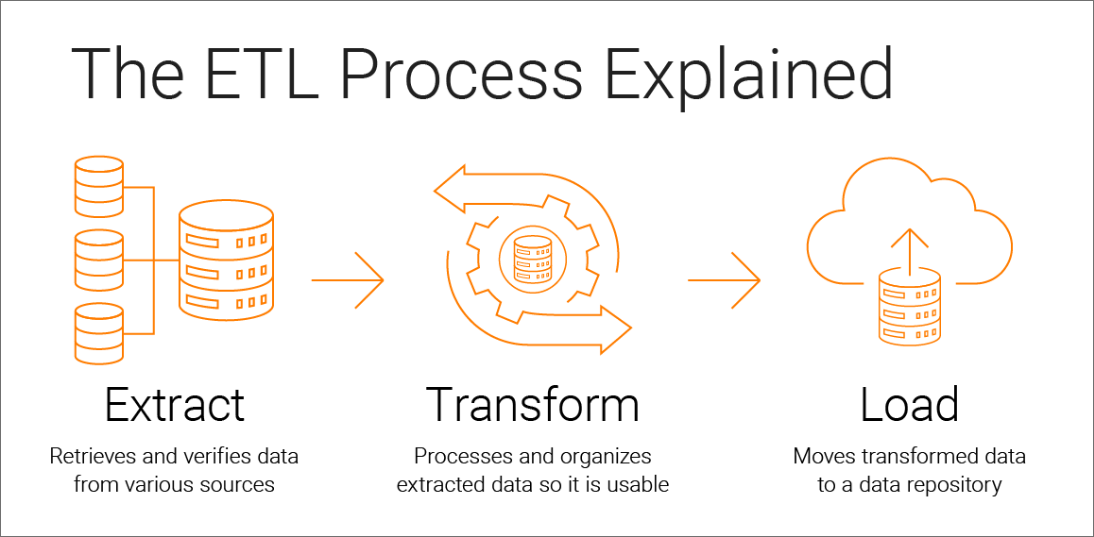
The goal of this project is for you to practice what you have learned so far on this program. For this project, you will start with a data set of your choice. You will need to import it, use your newly-acquired skills to clean and process the data. You should demonstrate your proficiency with the tools we covered (functions, classes, list comprehensions, string operations, pandas, and error handling, etc.) in your functions.
You will be working individually for this project, but we'll be guiding you along the process and helping you as you go. Show us what you've got!
The technical requirements for this project are as follows:
- You must put your code wrapped in functions.
- The following data pipeline stages should be covered: acquisition, wrangling, analysis, and reporting.
- You must extract data from 3 different sources using 2 different tools(Downloading a
.csv,API, web scrapping...) - You must demonstrate all the topics we covered in the chapter (functions, list comprehensions, string operations, etc) in your processing of the data.
- Your code should be saved in a Python executable file (.py), your data should be saved in a folder named data or src.
- You should also include a README.md file that describes the steps you took and your thought process as you built your data pipeline.
-
A) Find a dataset to start you work! A great place to start looking would be Awesome Public Data Sets and Kaggle Data Sets.
-
B) Clean and wrangle your dataset, prepare the data for your needs and intentions.
-
C) Enrich the database with external data, you have to choose at least one of the following:
- Get data from an
API.- Note: The API you use may require authentication via token or oAuth(remember to hide it in a .env file and include it in the
.gitignore).
- Note: The API you use may require authentication via token or oAuth(remember to hide it in a .env file and include it in the
- Do web scraping with python
beautifulsouporseleniummodule.
- Get data from an
-
D) The data you bring in to enrich the dataset must be related to it and complement it! Figure out how it fits together and how you prepare the data of both sources for your report. Some suggestions on how you could achieve this:
- You have a dataset. Now you can use an API using the data of a column and create a new one with valuable info of your response for each row.
- Scrapping a website and creating a new dataset. Then linking both datasets somehow. Maybe in the visualization.
- Merging two datasets is complicated: you would need at least the same column with the same data in both. Don't overthink this stage. You can establish the relationship of both sources of data through visualization.
-
E) Create some reports containing valuable data from the dataset + enrichment. Some of the things you may do are:
-
Simply sumarize the data and do some basic statistics (
mean,max,min,std, etc.). -
Do domain based statistics or data aggregations using
groupby(). -
Go nuts with the investigation.
-
-
F) The finished report must be a very pretty jupyter notebook, with text, clean code, meaningful outputs... Try telling a story with your data, that is, conduct us (the readers) through your findings and lead us into your conclusions.
- Note: The report jupyter must be separate from the code for cleaning, acquiring, processing data, etc. These may be in other jupyters or in
.pymodules. Be not afraid to modulate 🎶
- Note: The report jupyter must be separate from the code for cleaning, acquiring, processing data, etc. These may be in other jupyters or in
You will be working with both jupyter notebooks and python scripts. The goals of this project are:
- To enrich a given dataset, either using API's or web-scrapping
For this first goal, you can either make calls on your cleaned dataset and add new columns to it, or you can do web-scrapping to generate a new dataset. Then, you'll have to plot graphs that show the relation between the data within the dataset (downloaded and enriched with API calls) or between the two datasets (the downloaded and the scrapped).
- To create executable python files.
E.g.: you tested your cleaning functions on your jupyter notebook. Now that they work, you take them to your cleaning.py file. Remember that you'll have to call those functions as well for them to be executed:
def sum(a, b) #defining
return a+b
sum(3, 4) #callingYou should be able to run:
python3 cleaning.pyon your terminal so that it'll prompt you to enter a dataset to download. Then the code within your file will download it, clean it and export it.
After that's done, the rest of your code: enrichment and visualization can be told on jupyter notebooks.
So, basically, your repo structure should look something like:
1-src(folder containing downloading-and-cleaning.py #executable)
2-enriching-and-cleaning.ipynb
3-visualizing.ipynbHowever, even though the executable file will only be the cleaning.py, that doesn't mean that there are no more files.py. All of the functions that you use for enriching the datset (api calls, web-scrapping, cleaning the second dataset, etc) should also be stored in another file.py. Eg.:
4-api.py #not necessarily executable but can be
5-scrapping.py
6-other-functions-you-can-think-of.py-
Choose the data sources ASAP and try to stick to the plan. Don't switch datasets/API's/webs halfway.
-
Examine the data.
-
Break the project down into different steps - A hundred simple tasks are` better than a single complicated one
-
Use the tools in your tool kit - your knowledge of intermediate Python as well as some of the things you've learned in the bootcamp. This is a great way to start tying everything you've learned together!
-
Work through the lessons in class & ask questions when you need to!
-
Think about adding relevant code to your project each day, instead of, you know... procrastinating.
-
Commit early, commit often, don’t be afraid of doing something incorrectly because you can always roll back to a previous version. Name your commits well.
-
Consult documentation and resources provided to better understand the tools you are using and how to accomplish what you want. GIYF.
-
Have fun! Never give up! Be proud of your work!