-
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
d5e1c69
commit 1a0a391
Showing
4 changed files
with
280 additions
and
0 deletions.
There are no files selected for viewing
{kind=link}
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,19 @@ | ||
| --- | ||
| title: "" | ||
| date: 2023-02-24 | ||
| draft: true | ||
| description: "" | ||
| summary: "" | ||
| tags: | ||
| - event-driven | ||
| - python | ||
| - multi-treading | ||
| categories: | ||
| - Software Design | ||
| lightgallery: true | ||
| resources: | ||
| - name: featured-image | ||
| src: header.png | ||
| - name: featured-image-preview | ||
| src: header.png | ||
| --- |
{kind=link}
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,261 @@ | ||
| --- | ||
| title: "AWS Step Functions and DAG" | ||
| date: 2023-03-07 | ||
| draft: false | ||
| description: "How to schedule a computation graph (DAG) on AWS Step Functions, ie serverless" | ||
| summary: "How to schedule a computation graph (DAG) on AWS Step Functions, ie serverless" | ||
| tags: | ||
| - aws | ||
| - step-functions | ||
| - stds | ||
| - dag | ||
| categories: | ||
| - Data Engineering | ||
| lightgallery: true | ||
| resources: | ||
| - name: featured-image | ||
| src: header.png | ||
| - name: featured-image-preview | ||
| src: header.png | ||
| --- | ||
|
|
||
| ## Oh DAG! | ||
|
|
||
| Direct acyclic graph, DAG, is a popular data structure to organize large scale | ||
| computation. because it allows you to represent the dependencies between | ||
| different tasks in a clear and efficient manner. DAGs are commonly used in data | ||
| processing, scientific computing, and machine learning applications to manage | ||
| complex workflows. | ||
|
|
||
| Here are some key reasons why DAGs are useful for managing computation: | ||
|
|
||
| - Clear representation of dependencies: A DAG clearly shows the dependencies | ||
| between different tasks, making it easy to understand which tasks must be | ||
| completed before others can begin. | ||
| - Efficient scheduling: With a DAG, it's easy to schedule tasks in the most | ||
| efficient way possible. By prioritizing tasks based on their dependencies, you | ||
| can ensure that each task is executed only when its input data is available, | ||
| which minimizes unnecessary waiting times. | ||
| - Parallelism: DAGs can also be used to identify opportunities for parallelism, | ||
| which can significantly speed up computation. Tasks that don't have | ||
| dependencies can be executed in parallel, making better use of available | ||
| resources. | ||
| - Incremental computation: DAGs can be used to efficiently perform incremental | ||
| computations, where only the necessary parts of a computation are re-run when | ||
| new data becomes available. This can save a significant amount of time and | ||
| resources compared to re-running the entire computation from scratch. | ||
|
|
||
| Overall, DAGs are a powerful tool for managing complex computations, enabling | ||
| efficient scheduling, parallelism, and incremental computation, all while | ||
| providing a clear representation of dependencies between tasks. | ||
|
|
||
| As we can see, with DAG we can significantly parallelize our computations and the | ||
| power of DAG let us to do fearless concurrent computation which fits in the serverless | ||
| land very well. | ||
|
|
||
| ## Existing DAG Based Engines | ||
|
|
||
| There are several libraries and frameworks that use DAGs for managing | ||
| computation. Here are some examples: | ||
|
|
||
| - Apache Airflow: Apache Airflow is a popular open-source platform for managing | ||
| workflows and data pipelines. It uses DAGs to represent the dependencies | ||
| between tasks, and provides a rich set of tools for scheduling, monitoring, | ||
| and executing tasks. | ||
| - Dask: Dask is a Python library for parallel computing that uses DAGs to | ||
| represent computation graphs. It provides a flexible framework for executing | ||
| parallel and distributed computations on large datasets. | ||
| - TensorFlow: TensorFlow is a popular machine learning library that uses DAGs to | ||
| represent computation graphs. It allows users to define complex machine | ||
| learning models as a series of interconnected nodes, with each node | ||
| representing a mathematical operation. | ||
| - Luigi: Luigi is an open-source Python package for building data pipelines. It | ||
| uses DAGs to represent the dependencies between tasks, and provides a flexible | ||
| framework for scheduling and executing tasks. | ||
| - Spark: Apache Spark is a popular distributed computing framework that uses | ||
| DAGs to represent computations. It provides a powerful set of tools for | ||
| parallel and distributed processing of large datasets. | ||
| - These libraries and frameworks are just a few examples of the many tools that | ||
| use DAGs to manage computation. By using DAGs, these tools can provide a clear | ||
| representation of dependencies between tasks, efficient scheduling, and | ||
| parallelism, which can make it easier to manage complex workflows and large | ||
| datasets. | ||
|
|
||
| There are also some libraries, such as Incremental (JaneStreet), Man MDF (Man Group), | ||
| loman, anchors, etc. More details please check: https://wangzhe3224.github.io/awesome-systematic-trading/#computation-graph | ||
|
|
||
| ## Schedule The DAG | ||
|
|
||
| Apart from describe the computation, another important aspect of using DAG for | ||
| computation is the `runtime` or `scheduling runtime`. | ||
|
|
||
| There are different ways to schedule DAG computation based on the nature of the | ||
| tasks, available resources, and performance goals. Here are some examples of | ||
| scheduling strategies: | ||
|
|
||
| - Serial scheduling: In this approach, tasks are executed in a sequential | ||
| manner, one after the other. This is the simplest scheduling strategy and may | ||
| be appropriate for small DAGs with a small number of tasks and dependencies. | ||
| - Parallel scheduling: Tasks are executed concurrently, taking advantage of | ||
| multiple processors or threads. Parallelism can be used when tasks are | ||
| independent or can be executed in parallel without interfering with each | ||
| other. This can speed up computation significantly and is a common strategy | ||
| for large-scale computations. | ||
| - Topological ordering: A topological ordering of the DAG is a linear ordering | ||
| of the nodes such that if there is an edge from node A to node B, then A comes | ||
| before B in the ordering. This ordering can be used to schedule tasks, with | ||
| tasks at the beginning of the ordering executed first, followed by tasks later | ||
| in the ordering. | ||
| - Dynamic scheduling: In this approach, tasks are scheduled at runtime based on | ||
| the availability of data and resources. This can be useful when the execution | ||
| time of tasks is uncertain or when new tasks are added to the DAG at runtime. | ||
| - Batch scheduling: In this approach, tasks are grouped into batches, and each | ||
| batch is executed in parallel. Batching can be useful when the DAG contains a | ||
| large number of tasks and parallelism can be used to speed up computation. | ||
| - Pipeline scheduling: In this approach, tasks are divided into stages, and each | ||
| stage is executed in parallel. Each stage can have its own set of dependencies | ||
| and resources, allowing for efficient use of available resources. This | ||
| approach is commonly used in data processing and machine learning | ||
| applications. | ||
|
|
||
| These scheduling strategies can be combined in different ways to optimize | ||
| performance and resource usage for a given DAG. The choice of scheduling | ||
| strategy depends on the characteristics of the DAG and the available resources. | ||
|
|
||
| ## Can DAG Go Serverless? | ||
|
|
||
| Yes. As we discussed, there are two parts in computation with DAG: computing and | ||
| scheduling. Computing is the bread and butter of serverless, we have Lambda or | ||
| Fargate. However, scheduling is not that straightforward. | ||
|
|
||
| As shown above, most of the DAG based computation engine, such as Spark, we need a | ||
| long running session to coordinate the computation. This long run session need to | ||
| handle the scheduling of the jobs and handling the intermediate results. | ||
|
|
||
| Serverless is not very good at long running tasks. Luckily enough, AWS provides | ||
| a workflow service: [Step Functions](https://aws.amazon.com/step-functions/). | ||
|
|
||
| Step Functions is not a service designed for DAG computation, however we can make | ||
| it our DAG scheduling engine with a bit efforts. | ||
|
|
||
| ### Topological Order | ||
|
|
||
| Say for example, I have following DAG: | ||
|
|
||
| 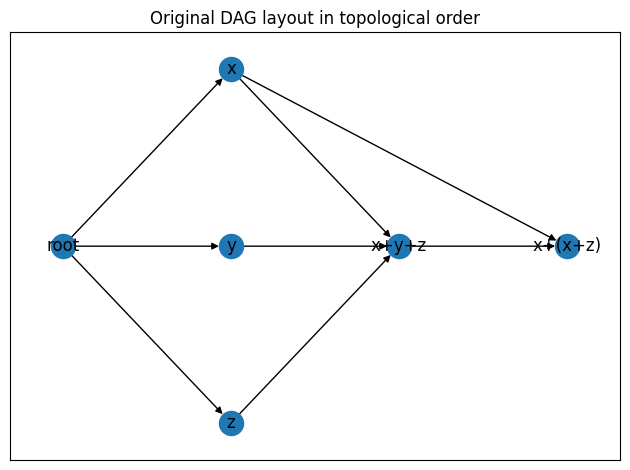 | ||
|
|
||
| First of all, we get the topological order of the DAG as show above. | ||
| With this order, the jobs are organized to several layers, for example, root node | ||
| is at layer 0, `xyz` are in layer 1, etc. | ||
|
|
||
| ### Transitive Reduction | ||
|
|
||
| Notice that there is a dependency from `x` to `x+(x+z)` node, which is a dependency | ||
| goes across two layers. This is not good! Because Step Function do not support this | ||
| kind of workflow. However, if we look at it closely, this dependency is redundant | ||
| in this setup, because by the time we reach `x+(x+z)`, `x` is guaranteed fulfilled. | ||
| This is called `transitive reduction`, meaning G = (V,E) is a graph G- = (V,E-) such that | ||
| for all v,w in V there is an edge (v,w) in E- if and only if (v,w) is | ||
| in E and there is no path from v to w in G with length greater than 1. | ||
|
|
||
| So we can reduce the graph: | ||
|
|
||
| 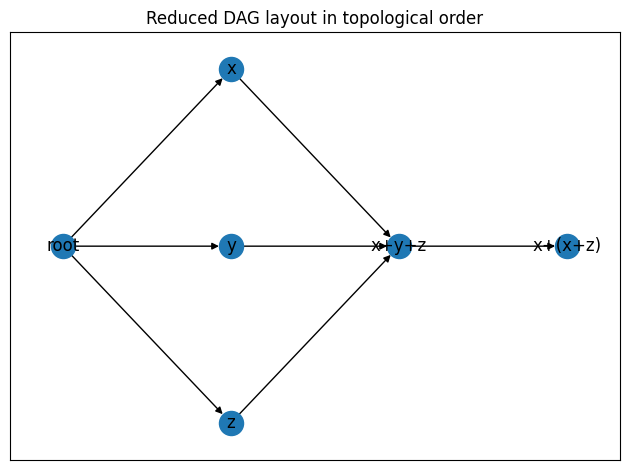 | ||
|
|
||
| This is nice and clean now and we can use Step Function to express this DAG now. | ||
|
|
||
| <img src="https://raw.githubusercontent.com/wangzhe3224/pic_repo/master/images/20230302135312.png" width="60%" height="40%"> | ||
|
|
||
| ### Pass Parameters | ||
|
|
||
| Transitive reduction is good, however there are some node missing input information. | ||
| For example, `x+(x+z)` can never know it need to read `x`. | ||
|
|
||
| Using Step Functions to schedule DAG is a static scheduling, meaning we know exactly | ||
| the execution order, so we can encode the input and output into the config statically | ||
| before running the DAG, see input and output of AWS Step Function for details.[^1] | ||
|
|
||
| ### Intermediate Results | ||
|
|
||
| The next piece is how can we manage the intermediate results? | ||
|
|
||
| There could be many serverless solutions. For example, we can use S3. If we care | ||
| more about the latency, we can use ElasticCache. | ||
|
|
||
| ### General Lambda | ||
|
|
||
| The last piece is what's actually in the Lambda Invoke job in the Step Function | ||
| workflow? | ||
|
|
||
| This function should know how to load parameter from the intermediate store (previous step), | ||
| then should also know which function to call to compute the result, and at last | ||
| store the output to the store. | ||
|
|
||
| Here is some demo code: | ||
|
|
||
| ``` python | ||
| store = S3Store(bucket="some-bucket") | ||
| path = "store/" | ||
|
|
||
| def handler(event, context): | ||
| """ | ||
| Event example: | ||
| { | ||
| "component_name": "HistDataLoader", | ||
| "component_config": { | ||
| "symbol": "ETHUSDT", | ||
| "freq": "5m", | ||
| "lookback": 1, | ||
| "type": "future" | ||
| }, | ||
| "args": null, | ||
| "kwargs": null | ||
| } | ||
| """ | ||
| component_name, config, args, output = event['component_name'], event['component_config'], event['args'], event['output'] | ||
| _cls = getattr(components, component_name) | ||
| obj = _cls(**config) | ||
| if args is None: | ||
| res = obj() | ||
| else: | ||
| argv = [] | ||
| for arg in args: | ||
| d = store.read(f"{path}{arg}") | ||
| argv.append(d) | ||
| res = obj(*argv) | ||
|
|
||
| store.write(f"{path}{output}", res) | ||
|
|
||
| return { | ||
| "output": f"{path}{output}" | ||
| } | ||
| ``` | ||
|
|
||
| ## Potential Issues | ||
|
|
||
| Some times, how to arrange the jobs in different layer is not straightforward. | ||
| Take following graph for example: | ||
|
|
||
| 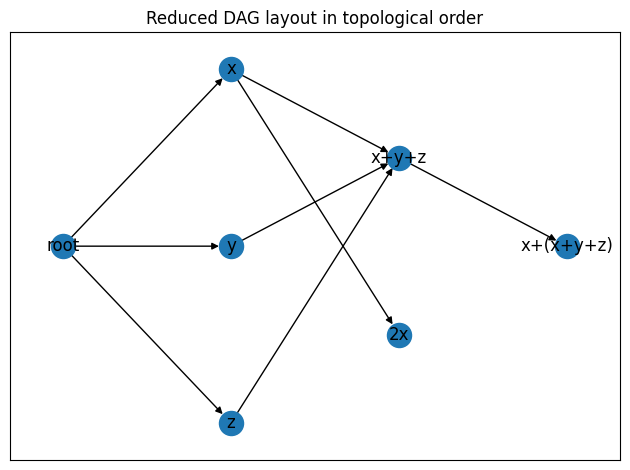 | ||
|
|
||
| node `2x` only depends on `x`, however, if we follow the standard compilation method, | ||
| `2x` can only be executed after all `xyz` nodes finished. | ||
|
|
||
| Another way to schedule `2x` is to put it into the same layer of `xyz`, so that | ||
| `2x` executed immediately after `x` is done. However, in the way, we are risking | ||
| slow down the computation of the whole next layer. For example, if `2x` is a very | ||
| expensive computation in terms of time, it is better to schedule it in the next layer. | ||
|
|
||
| Take it further, event `2x` is scheduled in the next layer, the long computation | ||
| delay problem is not resolved but just pus the delay a bit further. | ||
|
|
||
| Fundamentally, if we cannot predict the runtime of each job, workflow approach | ||
| will suffer this type of issue. | ||
|
|
||
| In order to solve this potential issue, a dynamic scheduling is required, whereas | ||
| essentially workflow is a static scheduling. | ||
|
|
||
| I will leave that with another post. | ||
|
|
||
| [^1]: https://docs.aws.amazon.com/step-functions/latest/dg/concepts-input-output-filtering.html |