- Deeplabv3+的PyTorch实现
- backbone文件夹中为Deeplabv3+的骨干网络ResNet
- aspp.py:aspp模块的实现
- decoder.py:Deeplabv3+中解码模块的实现
- build_bk.py:建立骨干网络的代码
- deeplabv3_plus.py:网络实现的主函数
- 本文为deeplabv3+的论文学习笔记,原论文链接:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- 读完论文有几个需要去思考的点:
- Depthwise separable convolution
- Xception
- deeplabv3+代码实现
-
空间金字塔池化模块(spatial pyramid pooling,SPP) 和 编码-解码结构(encode-decoder) 用于语义分割的深度网络结构。
-
空间金字塔模块在输入feature上应用多采样率扩张卷积、多感受野的卷积或池化,探索多尺度上下文信息。 Encoder-Decoder结构通过逐渐恢复空间信息来捕捉清晰的目标边界。
-
The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. -
DeepLabv3+结合了这两者的优点,具体来说,以DeepLabv3为架构,在此基础上添加了简单却有效的decoder模块用于细化分割结果尤其是目标边界部分。
-
此外论文进一步探究了以Xception结构为模型主干,并探讨了Depthwise separable convolution在ASPP和decoder模块上的应用,最终得到了更快更强大的encoder-decoder网络。
-
在DeepLabv3+中,使用了两种类型的神经网络,使用空间金字塔模块spp和encoder-decoder结构做语义分割。
- 空间金字塔:通过在不同分辨率上以池化操作捕获丰富的上下文信息
- encoder-decoder架构:逐渐的获得清晰的物体边界
-
为了捕获多个尺度的上下文信息,DeepLabv3应用具有不同速率的几个并行的atrous卷积(称为Atrous Spatial Pyramid Pooling,或ASPP),而PSPNet执行不同网格尺度的池化操作。
-
即使在最后的特征映射中编码了丰富的语义信息,由于在网络主干内具有跨步操作的池化或卷积,因此缺少与对象边界相关的详细信息。
-
encoder-decoder 模型使其自身在encoder路径中更快地计算(因为没有特征被扩张)并且decoder路径中逐渐修复尖锐对象边界。试图结合两种方法的优点,我们建议通过结合多尺度上下文信息multi-scale contextual information来丰富encoder-decoder网络中的encoder模块。
-
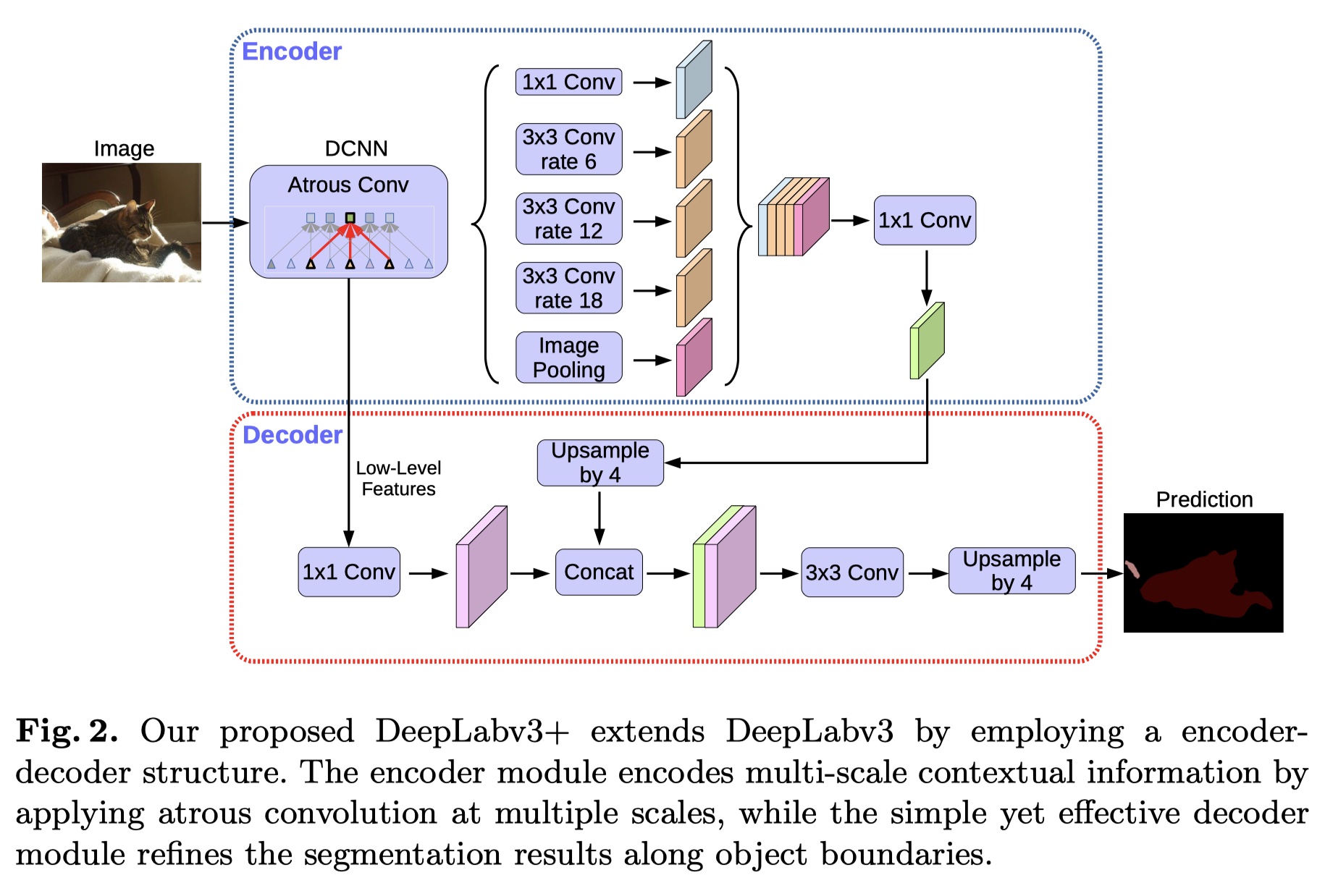
DeepLabv3 +,通过添加一个简单但有效的解码器模块来扩展DeepLabv3,以恢复对象边界,如下图所示。丰富的语义信息在DeepLabv3的输出中进行编码,带有atrous卷积允许人们根据计算资源的预算来控制编码器特征的密度。 此外,decoder模块可恢复详细的对象边界。

-
由于最近深度可分离卷积的成功,对于语义分割的任务我们也通过调整Xception模型来探索这种操作,并在速度和准确性方面表现出改进,并将atrous separable convolution应用于ASPP和解码器模块。
-
总之,本文的主要贡献是:
-
提出了一种新颖的encoder-decoder结构,它采用DeepLabv3作为功能强大的encoder模块和简单而有效的decoder模块。
-
提出的encoder-decoder结构中,可以通过atrous卷积任意控制提取的encoder特征的分辨率,以折中精度和运行时间,这对于现有的encoder-decoder模型是不可能的。
-
将Xception模型用于分割任务,并将深度可分离卷积depthwise separable convolution应用于ASPP模块和decoder模块,从而产生更快更强的encoder-decoder网络。
-
-
基于完全卷积网络(FCNs)的模型已经证明了在几个分割基准(benchmark)上的显着改进。提出了几种模型变体来利用上下文信息(contextual information)进行分割,包括那些采用多尺度输入(multi-scale inputs)的模型(即图像金字塔)或那些采用概率图模型(如DenseCRF和有效推理算法)。 在这项工作中,我们主要讨论使用空间金字塔池化(spatial pyramid pooling)和encoder-decoder结构的模型。
-
Spatial pyramid pooling:
- 如PSPNet或DeepLab,在几个网格尺度grid scales(包括图像级池化imagelevel pooling)执行空间金字塔池SPP或应用几个并行的atrous卷积其中不同的的rates(Atrous Spatial PyramidPooling,或ASPP)。 通过利用多尺度信息multi-scale information,这些模型已经在几个分割基准上显示出有希望的结果。
-
Encoder-decoder:
- 编码器-解码器网络已成功应用于许多计算机视觉任务,包括人体姿态估计human pose estimation,物体检测和语义分割。通常,编码器-解码器网络包含(1)逐渐减少特征图并捕获更高语义信息的encoder模块,以及(2)逐渐恢复空间信息的decoder模块。基于这个想法,我们建议使用DeepLabv3 作为encoder模块,并添加一个简单而有效的decoder模块,以获得更清晰的分割。
-
Depthwise separable convolution:
- 深度可分卷积(Depthwise separable convolution)或群卷积(group convolution),是一种强大的操作,可以在保持相似(或略微更好)的性能的同时降低计算成本和参数数量。这个操作已经被许多最近的神经网络设计采用。特别是,我们探索了Xception模型,类似于用于COCO2017检测挑战的提交,并在语义分割任务的准确性和速度方面表现出改进。
- 在本节中,我们简要介绍了atrous卷积和深度可分卷积depthwise separable convolution。 然后我们回顾一下DeepLabv3,它之前用作encoder器模块。我们还提出了一个改进的Xception模型,它通过更快的计算进一步提高了性能。
-
Atrous convolution:
- Atrous卷积,允许我们明确控制深度卷积神经网络计算的特征的分辨率,并调整滤波器的视野以捕获多尺度信息,推广标准卷积运算。
- 特别地,在二维信号的情况下,对于输出特征映射y和卷积滤波器w上的每个位置i,如下在输入特征图x上应用atrous卷积:
$$ y[i] = \sum_{k}x[i+r.k]w[k] $$ - 其中,atrous rate r决定了我们对输入信号进行采样的步幅。
-
Depthwise separable convolution:
Depthwise separable convolution, factorizing a standard convolution into a depthwise convolution followed by a pointwise convolution (i.e., 1 × 1 convolution), drastically reduces computation complexity.- 深度可分卷积,将标准卷积分解为深度卷积,然后是逐点卷积(即1×1卷积),大大降低了计算复杂度。
- 具体地,深度卷积对于每个输入信道独立地执行空间卷积,而逐点卷积用于组合来自深度卷积的输出。
- 在深度可分卷积的TensorFlow实现中,在深度卷积(即空间卷积)中支持了atrous卷积。 如下图。
- 在这项工作中,我们将得到的卷积称为atrous可分卷积,并发现atrous可分离卷积显着降低了所提出模型的计算复杂度,同时保持了相似(或更好)的性能。
-
DeepLabv3 as encoder:
- DeepLabv3采用了atrous卷积来提取由任意分辨率的深度卷积神经网络计算的特征。
- 在这里,我们将
output stride表示为输入图像空间分辨率与最终输出分辨率的比率(在全局池化或完全连接层之前)。 - 对于图像分类的任务,最终特征图的空间分辨率通常比输入图像分辨率小32倍,因此输出stride=32.
- 对于语义分割的任务,可以采用输出stride=16(或8)通过去除最后一个(或两个)块中的步幅并相应地应用atrous卷积来进行更密集的特征提取(例如,我们分别对输出步幅= 8的最后两个块应用rate = 2和rate = 4)。
- 此外,DeepLabv3增强了Atrous空间金字塔池化模块,该模块通过应用具有不同速率的atrous卷积和图像级特征来探测多尺度的卷积特征。
We use the last feature map before logits in the original DeepLabv3 as the encoder output in our proposed encoder-decoder structure.- 在我们提出的encoder-decoder结构中,我们在原始DeepLabv3中进行登录之前使用最后一个特征映射作为encoder模块的输出。
-
Proposed decoder:
- DeepLabv3的编码器功能通常用输出stride=16计算,特征被双线性上采样16倍,这可以被认为是一个最初的decoder模块。但是,这个最初的decoder模块可能无法成功恢复对象分割细节。因此,我们提出了一个简单而有效的decoder模块,如图所示。
- 编码器特征首先进行双线性上采样4倍,然后与具有相同功能的网络主干中具有相同空间分辨率的低级特征连接起来。即上图中encoder和decoder的特征图相连接。
- 我们在低级特征上应用另一个1×1卷积来减少通道数,因为相应的低级特征通常包含大量通道(例如,256或512),这可能超过富编码特征的重要性(我们的模型中只有256个通道),使训练更加困难。
- 在连接之后,我们应用几个3×3的卷积来细化特征,然后进行另一个简单的双线性上采样4倍。

- 修改过的Xception结构如下图所示:

- 训练策略与deeplabv3相同。
-
我们首先将DeepLabv3特征图定义为**DeepLabv3计算的最后一个特征图(即包含ASPP特征,图像级特征等的特征)**和$[k×k; f]$作为内核大小为k×k和f滤波器的卷积运算。
-
当使用输出stride = 16时,基于ResNet-101的DeepLabv3 在训练和评估期间对logits进行双线性上采样16。 这种简单的双线性上采样可以被认为是一种简单的解码器设计,在PASCAL VOC2012上设置的性能达到77.21%并且比在训练期间不使用这种天真解码器好1.2%(即,下采样groundtruth 在训练中)。
-
为了改善这个原始的基线,我们提出的模型“DeepLabv3 +”在编码器输出的顶部添加了解码器模块,如上图,在解码器模块中,我们考虑三个不同设计选择的位置,即(1) 1×1卷积用于减少来自编码器模块的低级特征映射的通道,(2)用于获得更清晰分割结果的3×3卷积以及(3)应当使用什么编码器低级特征。
-
为了评估1×1卷积在解码器模块中的效果,我们采用[3×3;256]及来自ResNet-101网络主干的Conv2特征,即res2x残差块中的最后一个特征图。 如下图所示,将低级特征映射的通道从编码器模块减少到48或32导致更好的性能。 因此我们采用$[1×1;48]$减少通道。

- 然后,我们为解码器模块设计3×3卷积结构,并在下表中报告结果。我们发现在使用DeepLabv3特征图连接Conv2特征图之后,使用两个3×3卷积的256个滤波器比使用简单的一个或三个卷积更有效。
- 将过滤器的数量从256更改为128或将内核大小从3×3更改为1×1会降低性能。
- 由下表得出的结果,得出的decoder模块:
the concatenation of the DeepLabv3 feature map and the channel-reduced Conv2 feature map are refined by two [3 × 3, 256] operations.

- 为了在准确性和速度方面比较模型变体,下表报告了mIOU和Multiply-Adds。
- 在建议的DeepLabv3 +模型中使用ResNet-101作为网络主干。由于atrous卷积,我们能够在训练和评估过程中使用单一模型获得不同分辨率的特征。

-
**Baseline:**上表中的第一个大行块,表明在评估期间提取更密集的特征图(即,eval输出步幅= 8)并采用多尺度输入提高了性能。 此外,添加左右翻转输入会使计算复杂性增加一倍,而性能只会略微提高。
-
Adding decoder:上表中的第二个大行块,包含了添加的decoder模块。当使用eval输出stride = 16或8时,性能从77.21%提高到8.85%或78.51%到79.35%,代价是大约20B额外的计算开销。使用多刻度和左右翻转输入时,性能得到进一步提高。
-
Coarser feature maps:还试验了使用train输出stride=32(即,在训练期间根本没有任何atrous卷积)进行快速计算的情况。如上表中的第三行块所示。添加解码器带来2%的改进,而只需要74.20B的MultiplyAdds。然而,在我们采用train输出stride = 16和不同的eval输出步幅值的情况下,性能总是约1%至1.5%。 因此,我们更倾向于在训练或评估期间使用输出stride = 16或8,具体取决于复杂性预算。
- 采用Xception作为网络骨干。 进行了一些更改,如第5.2节所述。
- 下表为Xception作为网络主干的结果:

-
**Baseline:**首先在上表中的第一行块中不使用建议的decoder报告结果。示出了当训练输出stride = eval output stride = 16时,使用Xception作为网络主干比在使用ResNet-101的情况下将性能提高约2%。 通过使用平均输出stride = 8,在推理期间进行多尺度输入并添加左右翻转输入,也可以获得进一步的改进。
-
**Adding decoder:**如表中的第二行块所示。对于所有不同的推理策略,当使用平均输出stride = 16时,添加解码器会带来约0.8%的改进。 使用平均输出stride = 8时,改进变得更少。
-
Using depthwise separable convolution
-
Pretraining on COCO
-
Pretraining on JFT
- 模型“DeepLabv3 +”采用编码器解码器结构,其中DeepLabv3用于编码丰富的上下文信息,并且采用简单但有效的解码器模块来恢复对象边界。还可以应用atrous convolution以任意分辨率提取编码器特征,这取决于可用的计算资源。 我们还探索了Xception模型和atrous可分离卷积,使得所提出的模型更快更强。