modulespack version2 (AKA mp2)
This is a Framework-Plugin that helps your Web API implement modular calls.
这是一个可以实现子功能模块化的 Web API框架插件
modulespack的设计来源于这样的需求: 很多语音模型并不是端到端进行的,比如传统的ASR就需要先经过声学模型,然后通过语言模型才能得到最终的识别结果,再比如一个训练好的Voice Conversion模型只负责把源语谱图转换为目标说话人语谱图,而前期处理过程(将音频转换为spec)和后期处理过程(将spec转换为音频,也就是Vocoder)是独立于VC的模型进行的,此时如果想要对外提供完整的VC服务,就必须经过这三个子过程,而modulespack要做的就是对这三个子功能进行封装
一个典型的使用modulespack2的程序如下所示:
from session import Session
from graph import ModuleGraph
graph = ModuleGraph(JsonFile='module\GraphLib\RMSE_graph.json')
sess = Session(ModuleLibPath='module\ModuleLib')
feed_dic = {'firstadd':{'x1':1,'x2':2}}
ModuleTable,toposort = sess.build_graph(graph)
result = sess.run(fetches=toposort,ModuleTable=ModuleTable
,graph=graph,feed_dict=feed_dic)
modulespack2借鉴了tensorflow静态图的设计思想,子功能的模块化相当于在计算图中节点化,为此,mp2定义了 ModuleGraph类 来描述节点的集合,同时定义了一种json文件来格式化描述节点与节点之间的数据流动关系。除此之外,mp2还定义了 Session类 来掌控静态图运行的全过程。
以下面这张静态图为例:
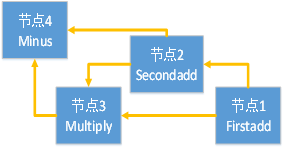
其对应的json文件定义在 module/GraphLib/RMSE_graph.json 文件中

在modulespack2例程里静态图的执行经历了四个过程:
- 首先读取json文件创建graph
- 创建session并构建初始节点(节点1 Firstadd)的feeddict
- 调用session.build_graph构建运行所需要的资源
- 调用session.run执行静态图并返回计算结果
其中session通过调用 build_graph 函数得到该图的拓扑排序和每个节点的module实例:

之后session调用 run 函数根据拓扑排序结果顺序执行每个module:

实例展示: 使用django + modulespack2 搭建的Voice Conversion服务平台