Incorrect Chinese Characters is converted in PDF outline . #3841
Comments
|
Is this character (U+4E0D) treated correctly in the document itself, and only in the outline/bookmarks it's incorrect? Is Chinese text in UTF-8 format or something else, such as UTF-16? You have checked that the HTML encoding statement matches what the actual encoding is (such as UTF-8), and that the HTML file hasn't been damaged during file transfers and the 0D turned into 0A there? If this character is being seen with a 0D in it, it sounds like it's not UTF-8. Your file transfers are binary or ASCII mode? Is an older Mac involved at any point (line-end x0D)? I have very little experience with multibyte encodings and PDF, so the above are just some guesses at possible problem points to check. |
|
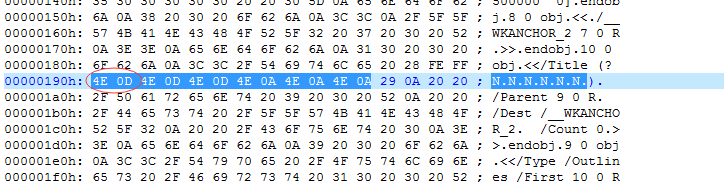
The CJk characters will convert to UTF16 When converting to pdf, the attach file has two pdf file , Incorrect.pdf is generate by wkhtmtopdf, in the Incorrect.pdf 4E 0D is convert to 4E 0A when pdf reader (adobe reader) read it.
in the Correct.pdf the 「不」is writen with (U+4E5C72) , so the pdf reader will convert is to (U+4E0A)
It seems is the problem in the QPdfEngine. According to the PDF standard, it should convert the character when printString to the pdf. Forgive my poor English! |




|
I fixed it by, void QPdfEnginePrivate::printString(const QString &string) {
// The 'text string' type in PDF is encoded either as PDFDocEncoding, or
// Unicode UTF-16 with a Unicode byte order mark as the first character
// (0xfeff), with the high-order byte first.
QByteArray array("(\xfe\xff");
const ushort *utf16 = string.utf16();
for (int i=0; i < string.size(); ++i) {
char part[2] = {char((*(utf16 + i)) >> 8), char((*(utf16 + i)) & 0xff)};
for(int j=0; j < 2; ++j) {
if (part[j] == '(' || part[j] == ')' || part[j] == '\\')
array.append('\\');
if (part[j] == '\r' )
array.append("\\r");
else
array.append(part[j]);
}
}
array.append(")");
write(array);
}
it works fine. |
|
I also encountered this problem, but as a non-professional person in programming I still don‘t know how to fix this bug by using this patch.txt, can someone help me? Thank you so much! |
I encountered this today,
|


It needs to rebuild the QT? |
|
So it sounds to me like an unescaped x0D in text is treated differently between the main PDF and whatever code is handling the outline entries. That is, it's translating x0D to x0A during the building of the PDF, and not after during file transfer or by the Reader. If so, the solution would be to find the outline code and see if other code (as used in the main PDF) could be substituted, or otherwise rewritten to avoid the code which is doing this on-the-fly translation. Perhaps the offending code is not wide-character aware, and treats everything as ASCII? |
Hi,
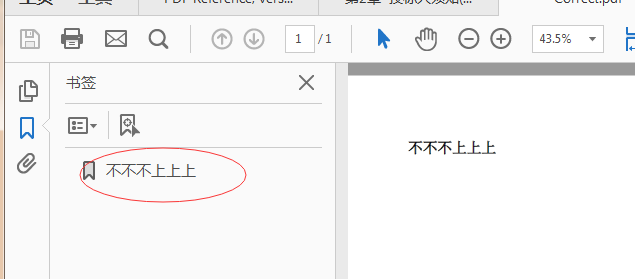
When converting chinese HTML file to PDF format, some Chinese characters in the TOC of result PDF are not correctly converted.
The test.html as :
<h1>不</h1>According to the PDF standard, section 3.2 "If an end-of-line marker appears within a literal string without a preceding backslash, the result is equivalent to(regardless of whether the end-of-line \n marker was a carriage return, a line feed, or both)."
So an end-of-line marker appearing within a literal string without a preceding backslash shall be treated as a byte value of (0Ah).
「不」 (U+4E0D) is incorrectly coverted to「上」(U+4E0A).
good luck.
Sorry For My Bad English.
The text was updated successfully, but these errors were encountered: