mapreduce
-
用于处理超大数据集计算的MapReduce编程模型的实现。
-
map 和 reduce是一种阻塞关系
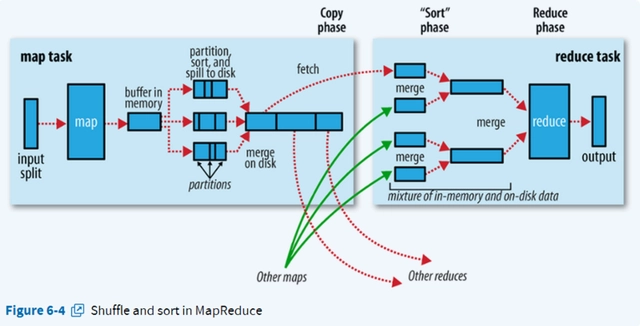
在进行海量数据处理时,外存文件数据I/O访问会成为一个制约系统性能的瓶颈,因此,Hadoop的Map过程实现的一个重要原则就是:计算靠近数据,这里主要指两个方面
代码靠近数据:原则:本地化数据处理(locality),即一个计算节点尽可能处理本地磁盘上所存储的数据;尽量选择数据所在DataNode启动Map任务;这样可以减少数据通信,提高计算效率
数据靠近代码:当本地没有数据处理时,尽可能从同一机架或最近其他节点传输数据进行处理(host选择算法)。
map task只读取split分片,split与block(hdfs的最小存储单位,默认为128MB)可能是一对一也能是一对多,但是对于一个split只会对应一个文件的一个block或多个block,不允许一个split对应多个文件的多个block;
这里切分和输入数据的时会涉及到InputFormat的文件切分算法和host选择算法。
文件切分算法:
splitSize=max{minSize, min{gogalSize,blockSize}}
goalSize: 它是根据用户期望的InputSplit数目计算出来的,即totalSize/numSplits。其中,totalSize为文件的总大小;numSplits为用户设定的Map Task个数,默认情况下是1;
minSize:InputSplit的最小值,由配置参数mapred.min.split.size确定,默认是1;
blockSize:文件在hdfs中存储的block大小,不同文件可能不同,默认是128MB。
作用:将map的结果发送到相应的reduce端,总的partition的数目等于reducer的数量。
把内存缓冲区中的数据写入到本地磁盘,在写入本地磁盘时先按照partition、再按照key进行排序(quick sort);
内存缓冲区默认大小限制为100MB,它有个溢写比例(spill.percent),默认为0.8,当缓冲区的数据达到阈值时,溢写线程就会启动,先锁定这80MB的内存,执行溢写过程,maptask的输出结果还可以往剩下的20MB内存中写,互不影响。然后再重新利用这块缓冲区,因此Map的内存缓冲区又叫做环形缓冲区。
在将数据写入磁盘之前,先要对要写入磁盘的数据进行一次排序操作,先按<key,value,partition>中的partition分区号排序,然后再按key排序,这个就是sort操作,最后溢出的小文件是分区的,且同一个分区内是保证key有序的。
执行combine操作要求开发者必须在程序中设置了combine(程序中通过job.setCombinerClass(myCombine.class)自定义combine操作)。
程序中有两个阶段可能会执行combine操作:
1、map输出数据根据分区排序完成后,在写入文件之前会执行一次combine操作(前提是作业中设置了这个操作);
2、如果map输出比较大,溢出文件个数大于3(此值可以通过属性min.num.spills.for.combine配置)时,在merge的过程(多个spill文件合并为一个大文件)中还会执行combine操作;
注意事项:不是每种作业都可以做combine操作的,只有满足以下条件才可以:像求和就可以做combine、而求平均数就不能做combine
当map很大时,每次溢写会产生一个spill_file,这样会有多个spill_file,而最终的一个map task输出只有一个文件,因此,最终的结果输出之前会对多个中间过程进行多次溢写文件(spill_file)的合并,此过程就是merge过程。也即是,待Map Task任务的所有数据都处理完后,会对任务产生的所有中间数据文件做一次合并操作,以确保一个Map Task最终只生成一个中间数据文件。
如果生成的文件太多,可能会执行多次合并,每次最多能合并的文件数默认为10,可以通过属性min.num.spills.for.combine配置;
多个溢出文件合并时,会进行一次排序,排序算法是多路归并排序;
最终生成的文件格式与单个溢出文件一致,也是按分区顺序存储,并且输出文件会有一个对应的索引文件,记录每个分区数据的起始位置,长度以及压缩长度,这个索引文件名叫做file.out.index。
作用:拉取数据; 过程:Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为这时map task早已结束,这些文件就归NodeManager管理在本地磁盘中。
默认情况下,当整个MapReduce作业的所有已执行完成的Map Task任务数超过Map Task总数的5%后,JobTracker便会开始调度执行Reduce Task任务。然后Reduce Task任务默认启动mapred.reduce.parallel.copies(默认为5)个MapOutputCopier线程到已完成的Map Task任务节点上分别copy一份属于自己的数据。 这些copy的数据会首先保存的内存缓冲区中,当内冲缓冲区的使用率达到一定阀值后,则写到磁盘上。
这个内存缓冲区大小的控制就不像map那样可以通过io.sort.mb来设定了,而是通过另外一个参数来设置:mapred.job.shuffle.input.buffer.percent(default 0.7), 这个参数其实是一个百分比,意思是说,shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task。
如果该reduce task的最大heap使用量(通常通过mapred.child.java.opts来设置,比如设置为-Xmx1024m)的一定比例用来缓存数据。默认情况下,reduce会使用其heapsize的70%来在内存中缓存数据。如果reduce的heap由于业务原因调整的比较大,相应的缓存大小也会变大,这也是为什么reduce用来做缓存的参数是一个百分比,而不是一个固定的值了。
Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活,它基于 JVM 的heap size设置,因为 Shuffle 阶段 Reducer 不运行,所以应该把绝大部分的内存都给 Shuffle 用。
这里需要强调的是,merge 有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式是不启用的。当内存中的数据量到达一定阈值,就启动内存到磁盘的 merge。这和map端的很类似,这实际上就是溢写的过程,在这个过程中如果你设置有Combiner,它也是会启用的,然后在磁盘中生成了众多的溢写文件,这种merge方式一直在运行,直到没有 map 端的数据时才结束,然后才会启动第三种磁盘到磁盘的 merge方式生成最终的那个文件。
在远程copy数据的同时,Reduce Task在后台启动了两个后台线程对内存和磁盘上的数据文件做合并操作,以防止内存使用过多或磁盘生的文件过多。
merge的最后会生成一个文件,大多数情况下存在于磁盘中,但是需要将其放入内存中。当reducer 输入文件已定,整个 Shuffle 阶段才算结束。然后就是 Reducer 执行,把结果放到 HDFS 上。
hdfs暴露数据的位置。
资源管理 任务调度
1、CLI
1、会根据每次的计算数据,咨询NN元数据(block) -》算:split得到一个切片的【清单】
- map的数量就有了
- split是逻辑的,block是物理的。offset和block有映射关系
- block身上有offset、location
- 结果:split包含偏移量、以及split对应的map任务应该移动到哪些节点。
- 可以支持计算向数据移动。
2、生成计算程序未来运行时的相关配置(xml)
3、未来的移动应该相对可靠
- cli会将jar、split清单、配置xml 上传到hdfs的目录中(副本数10个,任务结束数据将会被删除)
4、cli会调用JobTracker,通知到启动一个计算程序了,并且告知文件都放在了hdfs的哪些地方。
2、JobTracker - 资源管理/任务调度
1、从hdfs中取回 【split清单】
2、根据自己收到的TaskTracker汇报的资源,最终确定每一个split对应的map应该去到哪一个节点 【确定清单】
3、未来,TaskTracker在心跳的时候会取回分配给自己的任务信息
问题:
1、单点故障
2、压力过大
3、集成了资源管理和任务调度,两者耦合,未来新的计算框架不能复用资源管理
3、TaskTracker - 任务管理/资源汇报
1、在心跳取回任务后
2、从hdfs中下载jar、xml到本机
3、最终启动任务描述中的MapTask/ReduceTask
- 最终,代码在某一个节点上被启动,是通过cli上传,TaskTracker下载
在Yarn中只有ResourceManager和NodeManager是长服务。解耦资源管理和任务调度(之前都是JobTracker)。将资源管理抽象出来公共使用,而任务调度由临时进程ApplicationMaster负责。
1、cli(切片清单/配置/jar/上传到hdfs)访问ResourceManager申请ApplicationMaster
2、ResourceManager选择一台不忙的节点通知NodeManager启动一个Container,在里面反射一个ApplicationMaster
3、启动ApplicationMaster,从hdfs下载切片清单,向ResourceManager申请资源
4、由ResourceManager根据自己掌握的资源情况得到一个确定清单,通知NodeManager启动Container
5、Container启动后会反向注册到已启动的ApplicationMaster
6、ApplicationMaster(曾经的JobTracker阉割版不带资源管理)最终将任务Task发送给Container(消息)
7、Container从hdfs下载jar/配置 反射相应的Task类为对象,调用方法执行,其结果就是我们的业务逻辑代码的执行
8、计算框架都有Task失败重试机制
1、准备输入的文件
> vim data.txt
hello world
hello spark
hello hadoop
hello yarn
mapreduce
2、在hdfs中创建输入目录
> hdfs dfs -mkdir -p /data/wc/input
3、将准备好的文件上传到指定目录
> hdfs dfs -put data.txt /data/wc/input
4、切换到示例jar包目录
> cd ${HADOOP_HOME}/share/hadoop/mapreduce
5、运行
> hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /data/wc/input /data/wc/output
/data/wc/input:
1、创建一个maven项目
2、在pom.xml中添加依赖
- 在https://mvnrepository.com/中搜索hadoop
- 选择[Apache Hadoop Client Aggregator] 这个将hadoop的相关依赖聚合在了一起,只用引入这一个即可。
- 选择对应的版本3.1.4,复制依赖配置到pom.xml中
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
3、添加配置文件
- 将core-site.xml/hdfs-site.xml/mapred-site.xml/yarn-site.xml复制到resources下
4、创建java文件MyWordCount.java
package com.msb.hadoop.mapreduce.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class MyWordCount {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 识别本地resources目录下的配置
Configuration conf = new Configuration(true);
// 创建一个Job
Job job = Job.getInstance(conf);
job.setJarByClass(MyWordCount.class); // 必须要写,反射使用
job.setJobName("first_wc");
// 这种方式淘汰了
// job.setInputPath(new Path("in"));
//job.setOutputPath(new Path("out"));
Path infile = new Path("/data/wc/input"); // 这里写死,实际通过参数传入
TextInputFormat.addInputPath(job, infile);
Path outfile = new Path("/data/wc/output");
if (outfile.getFileSystem(conf).exists(outfile)) outfile.getFileSystem(conf).delete(outfile);
TextOutputFormat.setOutputPath(job, outfile);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
}
}
5、创建MyMapper.java
package com.msb.hadoop.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
// hadoop框架中,它是一个分布式 数据 序列化、反序列化
// hadoop有自己的一套可以序列化与反序列化
// 或者自己开发类型,但是必须实现序列化、反序列化接口 和 比较器接口
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// key是每一行字符串自己第一个字节面向源文件的偏移量
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
6、创建MyReducer.java
package com.msb.hadoop.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text,IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
// 相同的key为一组,这一组key调用一次reduce
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
> 7、打包 复制 执行
- 点击IDE右侧的maven 先clean在package 生成my_mr-1.0-SNAPSHOT.jar jar包
- 复制在target中生成的jar包到${HADOOP_HOME}/share/hadoop/mapreduce中
- 运行 hadoop jar my_mr-1.0-SNAPSHOT.jar com.msb.hadoop.mapreduce.wc.MyWordCount
MapTask input -> map -> output
input:(split+format) 通用的知识,未来的spark底层也是
来自于我们的输入格式化类,给我们实际返回的记录读取器对象
TextInputFormat -> LineRecordRecorder
- split: file、offset、length
- initialize():
in = fs.open(file).seek(offset)
除了第一个切片对应的map,之后的map都在init环节从切片包含的数据中,让出第一行,并把切片的起始更新为切片的第二行。
换言之,前一个map会多读取一行,来弥补hdfs把数据切割的问题~!
- nextKeyValue()
读取数据中的第一条记录对key,value赋值
返回布尔值
- getCurrentKey()
- getCurrentValue()
output:
NewOutputCollector
partitioner
collector
MapOutputBuffer
- map输出的KV会序列化成字节数组,算出P,最中是3元组:K,V,P
- buffer是使用的环形缓冲区:
1,本质还是线性字节数组
2,赤道,两端方向放KV,索引
3,索引:是固定宽度:16B:4个int a)Partition、b)KeyStart、c)ValueStart、d)ValueLength
5,如果数据填充到阈值:80%,启动线程:
快速排序80%数据,同时map输出的线程向剩余的空间写
快速排序的过程:是比较key排序,但是移动的是索引
6,最终,溢写时只要按照排序的索引,卸下的文件中的数据就是有序的
注意:排序是二次排序(索引里有P,排序先比较索引的P决定顺序,然后在比较相同P中的Key的顺序)
分区有序 : 最后reduce拉取是按照分区的
分区内key有序: 因为reduce计算是按分组计算,分组的语义(相同的key排在了一起)
7,调优:combiner
1,其实就是一个map里的reduce 按组统计
2,发生在哪个时间点:
a)内存溢写数据之前排序之后。溢写的io变少~!
b)最终map输出结束,过程中,buffer溢写出多个小文件(内部有序)
minSpillsForCombine = 3
map最终会把溢写出来的小文件合并成一个大文件:避免小文件的碎片化对未来reduce拉取数据造成的随机读写
也会触发combine
3,combine注意
必须幂等
例子:1,求和计算(幂等)。2,平均数计算(非幂等)
- init():
spillper = 0.8
sortmb = 100M
sorter = QuickSort
comparator = job.getOutputKeyComparator();1,优先取用户覆盖的自定义排序比较器、2,保底,取key这个类型自身的比较器
combiner minSpillsForCombine = 3
SpillThread sortAndSpill() if (combinerRunner == null)
ReduceTask input -> reduce -> output
map:run: while (context.nextKeyValue()) 一条记录调用一次map
reduce:run: while (context.nextKey()) 一组数据调用一次reduce
doc:
1,shuffle: 洗牌(相同的key被拉取到一个分区),拉取数据
2,sort: 整个MR框架中只有map端是无序到有序的过程,用的是快速排序
- reduce这里的所谓的sort其实你可以想成就是一个对着map排好序的一堆小文件做归并排序
3,reduce:
run:
Iter = shuffle。。//reduce拉取回属于自己的数据,并包装成迭代器~!真@迭代器
- file(磁盘上)-> open -> readline -> hasNext() next()
- 时时刻刻想:我们做的是大数据计算,数据可能撑爆内存~!
comparator = job.getOutputValueGroupingComparator();
1,取用户设置的分组比较器
2,取getOutputKeyComparator();优先取用户覆盖的自定义排序比较器, 保底,取key这个类型自身的比较器