This is the TensorFlow implementation of the paper "SEMANTIC MODELING OF TEXTUAL RELATIONSHIP IN CROSS-MODAL RETRIEVAL". https://arxiv.org/abs/1810.13151
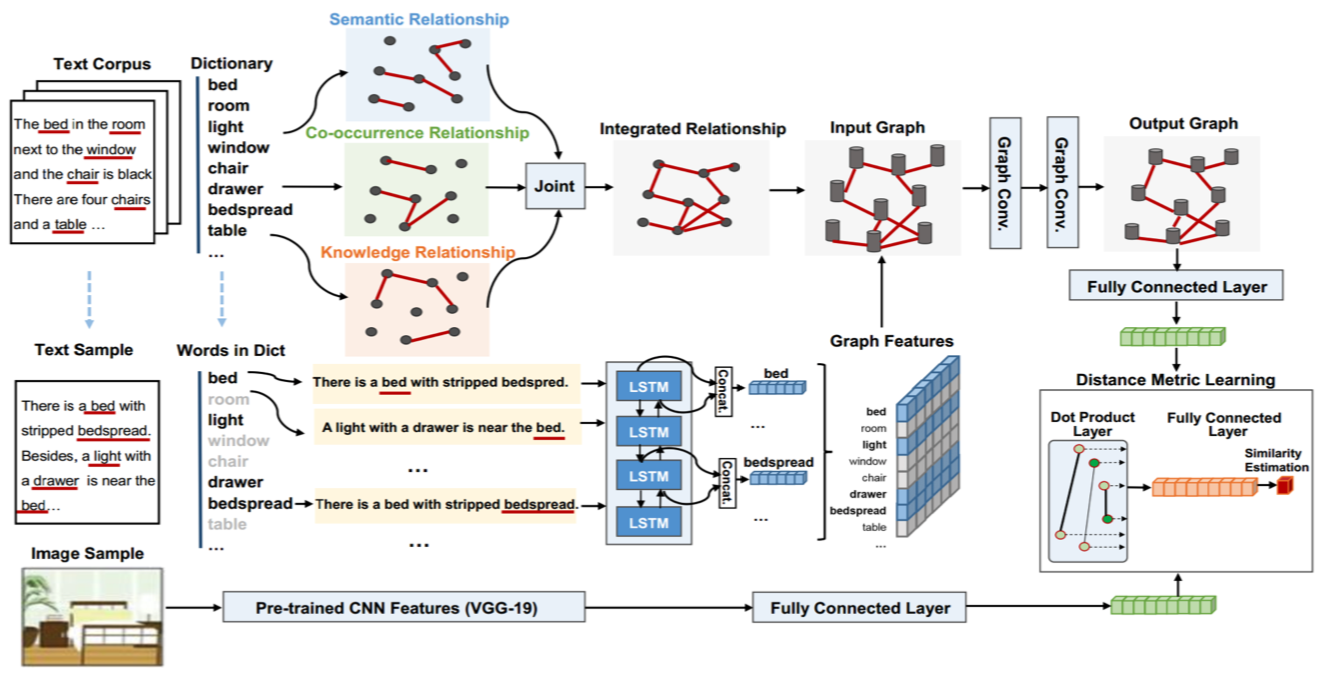
Feature representation of different modalities is the main focus of current cross-modal information retrieval research. Existing models typically project texts and images into the same embedding space. In this paper, we explore the multitudinous of textural relationships in text modeling. Specifically, texts are represented by a graph generated using various textural relationships including semantic relations, statistical co- occurrence, and predefined knowledge base. A joint neural model is proposed to learn feature representation individually in each modality. We use Graph Convolutional Network (GCN) to capture relation-aware representations of texts and Convolutional Neural Network (CNN) to learn image representations. Comprehensive experiments are conducted on two benchmark datasets. The results show that our model outperforms the state-of-the-art models significantly by 6.3% on the CMPlaces data and 3.4% on English Wikipedia, respectively.
Python requirements: numpy scipy scikit-learn tensorflow opencv-python
Download sckr_data.zip from the link below
https://drive.google.com/open?id=1N0k5SHtlHhAp_1M0WVBUl65tdzvS5m30
You may unzip it where you like. You will pass the path to the directory when you run the program.
To train the SCKR model, for example, run
cd main/cmplaces
python train.py --data_dir <path to dataset> --model sckr
for a full list of arguments, run python train.py --help
To test the SCKR model, for example, run
cd main/cmplaces
python test.py --data_dir <path to dataset> --model sckr --sess sess_name --ckpts 10,20,50
for a full list of arguments, run python test.py --help
@article{yu2018textual,
title={Textual Relationship Modeling for Cross-Modal Information Retrieval},
author={Yu, Jing and Yang, Chenghao and Qin, Zengchang and Yang, Zhuoqian and Hu, Yue and Liu, Yanbing},
journal={arXiv preprint arXiv:1810.13151},
year={2018}
}