


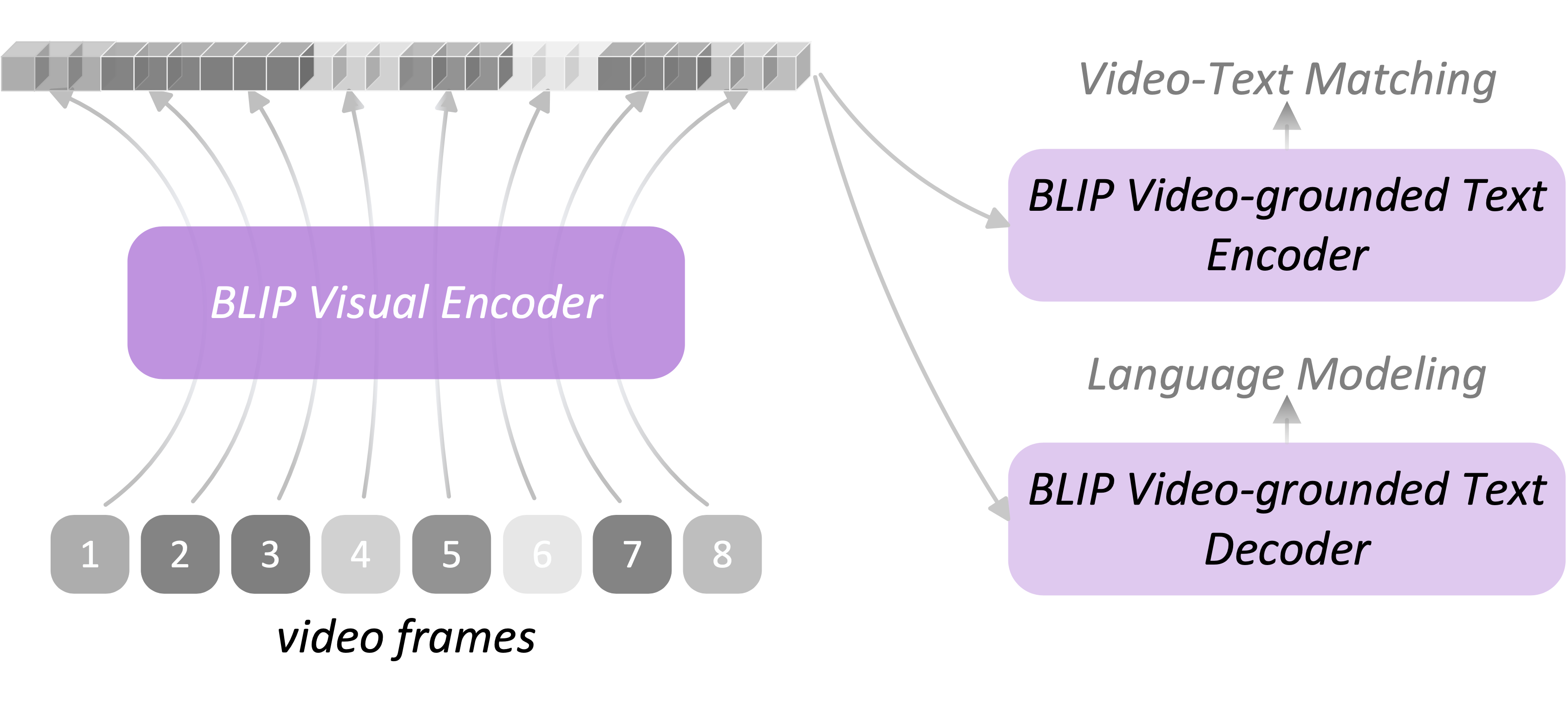
This is the PyTorch code of BLIP4video, a modified version of BLIP for the Video-to-Text Description (VTT) task at TRECVID 2022. Our submission ranks 1st in all official evaluation metrics including BLEU, METEOR, CIDER, SPICE, and STS, and achieves the best submission score of 60.2 on CIDEr, 67.2% higher than last year’s best result.

- BLIP captioner's video solution
- Self-critical reinforcement learning for video captioning (VinVL implementation)
- Text-video retrieval and matching for caption candidates scoring and re-ranking
- Set data root in configs/*.yaml accordingly.
- To train the finetuned BLIP4video model for the video captioning task, run:
bash scripts/train_video_caption.sh
If you find this code to be useful for your research, please consider citing.
@inproceedings{yue2022blip4video,
author = {Yue, Zihao and Liu, Yuqi and Zhang, Liang and Yao, Linli and Jin, Qin},
title = {RUCAIM3-Tencent at TRECVID 2022: Video to Text Description},
year = {2022},
booktitle = {Proceedings of TRECVID 2022},
organization = {NIST, USA},
url={https://www-nlpir.nist.gov/projects/tvpubs/tv22.papers/rucaim3-tencent.pdf}
}
The implementation of BLIP relies on resources from BLIP and Oscar. We thank the original authors for their open-sourcing.