Releases: wareya/analyzer
alpha4
Use 64-bit Java if the analyzer gets stuck in initialization.
Update: The user dictionary has been updated. If you downloaded before this update, please download the new user dictionary file in the attachments. It fixes a problem with the sino-japanese words and adds some important overrides for family member names. The updated user dictionary is also in the archive.
Added functionality to make it easier to use the analyzer for mining. Written by someone else. Detailed in #1

alpha3
- Allow analyzing frequency by lexeme or word, not just individual spellings
- Analyzing by lexeme or word causes word or spelling information (respectively) to be pulled out into auxiliary columns
- Normalizer understands this but does not normalize word/spelling occurrences, just adds them
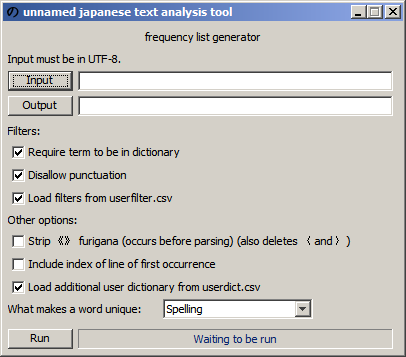
alpha2
- Replace particle, number, and name filter with custom user filters (userfilter.csv).
- Allow command line interface to use user dictionary (enabled by default, like it is in the GUI)
- Normalizer/merger still included

userfilter.csv: Format is BaseWrittenForm, POS1, POS2, POS3, POS4. Words that match all listed fields are ignored. Unused fields are blank. Trailing fields can be omitted.
alpha1
Analyzer:
- Add option to load a user dictionary from userdict.csv. Example userdict.csv contains 自転車.
- Names dictionary still baked in, will remove it and make a second download later.
Normalizer: - Remove outliers instead of trying to adjust distribution. Simpler, works better, smaller impact on resulting distribution.

test7
test6
Adds several megabytes of proper names to the dictionary as dummy entries with worst-case-scenario weight. They have no pronunciation or part of speech information, but they allow kuromoji to generate better segmentations, and therefore a more accurate frequency list, without including the monstrosity that is neologd.
If you hang or run out of memory, make sure you're using 64-bit Java.
use the companion program to combine lists made from different sources: https://github.com/wareya/normalizer

test5
- Fixed mistake where part of speech filter wasn't catching proper names
- Add second branch working off the neologd dictionary instead of the kanaaccent one.
The neologd version uses an indev version of kuromoji.
If your corpus is reasonably large (hundreds of megabytes or larger), you want analyzer.zip.
If your corpus is small (tens of megabytes or smaller) and contains a density of proper names (novels, VNs, etc) you want analyzer_neologd.zip.

EDIT: There was an issue with analyzer.jar in analyzer.zip in this release. If you downloaded it within the first 10 minutes after the release, please redownload it if you have any problems with the part of speech filter.

