A more detailed writeup is available on my blog here: https://vvrrao.home.blog/hosting-a-custom-nlp-model-on-aws-elastic-kubernetes-service/
Trained a model locally and deployed to the Elastic Kubernetes Service on AWS. The data was from Kaggle: https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews/overview. This is a Sentiment Dataset for Movie reviews. Five Sentiment Labels as follows: 0 - negative 1 - somewhat negative 2 - neutral 3 - somewhat positive 4 - positive
The Notebooks folder has the EDA and Model training. For EDA, I primarily focussed on using the en_core_web_lg model of Spacy to extract Named Entities, Adjectives and Verbs. Was looking for any trends. Below is an Example of the Persons in the corpus arranged by Sentiment Label

The modeling needs a bit more work(ref: NLPonEKS-ModelTraining.ipynb). I did notice that modifying the classes to just Positive-Negative-Neutral made the model much better and I could get and accuracy of 74.4% and the below F1 scores with TFIDF and LinearSVC. Here is the Notebook for that: (https://github.com/vvr-rao/NLP-on-AWS-EKS/blob/main/Notebooks/Other_Ref/TFIDF-with-LinearSVC.ipynb)
precision recall f1-score support
Negative 0.75 0.64 0.69 6943
Neutral 0.73 0.82 0.77 15639
Positive 0.78 0.69 0.74 8630
Beyond a certain point, my learning rate began to stagnate (see below) and I began to look at better modeling tools like Transformers

I was able to get a slightly higher accuracy using BERT (bert-sentiment-model-71pct-accuracy.ipynb). I used the bert-base-cased model and trained the model on Kaggle using the Kaggle provided GPUs. Sensitivity varied between 0.55 - 0.79 based on the class and the model was better at prdicting neutral sentiment (79% accuracy) Again, it gets confused between the degrees of Positivity and Negativity (Somewhat Positive/Negative vs Positive/Negative)
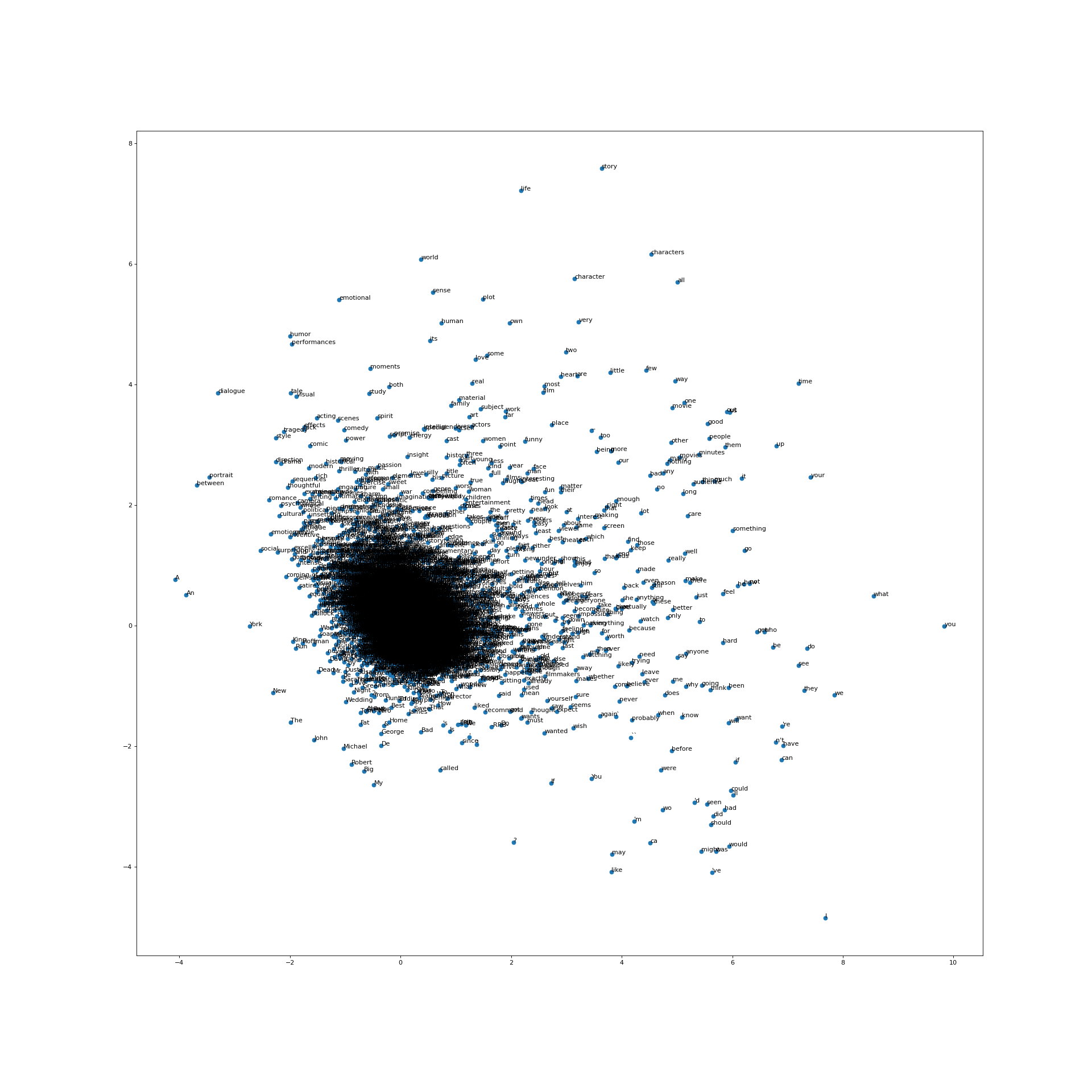
Another approach I am exploring to improve the model is to create Word2Vec vectors and training a model using that (ref: NLPonEKS-EDA-Word2Vec.ipynb). Unfortunately, the dataset might not be large enough for sufficient W2V training and my accuracy is proving to be lower than a simple BOW with CountVectorization and SVM. (I also downloaded and tested the pretrained GoogleNews-vectors-negative300 model - ref: Download_and_Test_Google_Pretrained_W2V_model.ipynb - but had somewhat disappointing results when testing for distances between word pairs like happy-sad. Going to try a few more pre-trained models for word embeddings. )
Below is the 2D representation of my trained Word2Vec model using the data provided. (I tried a few options and this was the best):
In any case, with the trained model, the steps to deploy are as follows;
- Save the model in a .pkl,
- Create a Docker container holding the .pkl and a simple flask app to accept incoming text in a JSON and return the Sentiment
- Publish on AWS EKS. For detail on how to publish a Flask App of EKS, take a look at my other repo here: https://github.com/vvr-rao/Flask-on-AWS-EKS
Model can be called from Postman by passing a POST message with a JSON body. The expected input is of the form {"mytext":""}