
180917 There are some pool parallel issues in the code, with shared_list and .get() block. If I have time later I'll fix them.
The Ultimate NBA Downloader is a project that consists of multiple techniques which I have used for previous Python-based internet crawlers. It is a well-structured, minimally-adapted, fully packed and tested package that specifically constructed for a certain NBA related website.
With UND, you can deploy a daily NBA photo collector on your server, or just run it as a single task to collect NBA photos that have appeared on that website in chronological order. Indeed, you cannot acquire the specific picture that you want with this tool, but you can gradually develop your own NBA photo collection with it. Some time you can get some surprise from daily crawling, e.g. legacy photos for retired NBA stars, photoset or gallery concerning a specific topic, technologically great composed photography, etc. At least, after crawling enough photos, you can gather up a great few of photos of your preferred star player.
There might be some copyright related issue with this project, so it just obtains the visible pictures on webpages. Also you should comply with the terms of use of the specific website that you want to deal with. Any illegal or unauthorized usage of this tool is prohibited, and the related disputes on copyright infringement will be proceeded to the user.
This project is under GPL license. Please contact the owner for commercial usage.
It was a long winding dream for sports fans to acquire photos, pictures, videos and other digital collectibles with minimal effort. For me, there has remained a long-standing question that keeps on bothering me – how to collect photos for LeBron James?
The very first approach, which I had adopted in my middle school, is to use mouse. Right click, save as, confirm. That’s it. Obviously it’s slow and painful, but it’s really universal – you will get what you see, and you can choose with your own criterion. After that, I used tools like link parser to collect all the tag in a webpage, and download them with concurrent downloading software. Still, it’s not a great idea and I kept on wasting my precious adolescence on those meaningless actions.
Getting into collegial study, I have better skills such as scripting. From very primary VB to Python, Ruby or C#, I use different methods for different cases. After years of doing the same (or at least similar) things, I think it’s time to give it a conclusive wrap-up. Therefore, I tried to use most of the techniques that I have used before, both for exhibition and for commemoration.
The project expands as follows:
BR-py3.py - main
|-------- links_temp-------- get_article_links
|-------- get_picture_links
|-------- check_n_save_pictures
- The main function handles data file read/write, calls sub-modules and manage threading and multiprocessing.
- The links_temp module retrieves article links from website and parse it into different chunks containing required information.
- The get_picture_links module read from article links and gather the picture srcs from it.
- The check_n_save_pictures module check and download the pictures.
More will be described in my blog post.
-
Used lots of workflows that I have used before, improve the logic of them. e.g. bs4 to parse the webpage, requests and urllib to handle HTTP requests, regular expressions to extract strings, logging to output a unified log file, PIL to process pictures, csv read/write to serve as a database, sending log emails, etc.
-
threading on HTTP requests to significantly reduce the time without consuming too much computing resource.
-
multiprocessing on downloading pictures to save time.
-
other unmentioned (or intentionally missed) tricky inspirations ;-)
-
added first version. works fine with mine.
-
global variables are written at the header of main function.
- fixed links which exist but returns 404 :http://bleacherreport.com/articles/2749575-chris-paul-becomes-first-player-with-28-points-8-assists-and-7-steals-vs-spurs - at page 191 when it came to me
-
ensure you have installed Python3 and related dependencies.
-
for one-time usage, you should primarily change the variables in section [0. global variables definition]. a typical usage is:
BR_save_path = 'your path' from_page_number = 1 to_page_number = 360also, for the csv databases, you could refer to the template file provided.
-
for links_all.csv, the first time you run it, you need to add the article id of the article where you want to stop at.
-
for pics_all.csv, you do not need to add anything.
-
-
for periodical crawling, you can set a lower to_page_number and also lower processes amount.
-
run it manually or with crontab, at or other way you like.
Most options are hard-coded in the script, so if you want to use it differently, just refer to the detailed comments within. Enjoy your authentic photo collection!
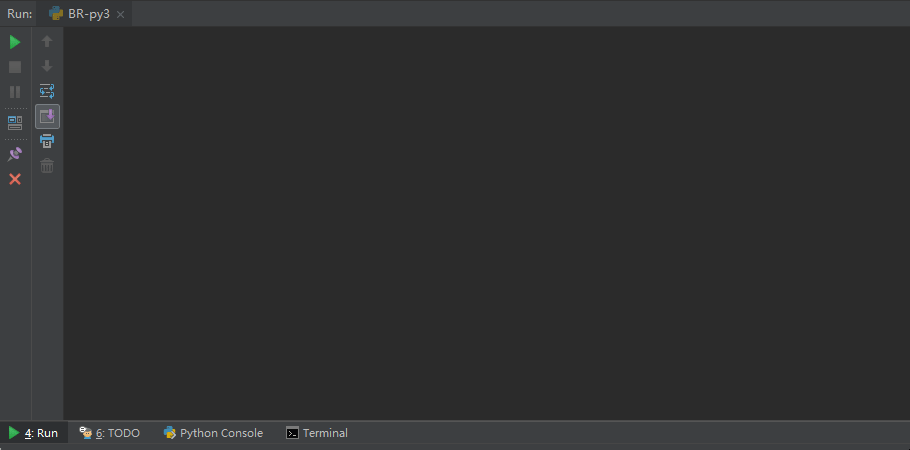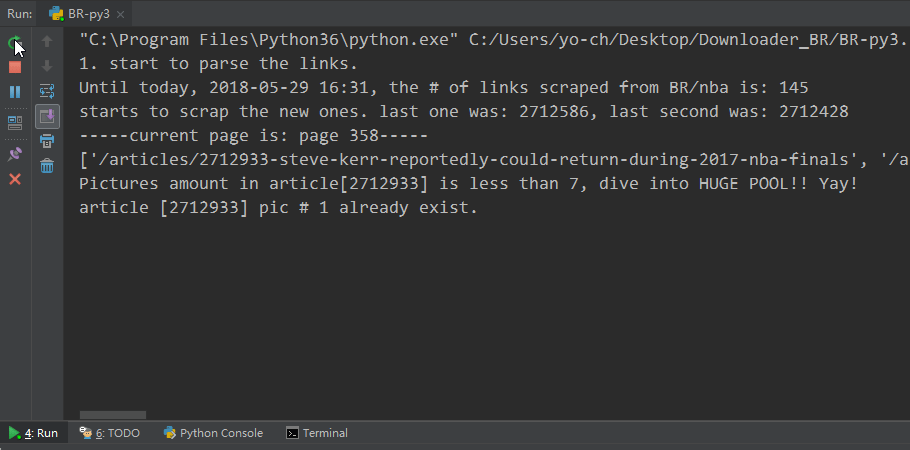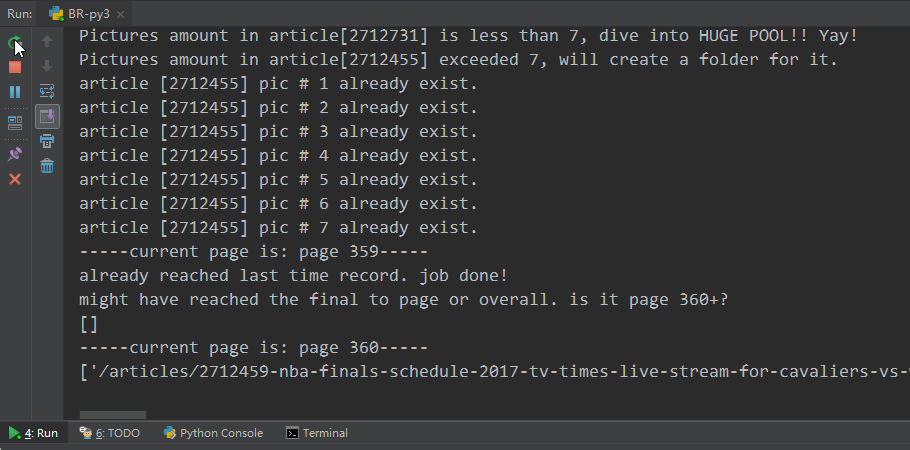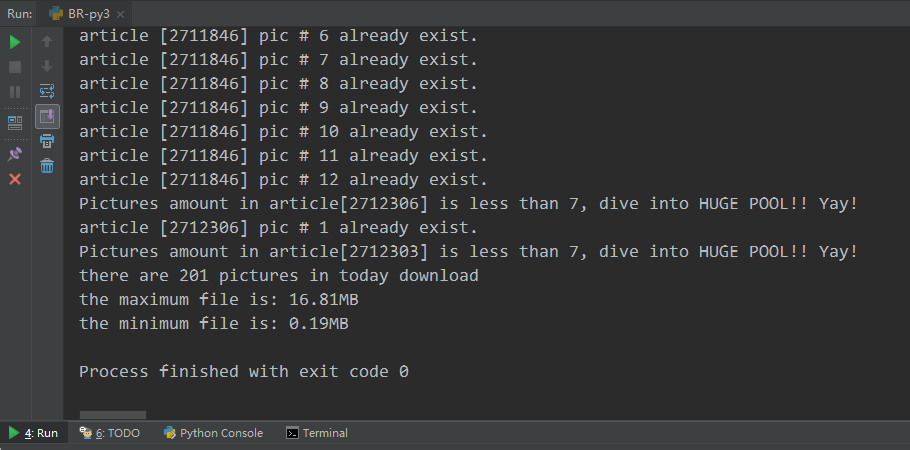
command-line appearance
folder appearance


tool | downloader | NBA | threading | multiprocessing | crawler