Update to use JSON Pointers and Selective Disclosure Primitives #94
Conversation
Added the echidna script
|
This is great work @Wind4Greg, thanks for moving it forward! As this is nearly a wholesale change I think we should merge it in and start the discussions from this starting point. |
There was a problem hiding this comment.
Thanks, this is great! +1 to @brianorwhatever's comments to merge this as a fresh start to drive this work item toward completion.
|
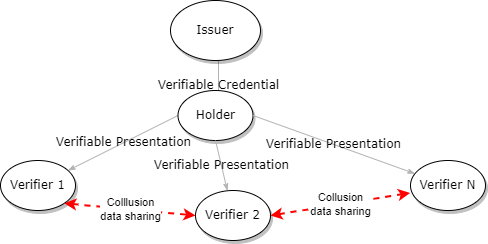
Thanks for the positive comments @brianorwhatever and @dlongley! The two pieces I'm working on separately are the Security Considerations section and the Privacy Considerations section. I'll try to have text and diagrams for that next week. For W3C documents does anyone have a recommended approach to generating diagrams? For the Privacy/unlinkability I wanted to show diagrams that illustrate verifier-verifier collusion, and issuer-verifier collusion, i.e., something like: This was produced with drawio. Cheers Greg |
|
I know @iherman has produced diagrams like the one over here: w3c/vc-data-integrity#210 |
Indeed. @Wind4Greg, to answer to your questions, there is no "recommended" approach but, it so happens, I also use draw.io to generate the diagrams @dlongley is referring to. I think the main points are editorial once the diagrams are ready:
You can look at https://w3c.github.io/vc-data-model/vocab/credentials/v2/vocabulary.html for the details how I did that for VCDM. Other approaches are also possible. |
|
What say you @tplooker can we merge this in? |
index.html
Outdated
| To produce the `revealDocument`, i.e., the unsigned document that will | ||
| eventually be signed and sent to the verifier, we append the selective pointers | ||
| to the mandatory pointers and input these combined pointers along with the | ||
| document without proof to the `selectJsonLd` algorithm of [[DI-ECDSA]] | ||
| to give the result shown below. |
There was a problem hiding this comment.
| To produce the `revealDocument`, i.e., the unsigned document that will | |
| eventually be signed and sent to the verifier, we append the selective pointers | |
| to the mandatory pointers and input these combined pointers along with the | |
| document without proof to the `selectJsonLd` algorithm of [[DI-ECDSA]] | |
| to give the result shown below. | |
| To produce the `revealDocument` (i.e., the unsigned document that will | |
| eventually be signed and sent to the verifier), we append the selective pointers | |
| to the mandatory pointers, and input these combined pointers along with the | |
| document without proof to the `selectJsonLd` algorithm of [[DI-ECDSA]], | |
| to get the result shown below. |
index.html
Outdated
| Now that we know what the revealed document looks like, we need to furnish | ||
| appropriately updated information to the verifier on which statements are | ||
| mandatory, and the indexes for the selected non-mandatory statements. Running | ||
| step 6 of the | ||
| <a href="#createdisclosuredata"></a> yields an abundance of information about | ||
| various statement groups relative to the original document. Below we show a | ||
| portion of the indexes for those groups. |
There was a problem hiding this comment.
| Now that we know what the revealed document looks like, we need to furnish | |
| appropriately updated information to the verifier on which statements are | |
| mandatory, and the indexes for the selected non-mandatory statements. Running | |
| step 6 of the | |
| <a href="#createdisclosuredata"></a> yields an abundance of information about | |
| various statement groups relative to the original document. Below we show a | |
| portion of the indexes for those groups. | |
| Now that we know what the revealed document looks like, we need to furnish | |
| appropriately updated information to the verifier about which statements are | |
| mandatory, and the indexes for the selected non-mandatory statements. Running | |
| step 6 of the | |
| <a href="#createdisclosuredata"></a> yields an abundance of information about | |
| various statement groups relative to the original document. Below we show a | |
| portion of the indexes for those groups. |
index.html
Outdated
| The verifier needs to be able to aggregate and hash the mandatory statements. To | ||
| enable this we furnish them with a list of indexes of the mandatory statements | ||
| adjusted to their positions in the reveal document, i.e., relative to the | ||
| `combinedIndexes`. While the `selectiveIndexes` need to be adjusted relative to | ||
| their positions within the `nonMandatoryIndexes`. These "adjusted" indexes are | ||
| shown below. |
There was a problem hiding this comment.
| The verifier needs to be able to aggregate and hash the mandatory statements. To | |
| enable this we furnish them with a list of indexes of the mandatory statements | |
| adjusted to their positions in the reveal document, i.e., relative to the | |
| `combinedIndexes`. While the `selectiveIndexes` need to be adjusted relative to | |
| their positions within the `nonMandatoryIndexes`. These "adjusted" indexes are | |
| shown below. | |
| The verifier needs to be able to aggregate and hash the mandatory statements. To | |
| enable this, we furnish them with a list of indexes of the mandatory statements | |
| adjusted to their positions in the reveal document (i.e., relative to the | |
| `combinedIndexes`), while the `selectiveIndexes` need to be adjusted relative to | |
| their positions within the `nonMandatoryIndexes`. These "adjusted" indexes are | |
| shown below. |
index.html
Outdated
|
|
||
| <p> | ||
| The last important piece of disclosure data is a mapping of canonical blank node | ||
| ids to HMAC based shuffled ids, the `labelMap`, computed according to Section |
There was a problem hiding this comment.
| ids to HMAC based shuffled ids, the `labelMap`, computed according to Section | |
| IDs to HMAC-based shuffled IDs, the `labelMap`, computed according to Section |
index.html
Outdated
| Finally using the disclosure data above with the algorithm of Section | ||
| <a href="#serializederivedproofvalue"></a> we obtain the signed derived (reveal) |
There was a problem hiding this comment.
| Finally using the disclosure data above with the algorithm of Section | |
| <a href="#serializederivedproofvalue"></a> we obtain the signed derived (reveal) | |
| Finally, using the disclosure data above with the algorithm of Section | |
| <a href="#serializederivedproofvalue"></a>, we obtain the signed derived (reveal) |
There was a problem hiding this comment.
Hi @TallTed and @msporny could we try going about incorporating these changes in a different way? If you look at the commit history of this PR you see a distinct item worked on for each commit. Incorporating changes via the PR review mechanism makes a mess of this history. So I would propose accepting the PR as is and then have @TallTed suggestions come in as a set of individual PR. I'm out of the office without a computer until November 13th so can only review very small PR/changes on my phone. @TallTed in the past I've almost always taken your suggestions so hopefully this approach can work rather than waiting until I return. Cheers Greg
There was a problem hiding this comment.
Hi @TallTed and @msporny could we try going about incorporating these changes in a different way?
Hey @Wind4Greg -- let me see if I can integrate @TallTed's changes... I expect it might not be challenging from my desktop. If I fail to do that, we can fall back to what you're suggesting (but I've very rarely had trouble integrating @TallTed 's changes on many other PRs).
There was a problem hiding this comment.
If you look at the commit history of this PR you see a distinct item worked on for each commit.
It this separation is important, then each of those 27 commits should be (should have been) in its own PR, where change requests will be (would have been) automatically split to the same degree as the commits.
As things stand, I've made 88 change requests on this giant PR. That's what happens to giant PRs. I believe my requested changes can be accepted or rejected individually, or as one batch, or as several batches, through GitHub's web interface. I don't know how well that UI works through a phone. (I hope you at least have a large screen, and maybe the ability to stream it to a big TV.)
I know there's also GitHub Mobile for iOS and Android, but I've never used either so I can't speak to how usable they are for this or any other task.
So far as I know, there's no good way to use GitHub's web interface (the only way I interact with GitHub) to make 88 PRs via 88 branches (one per requested change), nor via 27 branches (one per commit). There might be via CLI git or macOS GitHub Desktop.app, but neither is in my repertoire, yet.
There might be some clever way to do things through the github.dev editor (based on VS code) that will pop up if you type . (period) when you're viewing a repository in the GitHub web UI — which may or may not work in your phone's web browser. I've used this a few times for specific tasks, based on step-by-step guides found in Q&A sites when I needed to do something specific (like move a folder within a repo), but I don't use VS nor this github.dev editor regularly, so can't provide much advice on this either.
I don't know any good way to see only the change requests that apply to any given commit within this PR, so as to retrace my steps and create one PR for each of your commits here with all of my change requests for that commit. That would be a big task with just one change request per commit, but I've clearly averaged 3.25 change requests per Commit (88/27).
Bottom line, I don't see any way past the immediate that won't be a heavy lift for someone. Shortcut suggestions to achieve what you've requested are welcome and will be considered. But as things stand, if my existing change requests on this PR aren't going to be dealt with in context of this PR, then it seems I'll be making a new giant PR, probably with one commit, because that's the fastest and easiest way to recreate these change requests as a PR.
I'll ask that this PR not be merged until I create mine, because that act of merging can change what shows up when I go looking back for/at my change requests, and I don't want to lose any of them.
Co-authored-by: Ted Thibodeau Jr <tthibodeau@openlinksw.com>
|
PR #99 rebased this PR on top of main and merged the changes. |
This PR addresses issue #93 with the following updates to the document:
createShuffledIdLabelMapFunctionwas needed.Preview | Diff