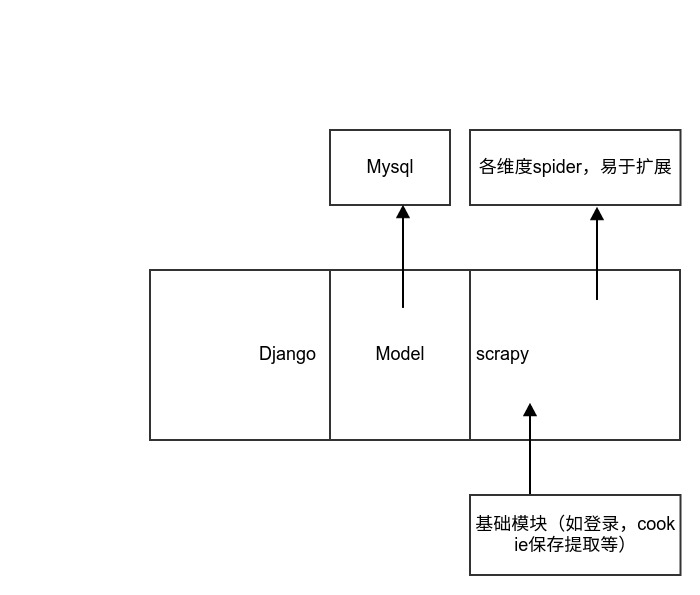
此项目的主要目的是通过不同的spider爬取知乎的数据,目前的项目架构scrapy+django+mysql,将scrapy集成到django中,方面了model的编写以及复用。
此项目的基础模块已编写完成,其中包括知乎的登录,cookies的保存及自动获取等。目前只需要添加不同的spider即可完成不同维度爬虫的扩展。
后期会陆续引如其他组件,以提高整体爬虫的性能。
- windows下一个莫名报错路径问题,ubuntu下无任何问题
- 验证码的自动识别问题
接下来需要做的几件事:
- 通过不同维度编写spider爬取知乎数据
- 完善基础模块提升爬虫的稳定性及爬取性能
- 通过django编写rest API或者view(这个脑洞就大了)