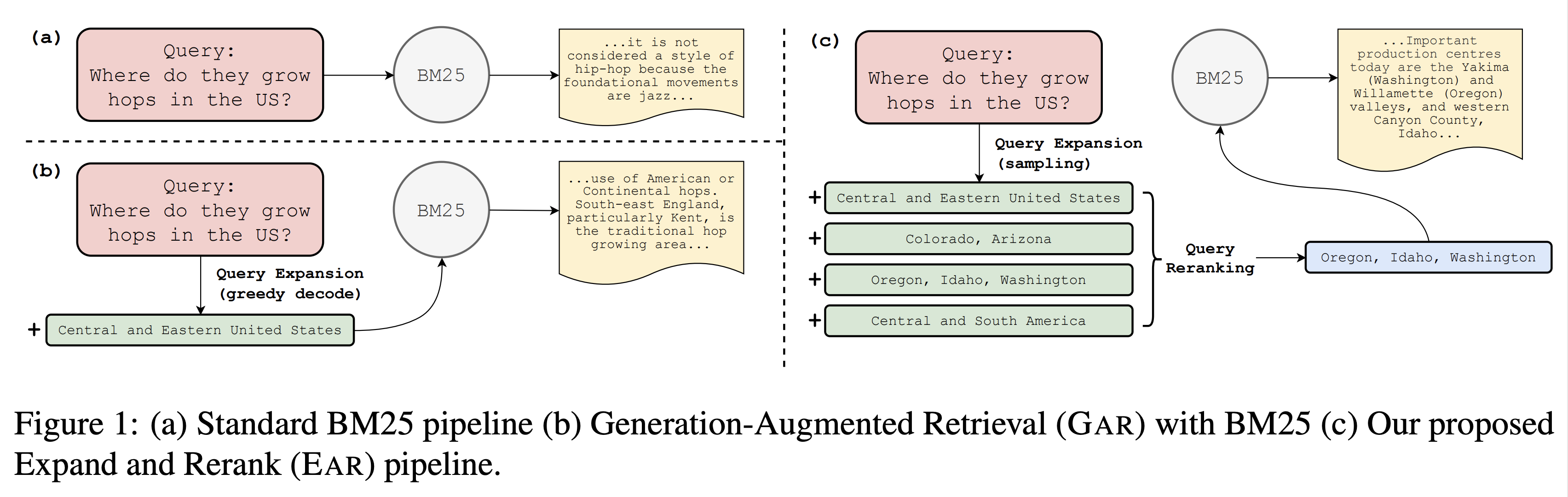
We propose EAR, a query Expansion And Reranking approach for improving passage retrieval, with the application to open-domain question answering. EAR first applies a query expansion model to generate a diverse set of queries, and then uses a query reranker to select the ones that could lead to better retrieval results. Motivated by the observation that the best query expansion often is not picked by greedy decoding, EAR trains its reranker to predict the rank orders of the gold passages when issuing the expanded queries to a given retriever. By connecting better the query expansion model and retriever, EAR significantly enhances a traditional sparse retrieval method, BM25. Empirically, EAR improves top-5/20 accuracy by 3-8 and 5-10 points in in-domain and out-of-domain settings, respectively, when compared to a vanilla query expansion model, GAR, and a dense retrieval model, DPR.
Python 3.7.13
torch==1.10.1
transformers==4.24.0
tokenizers==0.11.1
pyserini
wandb
The data preparation steps can be skip by downloading the dataset here:
https://drive.google.com/file/d/1jurEgOclg8jz9cN3qpNfy1wfGThH9oKB/view?usp=sharing
and you can jump to step 2 directly.
Need to prepare text files which contain queries randomly sampled from T0/GAR:
- T0-3B decoded random sampled outputs for the train set of NQ/TriviaQA.
- GAR decoded random sampled outputs for the dev/test set of NQ/TriviaQA with a. answer b. sentence c. title generators
For T0-3B: Just use this script: generation_t0-3b.py.
For GAR, please refer to their repo: https://github.com/morningmoni/GAR
These generated files should contain one query expansion per line. For each initial query, we random sample 50 queries. For example, NQ-test has 3610 queries, so the GAR answer generator need to generate a file with 18050 lines. The first 50 lines contains 50 query expansions according to the first example in NQ-test; the 50-100 lines contains 50 query expansions according to the second example in NQ-test.
from this step we get several files including (take NQ as an example):
- t0-3b-nq-train.txt
- gar-answer-nq-dev.txt
- gar-sentence-nq-dev.txt
- gar-title-nq-dev.txt
- gar-answer-nq-test.txt
- gar-sentence-nq-test.txt
- gar-title-nq-test.txt
In this step, we create the query csv files for all the queries generated from the last step.
First, we need to download the .csv files for the original queries of NQ/TriviaQA, with this script provided by DPR (nq-train.qa.csv, nq-dev.qa.csv, nq-test.qa.csv, trivia-train.qa.csv, trivia-dev.qa.csv, trivia-test.qa.csv) https://github.com/facebookresearch/DPR/blob/main/dpr/data/download_data.py
The following examples are for generating csv query files for NQ, likewise for TriviaQA:
python gen_csvs.py nq-train.qa.csv t0-3b-nq-train.txt t0-3b-nq-train/nq-train
python gen_csvs.py nq-dev.qa.csv gar-answer-nq-dev.txt gar-answer-nq-dev/nq-dev
...
Create folders t0-3b-nq-train/, gar-answer-nq-dev/, ... before running the script
We obtain a bunch of query csv files from the last step. For example, the folder gar-answer-nq-dev/ should contains:
gar-answer-nq-dev/nq-dev-0.csv
gar-answer-nq-dev/nq-dev-1.csv
gar-answer-nq-dev/nq-dev-2.csv
gar-answer-nq-dev/nq-dev-3.csv
gar-answer-nq-dev/nq-dev-4.csv
...
Here we use pyserini to run BM25 for all the queries.
We use the code from https://github.com/oriram/spider#sparse-retrieval
The JAVA paths should be changed in bm25.sh if you have a different JAVA path.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/bin/
export JVM_PATH=/usr/lib/jvm/java-11-openjdk-amd64/lib/server/libjvm.so
And then run the script:
bash bm25.sh "gar-answer-nq-dev/nq-dev-*.csv" output_bm25_gar-answer-nq-dev
Here we take gar-answer-nq-dev for example, but you should run it with all the folders you get from the last step.
Note that the wiki corpus ./downloads/data/wikipedia_split/psgs_w100.tsv is needed, which can also be downloaded with https://github.com/facebookresearch/DPR/blob/main/dpr/data/download_data.py
At the end of this step, we obtain 7 folders that contains all the BM25 results:
output_bm25_t0-3b-nq-train
output_bm25_gar-answer-nq-dev
output_bm25_gar-sentence-nq-dev
output_bm25_gar-title-nq-dev
output_bm25_gar-answer-nq-test
output_bm25_gar-sentence-nq-test
output_bm25_gar-title-nq-test
python convert_json_dataset.py gar_answer_dev_set.json output_bm25_gar-answer-nq-dev/nq-dev-%d/results.json <thread> <n_examples>
set n_examples = 3610 for NQ-test / 11313 for TriviaQA-test
set thread depends on how many cpu cores you have
After all the above steps, you should finally get the following files:
t0-3b-nq-train_set.json
gar-nq-answer-dev_set.json
gar-nq-sentence-dev_set.json
gar-nq-title-dev_set.json
gar-nq-answer-test_set.json
gar-nq-sentence-test_set.json
gar-nq-title-test_set.json
These are already included in the data download link: https://drive.google.com/file/d/1jurEgOclg8jz9cN3qpNfy1wfGThH9oKB/view?usp=sharing
bash run_train_ri.sh [nq|trivia]
bash run_train_rd.sh [nq|trivia]
Hyperparams can be modified inside run_train_ri.sh and run_train_rd.sh
After training, you should be able to get three checkpoints in your output folder scorer-dev-answer-best.bin/scorer-dev-sentence-best.bin/scorer-dev-title-best.bin, and then we can run evaluation.
bash one_pass_eval_ri.sh [nq|trivia] [MODEL_PATH]
bash one_pass_eval_rd.sh [nq|trivia] [MODEL_PATH]
MODEL_PATH should contains three checkpoints with the names scorer-dev-answer-best.bin/scorer-dev-sentence-best.bin/scorer-dev-title-best.bin
then you should remove --bm25_dir output_bm25_gar-${TARGET}-${DATA}-test \ in eval_transfer.sh before running the evaluation. And then you should use the output query csv file to perform BM25 retrievals as follow:
TARGET=sentence/answer/title
DATA=nq/trivia
bash bm25.sh output/query-gar-${DATA}-${TARGET}-test.RD.csv output
and you will get three results.json under output, you can fuse them by:
DATA=nq/trivia
python round_robin_fuse.py final_result.json output/query-gar-${DATA}-sentence-test/result.json output/query-gar-${DATA}-answer-test/result.json output/query-gar-${DATA}-title-test/result.json
You can calculate the top-k acc with:
python eval_dpr.py --retrieval final_result.json --topk 1 5 10 20 50 100 --override
The retrieval results should be generated automatically.
We also provide the data for cross-dataset transfer:
gar-from-nq-to-entiqa-answer-test_set.json gar-from-nq-to-webq-answer-test_set.json gar-from-trivia-to-trec-answer-test_set.json
gar-from-nq-to-entiqa-sentence-test_set.json gar-from-nq-to-webq-sentence-test_set.json gar-from-trivia-to-trec-sentence-test_set.json
gar-from-nq-to-entiqa-title-test_set.json gar-from-nq-to-webq-title-test_set.json gar-from-trivia-to-trec-title-test_set.json
gar-from-nq-to-trec-answer-test_set.json gar-from-trivia-to-entiqa-answer-test_set.json gar-from-trivia-to-webq-answer-test_set.json
gar-from-nq-to-trec-sentence-test_set.json gar-from-trivia-to-entiqa-sentence-test_set.json gar-from-trivia-to-webq-sentence-test_set.json
gar-from-nq-to-trec-title-test_set.json gar-from-trivia-to-entiqa-title-test_set.json gar-from-trivia-to-webq-title-test_set.json
Change the paths accordingly in the evaluation step should work for these json files.
Please cite our paper if it's helpful to your work!
@misc{chuang2023expand,
title={Expand, Rerank, and Retrieve: Query Reranking for Open-Domain Question Answering},
author={Yung-Sung Chuang and Wei Fang and Shang-Wen Li and Wen-tau Yih and James Glass},
year={2023},
eprint={2305.17080},
archivePrefix={arXiv},
primaryClass={cs.CL}
}