Mapping App Factory User Stories with Kubernetes
For the App Factory’s next release, the existing main user stories are being implemented. With the new release, kubernetes is used as the underlying container manager. This document describes what are the main user stories available and how to map those stories with kubernetes features provided with best practices.
POCs were tried out to learn kubernetes concepts, map AF existing user stories to kubernetes concepts etc. You can find some of samples at https://github.com/manjulaRathnayaka/kubernetes_samples.
User Story
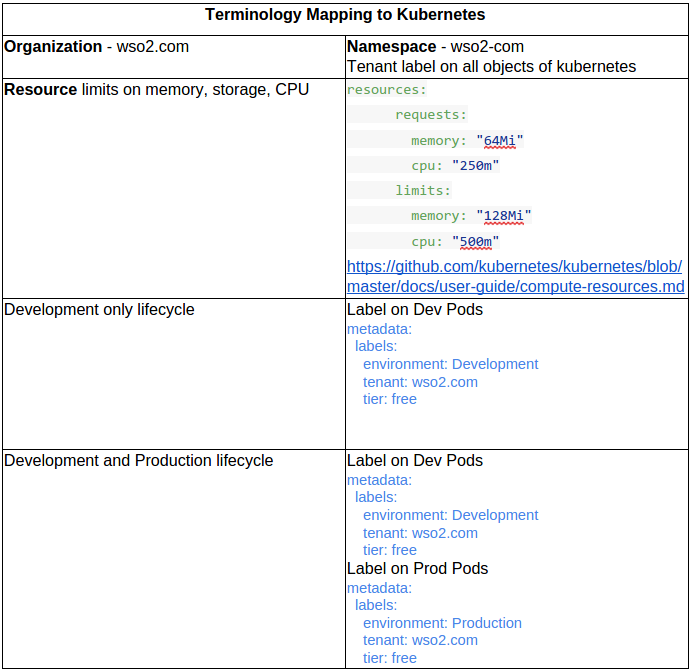
- As an organization all the applications developed inside my organization should be isolated from other organizations.
- As an organization admin, I should be able choose runtimes(such as Tomcat 8.0.28 with Java 8 and wildFly 8.2.0.Final server) for my developers to deploy web applications. Further I should be able to view the available resource limits for above web application servers such as memory, storage and CPU units.
- As an organization admin, I should be able to choose one/more application development life cycles. As an example, for prototyping, development only life cycle is sufficient.
- (Above runtime image resource details and chosen life cycle is useful for identifying the billing requirements. Initially, free tier will consist of predefined number of tomcat containers. Applications can utilize those containers based on the deployment option AF supports.)
How to Implement
User Story
- As a developer, I should be able to use my existing source code at github or upload from filesystem, compile and produce deployable artifacts.
- As a developer, I should be able to create application from the scratch, compile and produce deployable artifacts.
- As a developer, I should be able to commit changes and verify changes on application server.
How to Implement

Builder clone the source code from given repo URL and build an artifact(war files) or image based on build request information. The base image is available in the build request. Built artifact or image is pushed to the git artifact repository or to the docker registry.
User Story
- As a developer I should be able to deploy a built artifact of an application inside a corresponding runtime in a respective lifecycle stage. Furthermore, I should be able to edit the code in my application and after re-deploying the changes should be reflected in the runtime. E.G. I am a developer and I should be able to deploy my Java web application inside Tomcat or my CAR file inside an ESB.
How to Implement
- Deployment Concept with Rolling Updates (newly introduced in kubernetes)

Each new build generates a docker image with a new tag. Tag should reflect the current build time.

In rolling updates, currently deployed container is replaced with new container based on new image.

Managing Multiple Containers in Cloud Environment
With the introduction of container per build causes to have many containers running on a cloud environment when users try to evaluate the app cloud.
- For all free tier customers, each container will be deleted after running for a configured time(1day). If a user tries to use it more than 1 day, user has to activate the runtime again using AF UI. Load balancer level usage tracking was not considered because this applies only for free trial users and this feature is not used for paid accounts. This feature can be implemented based on further use cases.
- Given tenant is allowed defined number of containers(say 10 containers: 6 tomcat instances + 4 wildFly instances). These rules are evaluated based on tier configurations and restrict user creating more application etc. Tier configurations will be further evaluated after initial implementation is completed.
User Story
- As a developer, qa I should be able to view runtime logs corresponding to a certain application version he/she intend to view.
How to Implement
Basically in this story kubernetes itself provide an api to view logs of a running pod. Through this capability we can allow to view the runtime logs of a current pod for the user. But this mechanism is not persistent, when thinking of a persistence and centralized model for logs, we have to think beyond the provided api by kubernetes. So we came up with a solution as below,
Basically we have to use an agent inside the pod that pushes logs out side from the pod (to a network host) generated by each servers. (For this we can use logstash, fluentd .etc) This agent is maintained as a separate container inside the pod. logging storage is mounted as a volatile volume to both server and agent containers.
Then we should use a log analysing tool for centralize the and persist the logs. This tool should receive the logs from a network host and index them. (For this we can use WSO2 DAS, WSO2 Log Analyser, Elasticsearch .etc)
Finally we can query the indexing tool for logs from the AF layer on top and provide the required results for the end user. Following is the deployment architecture that we came up for the log download user story.

User Story
- As a developer, qa, devop I need my application to be available all the time using a single URL corresponding to the lifecycle stages that I have access to.
e.g. I am a developer and I need to access the application version deployed in my preferred runtime using http://apps.wso2.com/tom.com-app1-1.0.0-dev/
How to Implement
When a user clicks a link to launch an application deployed in a given runtime, The request will reach an nginx server either running inside a node or deployed externally which will route the request to a service which fronts containers maintained via a replication controller.
The Ingress kind which comes with kubernetes allows an ingress controller to be deployed in as a container which will have an nginx instance running inside. The controller application talks to the Ingress endpoint of the API Server running on the master node and constantly update its nginx configuration. A sample domain name resolution is given below. Please follow the read me in here to follow an example.

User Story
- As a developer I should be able to define key value pairs in my application. I should also be able to change the values of those variables and use the updated values in the runtime of the application. The example variables user is expecting to keep in the applications environment:
-
- mysql username password
-
- api keys
-
- Specially in ESB app type, user should be able to keep the endpoint reference in xml format in the application environment.
- As a qa I should able to update key value pairs in application from the testing environment.
How to Implement

User Story
As a developer, qa, devops, a runtime should be available for all my applications and all the versions in each application. And also as a developer, qa, devop I should be able to promote or demote my application to a stage that I have the permissions to.
How to Implement


For each application version of each organization in AF needs to maintain a container based on an image. Each environment needs to have different containers running for each application version as well. Each environment will have variables with different values specific to that particular environment. In order to achieve this using Kubernetes, the labels and the label selectors are used. As soon an application version gets built, a new container will be spawned for it. This container will have a label which will identify the tenant domain of the organization, application and it’s version, lifecycle stage and build id. Additionally AF will also maintain a label which identifies the credibility of the user account stating whether it belongs to a free tier or a paid tier.
Once a build is triggered the built artifact is added to the docker registry associated with a tag which will self explain the information related to that application version. Triggering a new build will incur the creation of a new artifact which will have the same information except an updated build id. Hence it will have a new tag. An application version running on a certain environment will have access to the environment variable values defined in that particular environment. These values will be strictly available for that environment. For example if the application uses a MySQL database the username and the password of the MySQL server running in that environment will be evaluated by the application to be the valued defined for that environment.
When an application version is promoted to a certain environment, the artifact will get a new “environment” label denoting the promoted environment. The environmental variable values for the newly promoted environment will be different and the application will be using the new values in its promoted runtime. The application code does not need to change since it reads the MySQL username and password values defined for the server running in the new environment using environmental variables.