
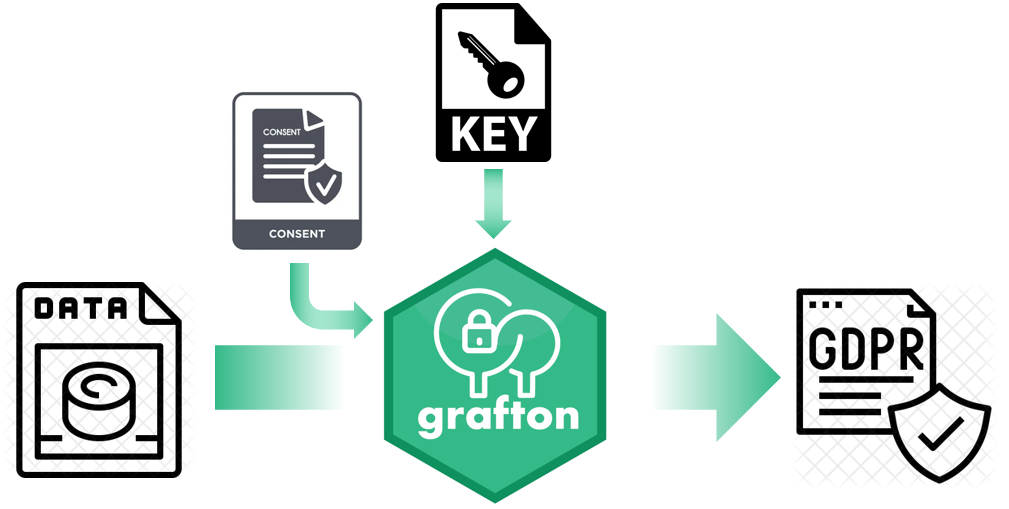
Grafton is a GDPR anonymizer for any file using informed consent, encoding key and randomising numbers
It can anonymize various input files such as CSV, json, XML or other flat files. In line with the GDPR legislation, the mandatory fields have been anonymized, so that any detection of the subjects is prevented.
The encryption key for this anonymization process is provided in a separate file (CSV) and must be stored securely afterwards. In accordance with the GDPR, data is only retained when informed consent is given. Consent can be provided in a separate CSV file. The tracked numbers can also be randomized within a similar order of magnitude.
The use of this package does not guarantee compliance with the GDPR. This package only performs the steps described above.
This package is developed by the AI team at VIVES University of Applied Sciences and is used in our research on demand forecasting.
Grafton works with any extension, but is initially designed to anonymise the file flatfile.csv:
- with a list of replacement values in the key file: pseudonyms.csv
- retaining only users with consent in a list in the consent file: consent.csv
The anonymised file export.csv (any extension possible again) is then saved to the current directory.
The script has default names for all the lists and files to anonymise, but these can be altered if needed.
-
Install python3.7+
-
Create a virtual env where you want to install:
$> python3 -m venv grafton -
Activate the environment
$> source grafton/bin/activate -
Install the package with pip
$> pip install grafton
from grafton import randomise_number
int_number = 5
randomized_number = randomise_number(int_number)from grafton import anonymise
import pandas as pd# The pseudoynyms file
pseudonyms_url = 'https://raw.githubusercontent.com/yForecasting/grafton/main/grafton/pseudonyms.csv'
pseudonyms_file = pd.read_csv(pseudonyms_url, sep = ';')
# The consent file with the entries they gave their consent
consent_url = 'https://raw.githubusercontent.com/yForecasting/grafton/main/grafton/consent.csv'
consent_file = pd.read_csv(consent_url)
# The location of the flatfile to be anonymized
flat_file = 'https://raw.githubusercontent.com/yForecasting/grafton/main/grafton/flatfile.csv'
# The location of the export file
export_file = '/content/export.csv'
anonymise(pseudonyms_file = pseudonyms_url, consent_file = consent_url, flat_file = flat_file, export_file = export_file)Original data read.
Export started.
Wait for the end of script signature!
Grafton complete.
---- end of script ----
Contribution is welcomed!
Start by reviewing the contribution guidelines. After that, take a look at a good first issue.
grafton does not save, publish or share with anyone any identifiable user information.
The use of this package does not guarantee compliance with the GDPR. This package only performs the steps described above.
The AI team at VIVES University of Applied Sciences builds and maintains grafton to make it simple and accessible. We are using this software in our research on demand forecasting. A special thanks to Ruben Vanhecke and Filotas Theodosiou for their contribution.