Source: 汤姆喜欢和他的朋友们踢足球。
Target: Tom likes to play soccer with his friends.
Translations:
[RNN]: Tom likes to study friends with his friends.
[TF]: Tom and his friends like soccer.
In this notebook, machine translation is implemented using two deep learning approaches: a Recurrent Neural Network (RNN) and Transformer. Specifically, Sequence to Sequence models for Chinese Mandarin to English translation are trained using anki data. All language models and associated data can be accessed in languages directory. Alternative pre-processing approaches were necessary for languages with different scripts. The notebook demonstrates a unique approach for Chinese Mandarin, but other language groups such as latin script based languages (e.g., English, French, Portuguese, etc.) required alternative pre-processing criteria. For instance, the hgtk package was used to pre-process Hangul script for Korean. Semitic languages such as Arabic and Hebrew required special steps to flip sentence direction prior to model training, and after model inference. Other languages such as Russian were processed more conservatively.
The original NMT notebook and an interactive demo translator can be accessed in the following links.
- NMT Notebook:
- Demo Translator:
[how-to-use]
Encoder and Decoder models for Recurrent Neural Networks and Transformers are implemented in this notebook. The notebook shows a demonstration of data pre-processing, model training, model inference, and model evaluation on predicted sentence translations from Chinese Mandarin to English. The data contains 29371 example bilingual pairs from Anki.
Here are some examples of predicted English sentences compared with actual English sentences from a given Chinese Mandarin sentence for the two approaches. BLEU scores are also shown below.
- Recurrent Neural Network
----------------
Source sentence: <START> 我 在 等 他 。 <END>
Target sentence: <START> i m waiting for him . <END>
Predicted sentence: <START> i m waiting for him . <END>
----------------
Source sentence: <START> 我 寧 願 工 作 也 不 願 閒 著 。 <END>
Target sentence: <START> i prefer working to doing nothing . <END>
Predicted sentence: <START> i d rather stay than i have to lose weight . <END>
----------------
Source sentence: <START> 他 來 自 波 士 頓 。 <END>
Target sentence: <START> i m from boston . <END>
Predicted sentence: <START> he came in boston . <END>
----------------
Source sentence: <START> 湯 姆 買 了 張 機 票 。 <END>
Target sentence: <START> tom bought a plane ticket . <END>
Predicted sentence: <START> tom bought a ticket . <END>
----------------
Source sentence: <START> 我 相 信 他 會 成 功 。 <END>
Target sentence: <START> i m sure that he ll succeed . <END>
Predicted sentence: <START> i believe he ll succeed . <END>
----------------
Loss 1.1556
BLEU 1-gram: 0.236252
BLEU 2-gram: 0.062643
BLEU 3-gram: 0.043685
BLEU 4-gram: 0.039369
----------------
- Transformer
----------------
Source sentence: <START> 我 做 得 好 到 不 能 再 好 了 。 <END>
Target sentence: <START> i can t do any better . <END>
Predicted sentence: <START> i can t do it anymore . <END>
----------------
Source sentence: <START> 我 和 汤 姆 说 了 , 我 觉 得 这 个 主 意 很 好 。 <END>
Target sentence: <START> i told tom that i thought that it was a good idea . <END>
Predicted sentence: <START> i told tom i thought that it was a good idea . <END>
----------------
Source sentence: <START> 汤 姆 已 经 结 婚 了 。 <END>
Target sentence: <START> tom s married . <END>
Predicted sentence: <START> tom has already married . <END>
----------------
Source sentence: <START> 請 你 鎖 門 好 嗎 ? <END>
Target sentence: <START> would you please lock the door ? <END>
Predicted sentence: <START> would you please close the door ? <END>
----------------
Source sentence: <START> 請 告 訴 我 該 怎 麼 做 。 <END>
Target sentence: <START> please tell me what to do . <END>
Predicted sentence: <START> please tell me what to do . <END>
----------------
Loss 2.4514
BLEU 1-gram: 0.230886
BLEU 2-gram: 0.060984
BLEU 3-gram: 0.042378
BLEU 4-gram: 0.038043
----------------
- When the notebook is opened, you will see a screen that looks like this. Note: an internet connection is required for the translator to work.
- To start the notebook, you will need to click this arrow button (this will load necessary packages and code. It will take ~5-15 seconds).
- To start the translator, you will need to click this arrow button as well (this will initially load the Arabic NMT models. It will take ~10-20 seocnds).
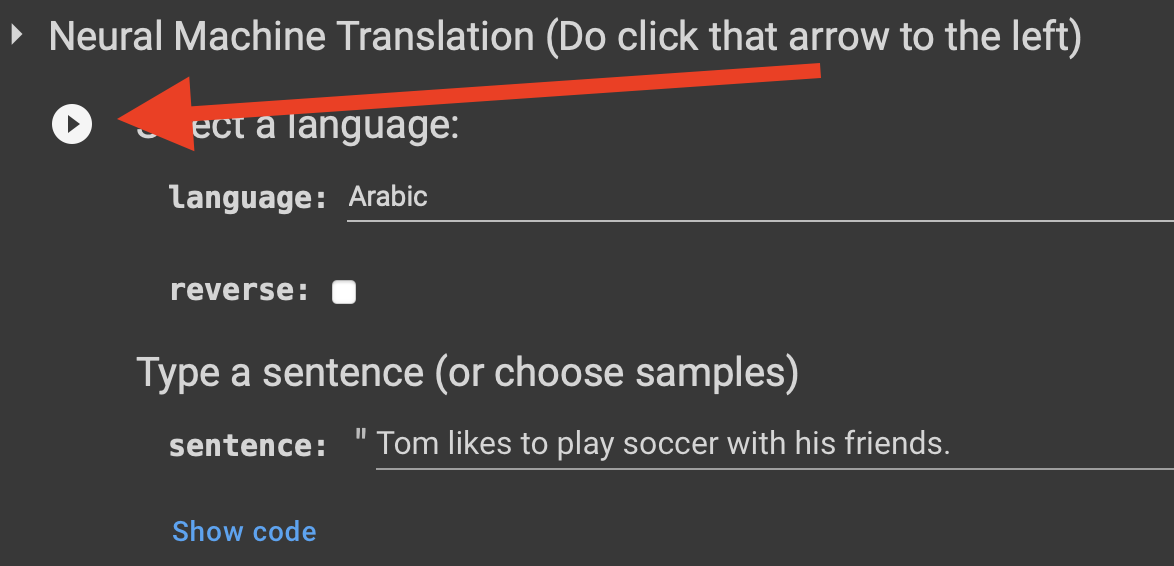
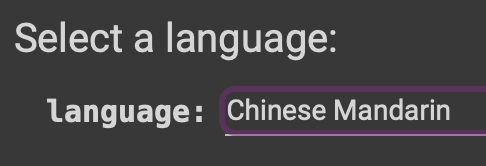
- You can change the language you wish to translate with English (all NMT models are English-[another language], e.g. English-Arabic is supported but Arabic-Portuguese is not). Every time a new language is selected within a session, the necessary NMT models will be loaded, so expect about 15-20 seconds of load time when switching to a new language.
- Type in an input sentence and the translator will return predicted sentence translations in the target language.
- The
Selected translatorshows which NMT models are being used (i.e. each language translator features 8 models, with 4 for each direction, and 2 for each deep learning model type. e.g., the Chinese Mandarin translator includes English-Mandarin and Mandarin-English models, and each direction includes encoder and decoder models for both Recurrent Neural Networks and Transformers). This field also shows which script pre-processing schemes are used for each language (e.g., English useslatin, Chinese Mandarin usesmandarin, Korean useshangul, Arabic usessemitic, Dutch usesgeneral, etc). - Your input sentence is then displayed in original and pre-processed formats.
- Translated sentences for RNN and TF models are shown below the input sentence. After the necessary models are loaded, translation generally take <5 seconds.
- The

- Lastly, the direction of the translator can be reversed by clicking the
reversecheckbox. This allows an input sentence in the selected language to be translated into english (i.e., the default direction is English-[another language]). Fun fact - you may notice that the predicted translations for this input sentence (i.e.,汤姆喜欢和他的朋友们踢足球。) is different between the example shown in the original results (also at the top of this page) and the one generated by the model used in theNeural Translatenotebook app. This happens because the two examples generated unique models (i.e., the training process was non-deterministic, so the two models learned different things!). Generally, the training process would be deterministic for reproducibility purposes, which can be easily modified toward that end. It is still exciting to see two of the "same" models learn different things and produce different results based on the "same" data.

- Have fun with the translator! Remember that the accuracy of the translations are poor compared to models such as Google's NMT model (i.e., what Google Translate uses), which was trained on 25+ billion examples for many languages. The
Neural Translateapp will eventually utilize about 1.2 million examples for all models overall (approximately 300,000 at initial release), so Google's Universal NMT model uses nearly 30,000 times more data to learn from. So, use translation results from this app at your own risk!:)