Projeto: Identificando fraude no Email da Enron. Identificação de suspeitos utilizando Machine Learning
Este projeto utiliza um conjunto de dados que contém informações de e-mails enviados e/ou recebidos e dados financeiros de funcionários da empresa Enron Corporation, que em 2000 era uma das maiores empresas dos Estados Unidos e dois anos mais tarde faliu depois de um dos maiores escândalos de corrupção da história americana, conforme apresentado no vídeo Enron os mais espertos da sala.

O objetivo deste trabalho é a construção de um modelo preditivo, utilizando aprendizagem de máquina, para determinar se um funcionário da Enron é ou não um POI (Persons Of Interest), isto é, um suspeito de participar da fraude.
O modelo proposto deve possuir para cada uma das métricas Precision e Recall um valor mínimo de 0.3.
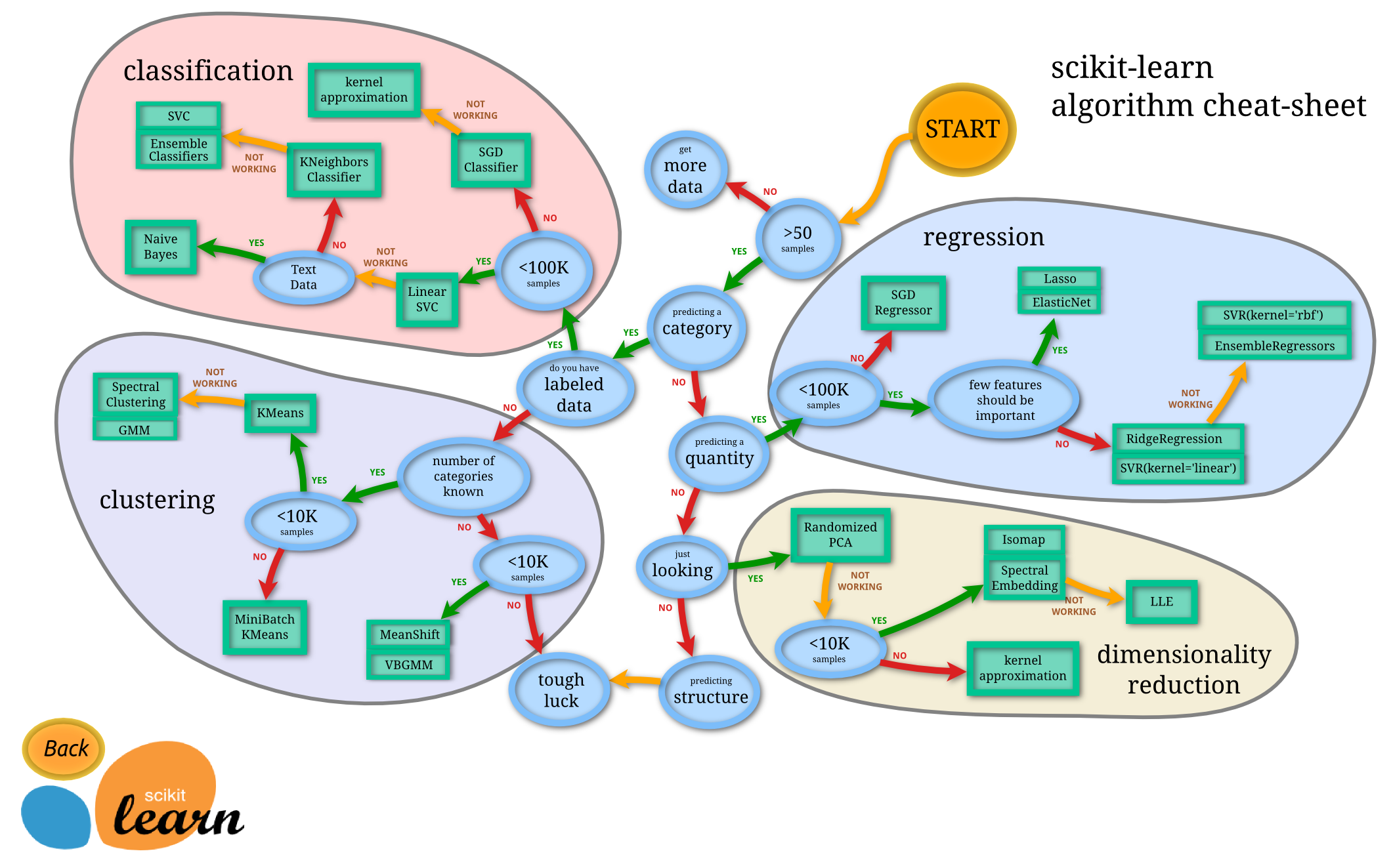
Todo o projeto foi desenvolvido na linguagem Python com auxílio da biblioteca SciKit-learn, utilizando algoritmos de classificação conforme fluxograma abaixo.
Todo o código produzido, bem como demais arquivos, estão no GitHub do autor.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A fraude na Enron resultou em uma investigação federal, na qual muitos dados que são normalmente confidenciais, se tornaram públicos, incluindo dezenas de milhares de e-mails e detalhes financeiros dos executivos, em todos os níveis, da empresa. É esse conjunto de dados que é utilizado neste projeto; ele é intitulado: Enron financial and email, é público e pode ser acessado no site da Carnegie Mellon University.
Carregando a base de dados ...
#!/usr/bin/python
import sys
import pickle
import warnings
warnings.filterwarnings('ignore')
sys.path.append("../tools/")
from feature_format import featureFormat, targetFeatureSplit
from tester import dump_classifier_and_data, main
with open("final_project_dataset.pkl", "r") as data_file:
data_dict = pickle.load(data_file)Os dados são carregados em uma estrutura de dados tipo dict (dicionário), na qual cada par chave/valor corresponde a um funcionário. A chave do dicionário é o nome do funcionário, e o valor é outro dicionário, que contém o nome de todos os atributos e seus valores para aquele funcionário. Os atributos nos dados possuem basicamente três tipos: atributos financeiros, de email e rótulos POI.
Atributos financeiros: ['salary', 'deferral_payments', 'total_payments', 'loan_advances', 'bonus', 'restricted_stock_deferred', 'deferred_income', 'total_stock_value', 'expenses', 'exercised_stock_options', 'other', 'long_term_incentive', 'restricted_stock', 'director_fees'] (todos em dólares americanos (USD))
Atributos de email: ['to_messages', 'email_address', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] (as unidades aqui são geralmente em número de emails; a exceção notável aqui é o atributo ‘email_address’, que é uma string)
Rótulo POI: [‘poi’] (atributo objetivo lógico (booleano), representado como um inteiro)
Para sustentar a seleção dos atributos que serão utilizados foi realizado inicialmente uma Análise Exploratória dos Dados (AED) da base.
Convertendo a base para um DataFrame [Pandas](https://en.wikipedia.org/wiki/Pandas_(software).
import pandas as pd
import numpy as np
data_dict_df = pd.DataFrame(data_dict.values(), index=data_dict.keys())Verificando as dimensões da base de dados:
data_dict_df.shape(146, 21)
A base possui 146 Observações (linhas) e 21 Variáveis (colunas).
Visão geral da base:
data_dict_df.head(3)| bonus | deferral_payments | deferred_income | director_fees | email_address | exercised_stock_options | expenses | from_messages | from_poi_to_this_person | from_this_person_to_poi | ... | long_term_incentive | other | poi | restricted_stock | restricted_stock_deferred | salary | shared_receipt_with_poi | to_messages | total_payments | total_stock_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| METTS MARK | 600000 | NaN | NaN | NaN | mark.metts@enron.com | NaN | 94299 | 29 | 38 | 1 | ... | NaN | 1740 | False | 585062 | NaN | 365788 | 702 | 807 | 1061827 | 585062 |
| BAXTER JOHN C | 1200000 | 1295738 | -1386055 | NaN | NaN | 6680544 | 11200 | NaN | NaN | NaN | ... | 1586055 | 2660303 | False | 3942714 | NaN | 267102 | NaN | NaN | 5634343 | 10623258 |
| ELLIOTT STEVEN | 350000 | NaN | -400729 | NaN | steven.elliott@enron.com | 4890344 | 78552 | NaN | NaN | NaN | ... | NaN | 12961 | False | 1788391 | NaN | 170941 | NaN | NaN | 211725 | 6678735 |
3 rows × 21 columns
É possível observar vários valores faltantes NaN (Not a Number); assim, isto deve ser levado em consideração para não influenciar os cálculos, por exemplo, na estatística descritiva.
Convertendo os NaN para o padrão do pacote Numpy.
data_dict_df = data_dict_df.replace('NaN', np.NaN)Tipos de dados das variáveis:
data_dict_df.dtypesbonus float64
deferral_payments float64
deferred_income float64
director_fees float64
email_address object
exercised_stock_options float64
expenses float64
from_messages float64
from_poi_to_this_person float64
from_this_person_to_poi float64
loan_advances float64
long_term_incentive float64
other float64
poi bool
restricted_stock float64
restricted_stock_deferred float64
salary float64
shared_receipt_with_poi float64
to_messages float64
total_payments float64
total_stock_value float64
dtype: object
A grande maioria das variáveis são do tipo numérica (float64); há ainda uma variável do tipo categórica (bool) e uma do tipo texto (object).
Estatística descritiva da base:
data_dict_df.describe()| bonus | deferral_payments | deferred_income | director_fees | exercised_stock_options | expenses | from_messages | from_poi_to_this_person | from_this_person_to_poi | loan_advances | long_term_incentive | other | restricted_stock | restricted_stock_deferred | salary | shared_receipt_with_poi | to_messages | total_payments | total_stock_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 8.200000e+01 | 3.900000e+01 | 4.900000e+01 | 1.700000e+01 | 1.020000e+02 | 9.500000e+01 | 86.000000 | 86.000000 | 86.000000 | 4.000000e+00 | 6.600000e+01 | 9.300000e+01 | 1.100000e+02 | 1.800000e+01 | 9.500000e+01 | 86.000000 | 86.000000 | 1.250000e+02 | 1.260000e+02 |
| mean | 2.374235e+06 | 1.642674e+06 | -1.140475e+06 | 1.668049e+05 | 5.987054e+06 | 1.087289e+05 | 608.790698 | 64.895349 | 41.232558 | 4.196250e+07 | 1.470361e+06 | 9.190650e+05 | 2.321741e+06 | 1.664106e+05 | 5.621943e+05 | 1176.465116 | 2073.860465 | 5.081526e+06 | 6.773957e+06 |
| std | 1.071333e+07 | 5.161930e+06 | 4.025406e+06 | 3.198914e+05 | 3.106201e+07 | 5.335348e+05 | 1841.033949 | 86.979244 | 100.073111 | 4.708321e+07 | 5.942759e+06 | 4.589253e+06 | 1.251828e+07 | 4.201494e+06 | 2.716369e+06 | 1178.317641 | 2582.700981 | 2.906172e+07 | 3.895777e+07 |
| min | 7.000000e+04 | -1.025000e+05 | -2.799289e+07 | 3.285000e+03 | 3.285000e+03 | 1.480000e+02 | 12.000000 | 0.000000 | 0.000000 | 4.000000e+05 | 6.922300e+04 | 2.000000e+00 | -2.604490e+06 | -7.576788e+06 | 4.770000e+02 | 2.000000 | 57.000000 | 1.480000e+02 | -4.409300e+04 |
| 25% | 4.312500e+05 | 8.157300e+04 | -6.948620e+05 | 9.878400e+04 | 5.278862e+05 | 2.261400e+04 | 22.750000 | 10.000000 | 1.000000 | 1.600000e+06 | 2.812500e+05 | 1.215000e+03 | 2.540180e+05 | -3.896218e+05 | 2.118160e+05 | 249.750000 | 541.250000 | 3.944750e+05 | 4.945102e+05 |
| 50% | 7.693750e+05 | 2.274490e+05 | -1.597920e+05 | 1.085790e+05 | 1.310814e+06 | 4.695000e+04 | 41.000000 | 35.000000 | 8.000000 | 4.176250e+07 | 4.420350e+05 | 5.238200e+04 | 4.517400e+05 | -1.469750e+05 | 2.599960e+05 | 740.500000 | 1211.000000 | 1.101393e+06 | 1.102872e+06 |
| 75% | 1.200000e+06 | 1.002672e+06 | -3.834600e+04 | 1.137840e+05 | 2.547724e+06 | 7.995250e+04 | 145.500000 | 72.250000 | 24.750000 | 8.212500e+07 | 9.386720e+05 | 3.620960e+05 | 1.002370e+06 | -7.500975e+04 | 3.121170e+05 | 1888.250000 | 2634.750000 | 2.093263e+06 | 2.949847e+06 |
| max | 9.734362e+07 | 3.208340e+07 | -8.330000e+02 | 1.398517e+06 | 3.117640e+08 | 5.235198e+06 | 14368.000000 | 528.000000 | 609.000000 | 8.392500e+07 | 4.852193e+07 | 4.266759e+07 | 1.303223e+08 | 1.545629e+07 | 2.670423e+07 | 5521.000000 | 15149.000000 | 3.098866e+08 | 4.345095e+08 |
Quantas funcionários há na base?
len(data_dict_df)146
Existem 146 funcionários na base de dados sendo que cada um deles possui até 21 atributos registrados.
Como existem muitos valores faltantes (NaN) nem todos possuem todos os atributos.
Quantos atributos existem para cada variável?
data_dict_df.count()bonus 82
deferral_payments 39
deferred_income 49
director_fees 17
email_address 111
exercised_stock_options 102
expenses 95
from_messages 86
from_poi_to_this_person 86
from_this_person_to_poi 86
loan_advances 4
long_term_incentive 66
other 93
poi 146
restricted_stock 110
restricted_stock_deferred 18
salary 95
shared_receipt_with_poi 86
to_messages 86
total_payments 125
total_stock_value 126
dtype: int64
Somente o atributo poi está presente para todos os funcionários da base; algumas outras observações, por exemplo: somente 4 funcionários possuem dados da variável loan_advances e 95 possuem informações da variável salary.
Quantas variáveis faltantes cada funcionário possui?
num_var_func = data_dict_df.isnull().sum(axis=1)
num_var_func.sort_values(ascending=False).head(15)LOCKHART EUGENE E 20
WROBEL BRUCE 18
THE TRAVEL AGENCY IN THE PARK 18
GRAMM WENDY L 18
WHALEY DAVID A 18
GILLIS JOHN 17
WODRASKA JOHN 17
CLINE KENNETH W 17
SAVAGE FRANK 17
SCRIMSHAW MATTHEW 17
WAKEHAM JOHN 17
CHRISTODOULOU DIOMEDES 16
BLAKE JR. NORMAN P 16
LOWRY CHARLES P 16
GATHMANN WILLIAM D 16
dtype: int64
O funcionário LOCKHART EUGENE E tem 20 variáveis faltantes, como existem ao todos 21 variáveis, ele só possui uma variável lançada. Já o THE TRAVEL AGENCY IN THE PARK não parece ser realmente uma pessoa, além de possuir 18 variáveis faltantes, assim, também será excluido.
Que variável LOCKHART EUGENE E possui?
data_dict_df.loc['LOCKHART EUGENE E']bonus NaN
deferral_payments NaN
deferred_income NaN
director_fees NaN
email_address NaN
exercised_stock_options NaN
expenses NaN
from_messages NaN
from_poi_to_this_person NaN
from_this_person_to_poi NaN
loan_advances NaN
long_term_incentive NaN
other NaN
poi False
restricted_stock NaN
restricted_stock_deferred NaN
salary NaN
shared_receipt_with_poi NaN
to_messages NaN
total_payments NaN
total_stock_value NaN
Name: LOCKHART EUGENE E, dtype: object
Somente a variável poi, portanto, LOCKHART EUGENE E, por isso será retirado da base, uma vez que não possuímos dados sobre este funcionário.
E para THE TRAVEL AGENCY IN THE PARK ?
data_dict_df.loc['THE TRAVEL AGENCY IN THE PARK']bonus NaN
deferral_payments NaN
deferred_income NaN
director_fees NaN
email_address NaN
exercised_stock_options NaN
expenses NaN
from_messages NaN
from_poi_to_this_person NaN
from_this_person_to_poi NaN
loan_advances NaN
long_term_incentive NaN
other 362096
poi False
restricted_stock NaN
restricted_stock_deferred NaN
salary NaN
shared_receipt_with_poi NaN
to_messages NaN
total_payments 362096
total_stock_value NaN
Name: THE TRAVEL AGENCY IN THE PARK, dtype: object
Quantos funcionários são classificados como POI?
data_dict_df.poi.value_counts()False 128
True 18
Name: poi, dtype: int64
18 funcionários.
Quem são eles?
data_dict_df[data_dict_df.poi==True]| bonus | deferral_payments | deferred_income | director_fees | email_address | exercised_stock_options | expenses | from_messages | from_poi_to_this_person | from_this_person_to_poi | ... | long_term_incentive | other | poi | restricted_stock | restricted_stock_deferred | salary | shared_receipt_with_poi | to_messages | total_payments | total_stock_value | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HANNON KEVIN P | 1500000.0 | NaN | -3117011.0 | NaN | kevin.hannon@enron.com | 5538001.0 | 34039.0 | 32.0 | 32.0 | 21.0 | ... | 1617011.0 | 11350.0 | True | 853064.0 | NaN | 243293.0 | 1035.0 | 1045.0 | 288682.0 | 6391065.0 |
| COLWELL WESLEY | 1200000.0 | 27610.0 | -144062.0 | NaN | wes.colwell@enron.com | NaN | 16514.0 | 40.0 | 240.0 | 11.0 | ... | NaN | 101740.0 | True | 698242.0 | NaN | 288542.0 | 1132.0 | 1758.0 | 1490344.0 | 698242.0 |
| RIEKER PAULA H | 700000.0 | 214678.0 | -100000.0 | NaN | paula.rieker@enron.com | 1635238.0 | 33271.0 | 82.0 | 35.0 | 48.0 | ... | NaN | 1950.0 | True | 283649.0 | NaN | 249201.0 | 1258.0 | 1328.0 | 1099100.0 | 1918887.0 |
| KOPPER MICHAEL J | 800000.0 | NaN | NaN | NaN | michael.kopper@enron.com | NaN | 118134.0 | NaN | NaN | NaN | ... | 602671.0 | 907502.0 | True | 985032.0 | NaN | 224305.0 | NaN | NaN | 2652612.0 | 985032.0 |
| SHELBY REX | 200000.0 | NaN | -4167.0 | NaN | rex.shelby@enron.com | 1624396.0 | 22884.0 | 39.0 | 13.0 | 14.0 | ... | NaN | 1573324.0 | True | 869220.0 | NaN | 211844.0 | 91.0 | 225.0 | 2003885.0 | 2493616.0 |
| DELAINEY DAVID W | 3000000.0 | NaN | NaN | NaN | david.delainey@enron.com | 2291113.0 | 86174.0 | 3069.0 | 66.0 | 609.0 | ... | 1294981.0 | 1661.0 | True | 1323148.0 | NaN | 365163.0 | 2097.0 | 3093.0 | 4747979.0 | 3614261.0 |
| LAY KENNETH L | 7000000.0 | 202911.0 | -300000.0 | NaN | kenneth.lay@enron.com | 34348384.0 | 99832.0 | 36.0 | 123.0 | 16.0 | ... | 3600000.0 | 10359729.0 | True | 14761694.0 | NaN | 1072321.0 | 2411.0 | 4273.0 | 103559793.0 | 49110078.0 |
| BOWEN JR RAYMOND M | 1350000.0 | NaN | -833.0 | NaN | raymond.bowen@enron.com | NaN | 65907.0 | 27.0 | 140.0 | 15.0 | ... | 974293.0 | 1621.0 | True | 252055.0 | NaN | 278601.0 | 1593.0 | 1858.0 | 2669589.0 | 252055.0 |
| BELDEN TIMOTHY N | 5249999.0 | 2144013.0 | -2334434.0 | NaN | tim.belden@enron.com | 953136.0 | 17355.0 | 484.0 | 228.0 | 108.0 | ... | NaN | 210698.0 | True | 157569.0 | NaN | 213999.0 | 5521.0 | 7991.0 | 5501630.0 | 1110705.0 |
| FASTOW ANDREW S | 1300000.0 | NaN | -1386055.0 | NaN | andrew.fastow@enron.com | NaN | 55921.0 | NaN | NaN | NaN | ... | 1736055.0 | 277464.0 | True | 1794412.0 | NaN | 440698.0 | NaN | NaN | 2424083.0 | 1794412.0 |
| CALGER CHRISTOPHER F | 1250000.0 | NaN | -262500.0 | NaN | christopher.calger@enron.com | NaN | 35818.0 | 144.0 | 199.0 | 25.0 | ... | 375304.0 | 486.0 | True | 126027.0 | NaN | 240189.0 | 2188.0 | 2598.0 | 1639297.0 | 126027.0 |
| RICE KENNETH D | 1750000.0 | NaN | -3504386.0 | NaN | ken.rice@enron.com | 19794175.0 | 46950.0 | 18.0 | 42.0 | 4.0 | ... | 1617011.0 | 174839.0 | True | 2748364.0 | NaN | 420636.0 | 864.0 | 905.0 | 505050.0 | 22542539.0 |
| SKILLING JEFFREY K | 5600000.0 | NaN | NaN | NaN | jeff.skilling@enron.com | 19250000.0 | 29336.0 | 108.0 | 88.0 | 30.0 | ... | 1920000.0 | 22122.0 | True | 6843672.0 | NaN | 1111258.0 | 2042.0 | 3627.0 | 8682716.0 | 26093672.0 |
| YEAGER F SCOTT | NaN | NaN | NaN | NaN | scott.yeager@enron.com | 8308552.0 | 53947.0 | NaN | NaN | NaN | ... | NaN | 147950.0 | True | 3576206.0 | NaN | 158403.0 | NaN | NaN | 360300.0 | 11884758.0 |
| HIRKO JOSEPH | NaN | 10259.0 | NaN | NaN | joe.hirko@enron.com | 30766064.0 | 77978.0 | NaN | NaN | NaN | ... | NaN | 2856.0 | True | NaN | NaN | NaN | NaN | NaN | 91093.0 | 30766064.0 |
| KOENIG MARK E | 700000.0 | NaN | NaN | NaN | mark.koenig@enron.com | 671737.0 | 127017.0 | 61.0 | 53.0 | 15.0 | ... | 300000.0 | 150458.0 | True | 1248318.0 | NaN | 309946.0 | 2271.0 | 2374.0 | 1587421.0 | 1920055.0 |
| CAUSEY RICHARD A | 1000000.0 | NaN | -235000.0 | NaN | richard.causey@enron.com | NaN | 30674.0 | 49.0 | 58.0 | 12.0 | ... | 350000.0 | 307895.0 | True | 2502063.0 | NaN | 415189.0 | 1585.0 | 1892.0 | 1868758.0 | 2502063.0 |
| GLISAN JR BEN F | 600000.0 | NaN | NaN | NaN | ben.glisan@enron.com | 384728.0 | 125978.0 | 16.0 | 52.0 | 6.0 | ... | 71023.0 | 200308.0 | True | 393818.0 | NaN | 274975.0 | 874.0 | 873.0 | 1272284.0 | 778546.0 |
18 rows × 21 columns
Dos funcionários POIs, quem mais recebeu dinheiro (total_payments)?
data_dict_df.sort_values(by='total_payments', ascending=False)[data_dict_df.poi==True]['total_payments']LAY KENNETH L 103559793.0
SKILLING JEFFREY K 8682716.0
BELDEN TIMOTHY N 5501630.0
DELAINEY DAVID W 4747979.0
BOWEN JR RAYMOND M 2669589.0
KOPPER MICHAEL J 2652612.0
FASTOW ANDREW S 2424083.0
SHELBY REX 2003885.0
CAUSEY RICHARD A 1868758.0
CALGER CHRISTOPHER F 1639297.0
KOENIG MARK E 1587421.0
COLWELL WESLEY 1490344.0
GLISAN JR BEN F 1272284.0
RIEKER PAULA H 1099100.0
RICE KENNETH D 505050.0
YEAGER F SCOTT 360300.0
HANNON KEVIN P 288682.0
HIRKO JOSEPH 91093.0
Name: total_payments, dtype: float64
Os dois que mais receberam, LAY KENNETH L, era o Chairman Board e SKILLING JEFFREY K o CEO.
FASTOW ANDREW S, que era CFO, foi o 7º que mais recebeu.
Dos funcionários que não são POI, quem são o 5 que mais receberam dinheiro?
data_dict_df.sort_values(by='total_payments', ascending=False)[data_dict_df.poi==False]['total_payments'].head()TOTAL 309886585.0
FREVERT MARK A 17252530.0
BHATNAGAR SANJAY 15456290.0
LAVORATO JOHN J 10425757.0
MARTIN AMANDA K 8407016.0
Name: total_payments, dtype: float64
Hum, problema!
TOTAL não parece ser um funcionário; é um totalizador, temos que exclui-lo também da base e refazer a análise descritiva.
Excluindo 'TOTAL'
data_dict.pop('TOTAL', None)
data_dict_df = data_dict_df.drop(['TOTAL'])Como o objetivo é identificar POIs, vamos dividir a base em dois grupos POIs (POI) e não POIs (NPOI) buscando comparar os valores médios das variáveis nestes grupos de forma a identificar possíveis atributos para a máquina de aprendizagem.
A razão dos valores POI por NPOI (POI_NPOI) também será calculada.
Calculando ...
data_dict_df_POI = data_dict_df[data_dict_df.poi==True]
data_dict_df_NPOI = data_dict_df[data_dict_df.poi==False]
mean_POI = pd.DataFrame(data_dict_df_POI.mean(), columns = ['POI'])
mean_NPOI = pd.DataFrame(data_dict_df_NPOI.mean(), columns = ['NPOI'])
df_mean = pd.concat([mean_POI, mean_NPOI], axis=1)
df_mean['POI_NPOI'] = df_mean['POI']/df_mean['NPOI']
df_mean.sort_values(by = "POI_NPOI", ascending=False)| POI | NPOI | POI_NPOI | |
|---|---|---|---|
| poi | 1.000000e+00 | 0.000000e+00 | inf |
| loan_advances | 8.152500e+07 | 1.200000e+06 | 67.937500 |
| exercised_stock_options | 1.046379e+07 | 1.947752e+06 | 5.372240 |
| total_payments | 7.913590e+06 | 1.725091e+06 | 4.587347 |
| total_stock_value | 9.165671e+06 | 2.374085e+06 | 3.860718 |
| restricted_stock | 2.318621e+06 | 9.310073e+05 | 2.490443 |
| deferred_income | -1.035313e+06 | -4.459985e+05 | 2.321339 |
| bonus | 2.075000e+06 | 9.868249e+05 | 2.102703 |
| other | 8.029974e+05 | 3.831284e+05 | 2.095896 |
| long_term_incentive | 1.204862e+06 | 6.427090e+05 | 1.874662 |
| from_this_person_to_poi | 6.671429e+01 | 3.627778e+01 | 1.838985 |
| shared_receipt_with_poi | 1.783000e+03 | 1.058528e+03 | 1.684415 |
| from_poi_to_this_person | 9.778571e+01 | 5.850000e+01 | 1.671551 |
| salary | 3.834449e+05 | 2.621515e+05 | 1.462684 |
| to_messages | 2.417143e+03 | 2.007111e+03 | 1.204290 |
| expenses | 5.987383e+04 | 5.284632e+04 | 1.132980 |
| deferral_payments | 5.198942e+05 | 8.903462e+05 | 0.583924 |
| from_messages | 3.003571e+02 | 6.687639e+02 | 0.449123 |
| director_fees | NaN | 8.982288e+04 | NaN |
| restricted_stock_deferred | NaN | 6.218928e+05 | NaN |
Quais são as razões POI/NPOI > 3?
df_mean[df_mean.POI_NPOI > 3].sort_values(by = "POI_NPOI", ascending=False)| POI | NPOI | POI_NPOI | |
|---|---|---|---|
| poi | 1.000000e+00 | 0.000000e+00 | inf |
| loan_advances | 8.152500e+07 | 1.200000e+06 | 67.937500 |
| exercised_stock_options | 1.046379e+07 | 1.947752e+06 | 5.372240 |
| total_payments | 7.913590e+06 | 1.725091e+06 | 4.587347 |
| total_stock_value | 9.165671e+06 | 2.374085e+06 | 3.860718 |
Quais são as razões POI/NPOI < 1.0?
df_mean[df_mean.POI_NPOI < 1].sort_values(by = "POI_NPOI", ascending=True)| POI | NPOI | POI_NPOI | |
|---|---|---|---|
| from_messages | 300.357143 | 668.763889 | 0.449123 |
| deferral_payments | 519894.200000 | 890346.212121 | 0.583924 |
Além das relações acima, também chamou atenção as variáveis director_fees e restricted_stock_deferred, pois nenhum POI as possui; contudo, conforme visto anteriormente, em toda a base somente 17 e 18 funcionários, respectivamente, apresentaram essas variáveis, assim, não parece ser um desvio.
A variável que mais chama atenção é a loan_advances, contudo, conforme visto acima, há apenas 4 registros desta variável; exercised_stock_options e total_payments também se destacam.
Uma outra ideia de encontrar candidatos a atributos é identificar quais variáveis possuem mais outliers, uma vez que em fraudes o que mais interessa são as exceções.
Quais as variáveis que mais possuem outliers?
Obs.: calculados conforme Fávero et al. (2009).
Q1 = data_dict_df.quantile(0.25)
Q3 = data_dict_df.quantile(0.75)
IQR = Q3 - Q1
n_outliers = ((data_dict_df < (Q1 - 1.5 * IQR)) | (data_dict_df > (Q3 + 1.5 * IQR))).sum()
n_outliers.sort_values(ascending=False)email_address 111
total_stock_value 21
poi 18
from_messages 17
restricted_stock 14
from_this_person_to_poi 13
exercised_stock_options 11
from_poi_to_this_person 11
total_payments 10
bonus 10
other 10
salary 9
long_term_incentive 7
to_messages 7
deferral_payments 6
deferred_income 5
director_fees 4
expenses 3
restricted_stock_deferred 2
shared_receipt_with_poi 2
loan_advances 0
dtype: int64
Desconsiderando as variáveis que não são numéricas (float64), as que mais tiveram outliers foram: total_stock_value, from_messages e restricted_stock. Assim, considerando os dois critérios adotados: relação das médias dos POI/NPOI e número de outliers, além da variável poi serão utilizadas como atributos:
Gerando a lista de atributos 1:
features_list_1 = ['poi','loan_advances', 'exercised_stock_options', 'total_payments',
'total_stock_value', 'from_messages', 'restricted_stock' ]Podemos pensar também em combinar os atributos (features) originais de forma a buscar melhorar o desempenho do classificador; no caso específico deste projeto, pode-se pensar:
Quem enviou mais e-mails para um POI?
Quem recebeu mais e-mals de um POI?
Seria uma hipótese de que os POIs se comunicam mais entre si, com isto, propomos duas novas features:
- from_this_person_to_poi: razão da quantidade de e-mails enviados para um POI em relação a quantidade total de e-mail enviados;
- from_poi_to_this_person: razão da quantidade de e-mails recebidos de um POI em relação a quantidade total de e-mails recebidos.
Gerando a lista de atributos 2:
features_list_2 = ['poi','loan_advances', 'exercised_stock_options', 'total_payments',
'total_stock_value', 'from_messages', 'restricted_stock','from_this_person_to_poi' ,
'from_poi_to_this_person']No capítulo 4 - Testando os Classificadores - utilizaremos a lista de atributos 2 de forma a verificar o impacto dos novos atributos no desempenho do classificador.
Vamos remover os outros 2 "funcionários" já identificados, devidos os problemas relatados no item anterior: LOCKHART EUGENE E, e THE TRAVEL AGENCY IN THE PARK.
data_dict.pop('LOCKHART EUGENE E', None)
data_dict_df = data_dict_df.drop(['LOCKHART EUGENE E'])
data_dict.pop('THE TRAVEL AGENCY IN THE PARK', None)
data_dict_df = data_dict_df.drop(['THE TRAVEL AGENCY IN THE PARK'])Com as remoções, quantos funcionários restaram na base?
len(data_dict_df)143
len(data_dict)143
Ok, restaram 143, uma vez que inicialmente haviam 146 e foram excluídos 3. Vamos carregar os dados formatados para utilização na scikit-learn.
Utilizando a lista de atributos 1.
features_list = features_list_1
data = featureFormat(data_dict, features_list)
data.shape(143, 7)
Vamos verificar as variáveis da features_list em um gráfico tipo boxplot para visualizar os outliers.
%pylab inline
import matplotlib.pyplot as plt
import seaborn as snsPopulating the interactive namespace from numpy and matplotlib
data_df = pd.DataFrame(data = data, columns=features_list)
data_df_sem_poi = data_df.drop('poi', axis=1)
sns.set()
fig, ax = plt.subplots(figsize=(15,10))
ax.set_xlabel('Features', fontsize = 20)
plt.tick_params(labelsize=15)
plt.xticks(rotation=75)
sns.boxplot(data=data_df_sem_poi)<matplotlib.axes._subplots.AxesSubplot at 0x7fcd1d912fd0>

Conforme figura acima, há vários outliers em quase todas as variáveis.
Quantos outiliers há nas variáveis da feature_list?
Q1 = data_df_sem_poi.quantile(0.25)
Q3 = data_df_sem_poi.quantile(0.75)
IQR = Q3 - Q1
n_outliers = ((data_df_sem_poi < (Q1 - 1.5 * IQR)) | (data_df_sem_poi > (Q3 + 1.5 * IQR))).sum()
n_outliers.sort_values(ascending=False)from_messages 24
total_stock_value 21
exercised_stock_options 18
restricted_stock 16
total_payments 9
loan_advances 3
dtype: int64
Estranho, na contagem de outliers, a variável from_messages foi a que obteve o maior número, contudo, o boxplot não apresenta nenhum, o que pode ter acontecido?
Vamos plotar o boxplot somente desta variável.
sns.boxplot(data=data_df_sem_poi.from_messages)<matplotlib.axes._subplots.AxesSubplot at 0x7fcd1d8fcc90>

Ok, foi só um detalhe das escalas das variáveis; no caso a ordem de grandeza da variável from_messages é muito menor que das outras variáveis. Provavelmente teremos que realizar uma normalização destes dados.
Qual o valor e quem são esses outliers?
data_dict_df.loc[data_dict_df['loan_advances'].idxmax()]bonus 7e+06
deferral_payments 202911
deferred_income -300000
director_fees NaN
email_address kenneth.lay@enron.com
exercised_stock_options 3.43484e+07
expenses 99832
from_messages 36
from_poi_to_this_person 123
from_this_person_to_poi 16
loan_advances 8.1525e+07
long_term_incentive 3.6e+06
other 1.03597e+07
poi True
restricted_stock 1.47617e+07
restricted_stock_deferred NaN
salary 1.07232e+06
shared_receipt_with_poi 2411
to_messages 4273
total_payments 1.0356e+08
total_stock_value 4.91101e+07
Name: LAY KENNETH L, dtype: object
data_dict_df.loc[data_dict_df['exercised_stock_options'].idxmax()]bonus 7e+06
deferral_payments 202911
deferred_income -300000
director_fees NaN
email_address kenneth.lay@enron.com
exercised_stock_options 3.43484e+07
expenses 99832
from_messages 36
from_poi_to_this_person 123
from_this_person_to_poi 16
loan_advances 8.1525e+07
long_term_incentive 3.6e+06
other 1.03597e+07
poi True
restricted_stock 1.47617e+07
restricted_stock_deferred NaN
salary 1.07232e+06
shared_receipt_with_poi 2411
to_messages 4273
total_payments 1.0356e+08
total_stock_value 4.91101e+07
Name: LAY KENNETH L, dtype: object
data_dict_df.loc[data_dict_df['total_payments'].idxmax()]bonus 7e+06
deferral_payments 202911
deferred_income -300000
director_fees NaN
email_address kenneth.lay@enron.com
exercised_stock_options 3.43484e+07
expenses 99832
from_messages 36
from_poi_to_this_person 123
from_this_person_to_poi 16
loan_advances 8.1525e+07
long_term_incentive 3.6e+06
other 1.03597e+07
poi True
restricted_stock 1.47617e+07
restricted_stock_deferred NaN
salary 1.07232e+06
shared_receipt_with_poi 2411
to_messages 4273
total_payments 1.0356e+08
total_stock_value 4.91101e+07
Name: LAY KENNETH L, dtype: object
data_dict_df.loc[data_dict_df['total_stock_value'].idxmax()]bonus 7e+06
deferral_payments 202911
deferred_income -300000
director_fees NaN
email_address kenneth.lay@enron.com
exercised_stock_options 3.43484e+07
expenses 99832
from_messages 36
from_poi_to_this_person 123
from_this_person_to_poi 16
loan_advances 8.1525e+07
long_term_incentive 3.6e+06
other 1.03597e+07
poi True
restricted_stock 1.47617e+07
restricted_stock_deferred NaN
salary 1.07232e+06
shared_receipt_with_poi 2411
to_messages 4273
total_payments 1.0356e+08
total_stock_value 4.91101e+07
Name: LAY KENNETH L, dtype: object
data_dict_df.loc[data_dict_df['from_messages'].idxmax()]bonus 400000
deferral_payments NaN
deferred_income NaN
director_fees NaN
email_address vince.kaminski@enron.com
exercised_stock_options 850010
expenses 83585
from_messages 14368
from_poi_to_this_person 41
from_this_person_to_poi 171
loan_advances NaN
long_term_incentive 323466
other 4669
poi False
restricted_stock 126027
restricted_stock_deferred NaN
salary 275101
shared_receipt_with_poi 583
to_messages 4607
total_payments 1.08682e+06
total_stock_value 976037
Name: KAMINSKI WINCENTY J, dtype: object
data_dict_df.loc[data_dict_df['restricted_stock'].idxmax()]bonus 7e+06
deferral_payments 202911
deferred_income -300000
director_fees NaN
email_address kenneth.lay@enron.com
exercised_stock_options 3.43484e+07
expenses 99832
from_messages 36
from_poi_to_this_person 123
from_this_person_to_poi 16
loan_advances 8.1525e+07
long_term_incentive 3.6e+06
other 1.03597e+07
poi True
restricted_stock 1.47617e+07
restricted_stock_deferred NaN
salary 1.07232e+06
shared_receipt_with_poi 2411
to_messages 4273
total_payments 1.0356e+08
total_stock_value 4.91101e+07
Name: LAY KENNETH L, dtype: object
Os maiores outliers de cada variável pertencem a LAY KENNETH L, com exceção da variável from_messages na qual KAMINSKI WINCENTY J obteve o maior outlier; considerando que LAY KENNETH L era o Chairman Board da Enron, estes outliers parecem ser um freak event, decorrente de fraude, assim, não serão desconsiderados.
Vamos retirá-los somente para verificar um novo gráfico boxplot.
Qual o index da linha do dataframe com os outliers?
data_df_sem_poi.loc[data_df_sem_poi['total_payments'].idxmax()]loan_advances 81525000.0
exercised_stock_options 34348384.0
total_payments 103559793.0
total_stock_value 49110078.0
from_messages 36.0
restricted_stock 14761694.0
Name: 65, dtype: float64
Excluindo o index 65 e verificando o novo boxplot.
data_df_sem_poi = data_df_sem_poi.drop([65])
fig, ax = plt.subplots(figsize=(15,10))
ax.set_xlabel('Features', fontsize = 20)
plt.tick_params(labelsize=15)
sns.boxplot(data=data_df_sem_poi)
plt.tick_params(labelsize=15)
plt.xticks(rotation=75)
sns.boxplot(data=data_df_sem_poi)<matplotlib.axes._subplots.AxesSubplot at 0x7fcd1b312d50>

Observando os valores do eixo y, é possível notar a diminuição em uma ordem de grandeza em relação ao boxplot anterior, comprovando a remoção do outlier.
Vamos carregar o dicionário com os dados já tratados e formatá-los conforme a biblioteca scikit-learn necessita; para isso, serão utilizados as funções featureFormat e targetFeatureSplit do programa feature_format.py, que pode ser acessado no GitHub.
Vamos testar inicialmente com a lista de atributos 1.
features_list = features_list_1
my_dataset = data_dict
data = featureFormat(my_dataset, features_list, sort_keys = True)
labels, features = targetFeatureSplit(data)Para divisão dos conjuntos de treinamento e de teste será utilizado a biblioteca de validação cruzada do sciki-learn.
Usaremos 70% dos dados para treinamento das máquinas de aprendizagem e o restante para os testes.
Por que nós dividimos o conjunto de dados em conjuntos de treinamento e teste?
A justificativa para divisão do conjunto de dados em subconjuntos de treinamento e testes é que com isto, a máquina:
- Nos fornece uma estimativa de desempenho em um conjunto de dados independente, uma vez que o conjunto de teste só é utilizado para validar o modelo;
- Nos fornece uma verificação do sobreajuste (overfitting).
A ideia geral é da divisão é buscar o conjunto de treinamento que apresente o melhor resultado de aprendizagem e o conjunto de teste que resulte na melhor validação do aprendizado da máquina. Neste sentido, conforme Stephens e Diesing (2014), "[...] It is an important step to tune the parameters of the models to the training data. The aim is to find a balance between building a model that can classify the training data effectively without overfitting to the random fluctuations in the training data. Some models are more sensitive than others to the parameters chosen."
Na validação, o conjunto de teste é utilizado para verificar as características do modelo com dados que não foram utilizados na fase de treinamento.
Quando as variáveis possuem ordens de grandeza muito diferentes, que é o que foi constatado na fase de AED anterior, faz-se necessário deixá-las em uma mesma ordem. A biblioteca sciki-learn possui um pacote de pré-processamento de dados que facilitam tarefas como essa.
from sklearn.cross_validation import train_test_split
from sklearn import preprocessingNormalizando as features:
scaler = preprocessing.MinMaxScaler()
features = scaler.fit_transform(features)Criando os conjuntos de treinamento e testes:
features_train, features_test, labels_train, labels_test = \
train_test_split(features, labels, test_size=0.3, random_state=42)Agora vamos testar vários algoritmos de classificação, todos eles utilizando a biblioteca de aprendizagem de máquina scikit-learn.
O primeiro será o Naive Bayes, do qual a documentação pode ser acessada aqui.
Vamos utilizar duas funções do programa tester.py, dump_classifier_and_data e main que irão realizar todo o trabalho de predição dos valores e calcular as métricas do algoritmo.
O programa tester.py está disponível no GitHub.
# Importando a biblioteca
from sklearn.naive_bayes import GaussianNB
# Criando o classifcador
clf = GaussianNB()
dump_classifier_and_data(clf, my_dataset, features_list)
main()GaussianNB(priors=None)
Accuracy: 0.78393 Precision: 0.20937 Recall: 0.22350 F1: 0.21620 F2: 0.22052
Total predictions: 15000 True positives: 447 False positives: 1688 False negatives: 1553 True negatives: 11312
Agora testaremos a SVM, a documentação pode ser acessada aqui.
from sklearn.svm import SVC
clf=SVC()
dump_classifier_and_data(clf, my_dataset, features_list)
main()Got a divide by zero when trying out: SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Precision or recall may be undefined due to a lack of true positive predicitons.
Agora testaremos a Árvore de Decisão, a documentação pode ser acessada aqui.
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='entropy',min_samples_split=50)
dump_classifier_and_data(clf, my_dataset, features_list)
main()DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=50, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
Accuracy: 0.86553 Precision: 0.47658 Recall: 0.08650 F1: 0.14642 F2: 0.10343
Total predictions: 15000 True positives: 173 False positives: 190 False negatives: 1827 True negatives: 12810
Agora testaremos o Adaboost aplicado a árvores de decisão, também conhecido como BDT, cuja documentação pode ser acessada aqui.
from sklearn.ensemble import AdaBoostClassifier
clf = clf.fit(features_train, labels_train)
dump_classifier_and_data(clf, my_dataset, features_list)
main()DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=50, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
Accuracy: 0.86593 Precision: 0.48509 Recall: 0.08950 F1: 0.15112 F2: 0.10694
Total predictions: 15000 True positives: 179 False positives: 190 False negatives: 1821 True negatives: 12810
Todos os outros algoritmos utilizados até aqui se enquadram em uma categoria denominada Aprendizagem Supervisionada, agora utilizaremos o algoritmo K-means, que é do tipo Aprendizagem não-supervisionado. A documentação do K-means pode ser acessada aqui.
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=2, random_state=0).fit(features_train)
dump_classifier_and_data(clf, my_dataset, features_list)
main()KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=2, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=0, tol=0.0001, verbose=0)
Accuracy: 0.83920 Precision: 0.23791 Recall: 0.09350 F1: 0.13424 F2: 0.10642
Total predictions: 15000 True positives: 187 False positives: 599 False negatives: 1813 True negatives: 12401
Analisando as saídas acima, temos que o melhor resultado, com relação a métrica accuracy foi obtida pelos algoritmos Boosted Decision Trees (BDT) e Decision Trees (DT); vamos calibrar (tuning) o DT.
-
Resumo dos resultados
NB Accuracy: 0.78393 Precision: 0.20937 Recall: 0.22350 F1: 0.21620 F2: 0.22052 SVM Accuracy: ------- Precision: ------- Recall: ------- F1: ------- F2: ------- DT Accuracy: 0.86553 Precision: 0.47658 Recall: 0.08650 F1: 0.14642 F2: 0.10343 BDT Accuracy: 0.86593 Precision: 0.48509 Recall: 0.08950 F1: 0.15112 F2: 0.10694 K-means Accuracy: 0.83920 Precision: 0.23791 Recall: 0.09350 F1: 0.13424 F2: 0.10642
Verificaremos agora o impacto no algoritmo DT com a Lista de Atributos 2, que contém os 2 novos atributos criados.
Criando os novos Atributos:
data_dict_df_2 = data_dict_df
data_dict_df_2['from_this_person_to_poi_ratio'] = \
data_dict_df_2['from_this_person_to_poi']/data_dict_df_2['from_messages']
data_dict_df_2['from_poi_to_this_person_ratio'] = \
data_dict_df_2['from_poi_to_this_person']/data_dict_df_2['from_messages']
filled_df = data_dict_df_2.fillna(value='NaN')
data_dict_2 = filled_df.to_dict(orient='index')
data_dict_df_2.shape(143, 23)
Agora a base ficou com 23 atributos.
my_dataset_2 = data_dict_2
data_2 = featureFormat(my_dataset_2, features_list_2, sort_keys = True)
data_2[np.isnan(data_2)]=0
labels, features = targetFeatureSplit(data_2)
scaler = preprocessing.MinMaxScaler()
features = scaler.fit_transform(features)
features_train, features_test, labels_train, labels_test = \
train_test_split(features, labels, test_size=0.3, random_state=42)
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='entropy',min_samples_split=50)
dump_classifier_and_data(clf, my_dataset_2, features_list_2)
main()DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=50, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
Accuracy: 0.86413 Precision: 0.42910 Recall: 0.05750 F1: 0.10141 F2: 0.06955
Total predictions: 15000 True positives: 115 False positives: 153 False negatives: 1885 True negatives: 12847
Comparando os resultados da máquina DT sem e com os atributos criados, observa-se piora em todas as métricas; assim, esses atributos não serão incluídas na sintonia do algoritmo.
- Resumo dos resultados
DT sem atributos criados -> Accuracy: 0.86553 Precision: 0.47658 Recall: 0.08650 F1: 0.14642 F2: 0.10343
DT com atributos criados -> Accuracy: 0.86413 Precision: 0.42910 Recall: 0.05750 F1: 0.10141 F2: 0.06955
A calibração (tuning) consiste na otimização da máquina de aprendizagem, na qual são testados várias parametrizações; seu objetivo é que o algoritmo apresente os melhores resultados (métricas) possíveis.
Conforme Birattari (2009), um excesso de ajustes pode provocar um problema semelhante ao (overfitting), conhecido como over-tuning.
Para realizar a calibração (afinação de parâmetros) utilizamos a biblioteca GridSearchCV do sciki-learn, que é uma forma de analisar sistematicamente múltiplas combinações de parâmetros, fazendo validação cruzada ao longo do processo, para determinar qual calibragem (parametrização) apresenta o melhor desempenho.
Calibrando o modelo ...
from sklearn.model_selection import GridSearchCV
parameters = {'criterion':('gini', 'entropy'),
'max_depth': range(1,5),
'max_features': range(1,5),
'class_weight':(None, 'balanced'),
'random_state': [42],
'min_samples_split': range(3,5)
}
cdt = DecisionTreeClassifier()
clf = GridSearchCV(cdt, parameters)
dump_classifier_and_data(clf, my_dataset, features_list)
main()GridSearchCV(cv=None, error_score='raise',
estimator=DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best'),
fit_params={}, iid=True, n_jobs=1,
param_grid={'max_features': [1, 2, 3, 4], 'random_state': [42], 'criterion': ('gini', 'entropy'), 'min_samples_split': [3, 4], 'max_depth': [1, 2, 3, 4], 'class_weight': (None, 'balanced')},
pre_dispatch='2*n_jobs', refit=True, return_train_score=True,
scoring=None, verbose=0)
Accuracy: 0.86160 Precision: 0.39205 Recall: 0.06900 F1: 0.11735 F2: 0.08261
Total predictions: 15000 True positives: 138 False positives: 214 False negatives: 1862 True negatives: 12786
Abaixo seguem os resultados antes e depois da calibração do algoritmo DT, no qual se observa piora em todas as métricas.
Accuracy: 0.86553 Precision: 0.47658 Recall: 0.08650 F1: 0.14642 F2: 0.10343
Accuracy: 0.86160 Precision: 0.39205 Recall: 0.06900 F1: 0.11735 F2: 0.08261
Como o objetivo é que os valores das métricas Precision e Recall sejam de pelo menos 0.3, até aqui isso não foi conseguido. Assim, temos que tentar melhorar a máquina de aprendizagem. A biblioteca SciKit possui mais ferramentas que podem nos auxiliar, vamos utilizá-las.
Agora ao invés de usarmos tão somente nossa intuição para definir as features de entrada, vamos utilizar a biblioteca Feature selection do sciki-learn, mais especificamente a classe SelectKBest que por meio do teste da Análise de Variância ANOVA- ANAlysis of VAriance determina quais as features mais importantes.
from get_Best_features import get_best
best_features = get_best(data_dict)
best_features| feature | score | |
|---|---|---|
| 4 | exercised_stock_options | 24.815080 |
| 9 | total_stock_value | 24.182899 |
| 5 | bonus | 20.792252 |
| 0 | salary | 18.289684 |
| 16 | deferred_income | 11.458477 |
| 17 | long_term_incentive | 9.922186 |
| 6 | restricted_stock | 9.212811 |
| 3 | total_payments | 8.772778 |
| 7 | shared_receipt_with_poi | 8.589421 |
| 11 | loan_advances | 7.184056 |
| 10 | expenses | 6.094173 |
| 18 | from_poi_to_this_person | 5.243450 |
| 13 | other | 4.187478 |
| 14 | from_this_person_to_poi | 2.382612 |
| 15 | director_fees | 2.126328 |
| 1 | to_messages | 1.646341 |
| 2 | deferral_payments | 0.224611 |
| 12 | from_messages | 0.169701 |
| 8 | restricted_stock_deferred | 0.065500 |
De forma a permitir comparação com as features anteriores, adotaremos a mesma quantidade de features (sete), selecionado as que possuírem maior score
features_list = ['poi','exercised_stock_options', 'total_stock_value', 'bonus',
'salary', 'deferred_income', 'long_term_incentive']my_dataset = data_dict
data = featureFormat(my_dataset, features_list, sort_keys = True)
labels, features = targetFeatureSplit(data)#Normalizando as features:
scaler = preprocessing.MinMaxScaler()
features = scaler.fit_transform(features)from sklearn import tree
from sklearn.model_selection import GridSearchCV
parameters = {'criterion':('gini', 'entropy'),
'max_depth': range(1,5),
'max_features': range(1,5),
'class_weight':(None, 'balanced'),
'random_state': [42],
'min_samples_split': range(3,5),
}
cdt = DecisionTreeClassifier()
clf = GridSearchCV(cdt, parameters)
dump_classifier_and_data(clf, my_dataset, features_list)
main()GridSearchCV(cv=None, error_score='raise',
estimator=DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best'),
fit_params={}, iid=True, n_jobs=1,
param_grid={'max_features': [1, 2, 3, 4], 'random_state': [42], 'criterion': ('gini', 'entropy'), 'min_samples_split': [3, 4], 'max_depth': [1, 2, 3, 4], 'class_weight': (None, 'balanced')},
pre_dispatch='2*n_jobs', refit=True, return_train_score=True,
scoring=None, verbose=0)
Accuracy: 0.84429 Precision: 0.35531 Recall: 0.11050 F1: 0.16857 F2: 0.12816
Total predictions: 14000 True positives: 221 False positives: 401 False negatives: 1779 True negatives: 11599
Conforme resultado, essa máquina ainda não atende o requisito de Precision e Recall mínimo de 0.3.
Vamos utilizar agora outra funcionalidade da biblioteca SciKit que é o pipeline, que possibilita combinar múltiplos métodos sucessivamente, combinaremos:
a) Normalização dos dados, utilizando StandardScaler;
b) Seleção das Features mais importantes, utilizando SelectKBest;
c) Redução de dimensionalidade dos dados, utilizando PCA;
d) Otimização, utilizando GridSearchCV; e
e) Validação cruzada, utilizando StratifiedShuffleSplit.
from sklearn.pipeline import Pipeline
from sklearn import preprocessing
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV, StratifiedShuffleSplit
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.feature_selection import SelectKBestCarregando a lista com todos os atributos ...
features_list = ['poi',
'exercised_stock_options',
'total_stock_value',
'bonus',
'salary',
'deferred_income',
'long_term_incentive',
'restricted_stock',
'total_payments',
'shared_receipt_with_poi',
'loan_advances',
'expenses',
'from_poi_to_this_person',
'other',
'from_this_person_to_poi',
'director_fees',
'to_messages',
'deferral_payments',
'from_messages',
'restricted_stock_deferred'
]my_dataset = data_dict
data = featureFormat(my_dataset, features_list, sort_keys = True)
labels, features = targetFeatureSplit(data)features_train, features_test, labels_train, labels_test = \
train_test_split(features, labels, test_size=0.3, random_state=42)Parametrização que será testada ...
CRITERION = ['gini','entropy']
SPLITTER = ['best', 'random']
MIN_SAMPLES_SPLIT = [2,4,8,16]
CLASS_WEIGHT = ['balanced', None]
MIN_SAMPLES_LEAF = [1,2,4,8,16]
MAX_DEPTH = [None,1,2,4,8,16]
SCALER = [None, preprocessing.StandardScaler()]
SELECTOR__K = [10, 13, 15, 18, 'all']
REDUCER__N_COMPONENTS = [2, 4, 6, 8, 10]pipe = Pipeline([
('scaler', preprocessing.StandardScaler()),
('selector', SelectKBest()),
('reducer', PCA(random_state=42)),
('classifier', DecisionTreeClassifier())
])param_grid = {
'scaler': SCALER,
'selector__k': SELECTOR__K,
'reducer__n_components': REDUCER__N_COMPONENTS,
'classifier__criterion': CRITERION,
'classifier__splitter': SPLITTER,
'classifier__min_samples_split': MIN_SAMPLES_SPLIT,
'classifier__class_weight': CLASS_WEIGHT,
'classifier__min_samples_leaf': MIN_SAMPLES_LEAF,
'classifier__max_depth': MAX_DEPTH,
}sss = StratifiedShuffleSplit(n_splits=10, test_size=0.2, random_state=42)grid_search = GridSearchCV(pipe, param_grid, scoring='f1', cv=sss)grid = grid_search.fit(features_train,labels_train)best_clf = grid_search.best_estimator_best_clf Pipeline(steps=[('scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('selector', SelectKBest(k=18, score_func=<function f_classif at 0x7fcd1a2087d0>)), ('reducer', PCA(copy=True, iterated_power='auto', n_components=2, random_state=42,
svd_solver='auto', tol=0.0, whiten=False)), ('classifi...it=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best'))])
from sklearn.externals import joblib
joblib.dump(clf, 'dt_clf.pkl')
joblib.dump(best_clf, 'best_clf.pkl')
dump_classifier_and_data(best_clf, my_dataset, features_list)grid.best_score_0.565959595959596
grid.score(features_test, labels_test)0.34782608695652178
main()Pipeline(steps=[('scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('selector', SelectKBest(k=18, score_func=<function f_classif at 0x7fcd1a2087d0>)), ('reducer', PCA(copy=True, iterated_power='auto', n_components=2, random_state=42,
svd_solver='auto', tol=0.0, whiten=False)), ('classifi...it=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best'))])
Accuracy: 0.67947 Precision: 0.28591 Recall: 0.93750 F1: 0.43819 F2: 0.64398
Total predictions: 15000 True positives: 1875 False positives: 4683 False negatives: 125 True negatives: 8317
Com isto, atendemos ao requisito dos valores mínimos para precision e recall, arrendondano para uma casa decimal.
Accuracy: 0.67947 Precision: 0.28591 Recall: 0.93750 F1: 0.43819 F2: 0.64398
- Precision = 0.3
- Recall = 0.9
Lembrando que o objetivo deste projeto é determinar se um funcionário da Enron é ou não um POI (Persons Of Interest), ou seja, estamos buscando a performance para uma classe específicas, os POIs. Em casos deste tipo, as métricas mais significativas são a recall e a precision.
-
Recall: de todos os casos que deveriam ser rotulados como positivos, isto é POIs, quantos foram corretamente classificados?
A equação para isto é:
$$ Recall = {{True Positives\over { True Positives + False Negatives} }} $$ -
Precision: de todos os itens que foram rotulados como positivos, quantos foram corretamente classificados?
A equação para isto é:
$$ Precison = {{True Positives\over { True Positives + False Positives} }} $$ -
A métrica F1, utilizada como parâmetro em GridSearchCV relaciona as métricas recall e precision, na qual ela é a média harmônica destas duas, sendo sua expressão matemática.
No contexto deste projeto, um Falso Positivo é um inocente que será investigado; considerando uma investigação justa, ele , se inocente, poderá comprovar isto sem problemas no processo judicial. Já um Falso Negativo é um POI que não será investigado, isto é, um provável criminoso que ficará impune, portanto, algo indesejável. Com isto, analisando as equações acima, a métrica recall alta é o mais desejável neste caso. Sendo assim, a interpretação dos valores obtidos com a máquina de aprendizado proposta significam que:
- 90% (recall = 0.9) das vezes que um funcionário, que de fato é um POI, é submetido ao classificador, a máquina o prediz como tal, ou seja, um POI. Em outras palavras, há 10% de Falsos Negativo, também conhecido como Erro Tipo II;
- 30% (precision = 0.3) dos funcionários classificados como POI são realmente pessoas suspeitas de participarem da fraude, em outras palavras, 70% de Falsos Positivos, também conhecido como Erro Tipo I.
Portanto, se a máquina proposta fosse utilizada como tomadora de decisão em processar ou não um funcionário da Enron, teríamos que 10% dos culpados sairiam ilesos e 70% dos processados seriam inocentes.
API design for machine learning software: experiences from the scikit-learn project
Distributed Tuning of Machine Learning Algorithms using MapReduce Clusters