Reconciliation overview
This information is accurate at the time of writing (February 2015), but is subject to change.
Reconciliation in WiredTiger is the process of translating a page from its memory resident form to a set of pages in on-disk format.
There are a number of different page types in WiredTiger - each page type has a slightly different reconciliation process. The main page types are:
- Variable length column store leaf pages.
- Fixed length column store leaf pages.
- Column store internal pages.
- Row store leaf pages.
- Row store internal pages.
This document concentrates on row store leaf pages - since they are a common case. Most of the information is relevant for other page types.
WiredTiger has a number of page size configuration settings:
- internal_page_max - the maximum size we will let an on-disk internal page grow to when doing reconciliation.
- internal_key_max - the maximum size a key can be before we store it as an overflow item on an on-disk and in-memory internal page.
- leaf_key_max - the maximum size a key can be before we store it as an overflow item on an on disk and in memory leaf page.
- leaf_page_max - the maximum size for an on-disk leaf page.
- leaf_value_max - the maximum size a value can be before we store it as an overflow item on an on disk and in memory leaf page.
- memory_page_max - how large an in-memory page can grow before we evict it. It may be evicted before it grows. this large if the space it's using in cache is needed.
- split_pct - The percentage of the leaf_page_max we will fill on-disk pages up to when doing reconciliation, if all of the content from the in-memory page doesn't fit into a single page.
The WT_SESSION::create documentation does a better job of explaining these.
The best starting point is to understand the layout of a page in memory. The content of a page is defined in src/include/btmem.h in the __wt_page structure. A row store leaf page is quite complex. It contains:
- An array of items that were on the page when it was loaded into memory (cache) from disk.
WT_PAGE::row::daliased asWT_PAGE::pg_row_d - An array of arrays of inserts. There is one insert list before any items that were read from disk, one between each item read from disk, and one after all items that were read from disk. Read from disk here, means in the
WT_PAGE::pg_row_darray. This is in theWT_PAGE::row::insaliased asWT_PAGE::pg_row_ins - An array of update lists. One update list for each key/value pair read from disk.
- A copy of the on-disk version of this page. This can be NULL if the page was created in memory.
- A page modify structure - that contains a bunch of information that's only interesting once a page has had a modification done to it.
- A read generation - used to help with cache management.
- A memory footprint for the page.
- A page type.
- A flags field.
The first time a page has a modification (an insert, update or delete) applied to it, we create a structure called the "page modify structure" and allocate the insert and update lists described above. The page modify structure is defined in src/include/btmem.h in the __wt_page_modify structure. It contains:
- A number of fields to track transaction information.
- A count of how many dirty bytes the page is contributing to the "dirty cache size"
- A "multi" structure, that contains information about previous versions of the page.
- Information relevant only to leaf pages and column store pages
- Information used to track overflow records referenced by this page.
- A write generation.
- A spinlock used for some page transitions
- A flag field.
A page header followed by a series of key/value pairs. The page header is broken into several sub-headers. The first header is defined in src/include/btmem.h in the ___wt_page_header structure definition. It contains:
- A uint64_t record number, used by column stores (since they don't maintain keys internally)
- A uint64_t write generation
- A uint32_t memory size (actual size required for the data on the page)
- A uint32_t union that is either a count of entries, or a datalen if this is an overflow item.
- A uint8_t page type field
- A uint8_t flags field.
The page header is followed by a "block header". In WiredTiger each page is a block, and it is possible to plug in different "block managers" that manage the transition of pages to and from disk. The default block header is defined in src/include/block.h in the __wt_block_header structure. The block header contains:
- A uint32_t size that is the on-disk size.
- A uint32_t checksum of the page
- A uint8_t flag field
When reconciling a row store leaf page we traverse the in-memory page. We:
- Create a buffer that can hold a page worth of data.
- Start traversing the in-memory page, by first looking at the head of the insert list, then alternating between looking at the key/values read from disk (and any updates that were done to them), and the next entry in the insert list, until we get to the end of the insert list.
At first we traverse the key/value pairs, copying them into the buffer in order. Until we get to a point where we have reached a threshold of "maximum page size * configured split percentage". Once we reach that point we make a record that we've reached a "split boundary".
We keep traversing key/value pairs and inserting them into the buffer. There are two cases:
- We reach the end of the in-memory key/value pairs before the page is full. In that case we write out a single on-disk page.
- There are more key/value pairs than will fit on a single on-disk page. At which case we create an on-disk page image up to the split boundary we recorded when filling the buffer. Then we copy any additional key/value pairs that are in the buffer back to the beginning of the buffer.
If there are key/value pairs remaining, we then continue creating on-disk page images. Each time we have enough key/value pairs to fill an entire on-disk page up to the configured split percent, we save that disk image, and start building a new image.
Once all key/value pairs are consumed we write out all of the disk-image pages that we've created.
This code is in src/reconcile/rec_write.c. The logic around recording split points, and keeping a single page if all data fits into it is managed by the __rec_split function.
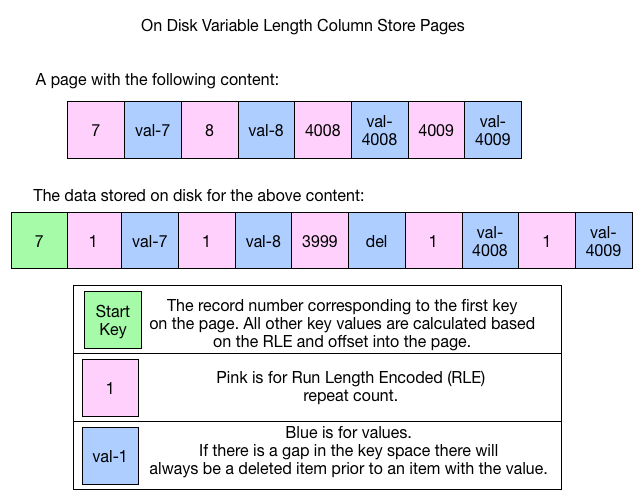
An explanation of the picture:
A page in memory has keys 7, 8, 4008, 4009 on it with associated values. The corresponding on disk page would have:
- A key that has a value of
7, which is the first value on the page. - The page consists of pairs of entries. A count of the number of times a value is duplicated (Run Length Encoding). The content of the value.
- If there are gaps in the key space e.g: between 8 and 4008 in the example. WiredTiger stores a deleted value with a repeat count equivalent to
key gap - 1.