- Legoland at Pardot
- @zacstewart
- zstewart@salesforce.com




Prasad Venkat, Arris Ray, Rusty Bailey
^ This talk isn't quite a tutorial, but it does contain code examples. It also won't go into mathematical underpinnings of any machine learning algorithms. Supervised vs. unsupervised. Regression vs. classification.
^ A single var linear regression to draw a line and make predictions. GrLivArea is a feature


^ Sale price vs. Above ground living area.
^ Sale price by neighborhood.
^ On strategy is to throw out examples with missing data. A downside is that you can never predict on new examples with missing data because the model doesn't know how to deal with it. Another is that you miss out on valuable examples if you have small data.
PoolQC: Pool quality
train_data['PoolQC'].fillna('None')^ Pretty easy. You can usually just fill in a single dummy value.
MasVnrType: Masonry veneer type MasVnrArea: Masonry veneer area in square feet
train_data['MasVnrArea'].fillna(0.0)GarageYrBlt: Year garage was built
train_data.loc[train_data['GarageYrBlt'].isnull(), 'GarageYrBlt'] = \
train_data.loc[train_data['GarageYrBlt'].isnull(), 'YearBuilt']^ More tricky. You have to think about what a reasonable fill-in would be. Impute by neighborhood (fill in with mean for neighborhood). Fill in with YearBuilt. Train regressor to predict GarageYrBlt and use its predictions for missing values.
model = Pipeline([
('features', FeatureUnion([
('GrLivArea', ColumnSelector(['GrLivArea'])),
# lots of other features...
('Neighborhood', Pipeline([
('extract', ColumnSelector(['Neighborhood'])),
('fill_na', FillNaTransformer('missing')),
('to_dict', ToDictTransformer()),
('label', DictVectorizer(sparse=False))
])
])),
('regressor', GradientBoostingRegressor())
])^ We use Pipeline and FeatureUnion sklearn constructs to design our model. ^ The last step is our regressor, and prior steps are all data transformations.
model = Pipeline([
('features', FeatureUnion([
## Continuous
continuous_feature('LotArea'),
continuous_feature('YearBuilt'),
continuous_feature('YearRemodAdd'),
continuous_feature('BsmtFinSF1'),
continuous_feature('BsmtFinSF2'),
continuous_feature('BsmtUnfSF'),
continuous_feature('TotalBsmtSF'),
continuous_feature('1stFlrSF'),
continuous_feature('2ndFlrSF'),
continuous_feature('LowQualFinSF'),
continuous_feature('GrLivArea'),
continuous_feature('BsmtFullBath'),
continuous_feature('FullBath'),
continuous_feature('HalfBath'),
continuous_feature('BedroomAbvGr'),
continuous_feature('KitchenAbvGr'),
continuous_feature('TotRmsAbvGrd'),
continuous_feature('Fireplaces'),
continuous_feature('GarageYrBlt'),
continuous_feature('GarageCars'),
continuous_feature('GarageArea'),
continuous_feature('LotFrontage'),
continuous_feature('MasVnrArea'),
continuous_feature('WoodDeckSF'),
continuous_feature('OpenPorchSF'),
continuous_feature('EnclosedPorch'),
continuous_feature('3SsnPorch'),
continuous_feature('ScreenPorch'),
continuous_feature('PoolArea'),
continuous_feature('MiscVal'),
## Categorical
factor_feature('MSSubClass'),
factor_feature('MSZoning'),
factor_feature('Street'),
factor_feature('Alley'),
factor_feature('LotShape'),
factor_feature('LandContour'),
factor_feature('Utilities'),
factor_feature('LotConfig'),
factor_feature('LandSlope'),
factor_feature('Neighborhood'),
factor_feature('Condition1'),
factor_feature('Condition2'),
factor_feature('BldgType'),
factor_feature('HouseStyle'),
factor_feature('OverallQual'),
factor_feature('OverallCond'),
factor_feature('RoofStyle'),
factor_feature('RoofMatl'),
factor_feature('Exterior1st'),
factor_feature('Exterior2nd'),
factor_feature('MasVnrType'),
factor_feature('ExterQual'),
factor_feature('ExterCond'),
factor_feature('Foundation'),
factor_feature('BsmtQual'),
factor_feature('BsmtCond'),
factor_feature('BsmtExposure'),
factor_feature('BsmtFinType1'),
factor_feature('Heating'),
factor_feature('HeatingQC'),
factor_feature('CentralAir'),
factor_feature('Electrical'),
factor_feature('KitchenQual'),
factor_feature('Functional'),
factor_feature('FireplaceQu'),
factor_feature('GarageType'),
factor_feature('GarageFinish'),
factor_feature('GarageQual'),
factor_feature('GarageCond'),
factor_feature('PavedDrive'),
factor_feature('PoolQC'),
factor_feature('Fence'),
factor_feature('MiscFeature'),
factor_feature('SaleType'),
factor_feature('SaleCondition'),
('YearAndMonth', YearAndMonthTransformer())
])),
('regressor', GradientBoostingRegressor())
])^ Cross validation is how you evaluate your model before putting it into production against unlabeled data. ^ A simple form of CV can be to just split the dataset 40/60 or 30/70 and hold out one portion for testing.

^ The dataset for this problem is small, so we don't want to miss the opportunity to train on all available examples. ^ K-folding allows us to train and test on the whole set by running K experiments.
np.random.seed(22)
kfold = KFold(5)
for (train_idx, cv_idx) in kfold.split(train_data):
train = train_data.iloc[train_idx]
validate = train_data.iloc[cv_idx]
train_X = train
train_y = train['SalePrice']
validate_X = validate
validate_y = validate['SalePrice']
model.fit(train_X, y=train_y)
predictions = model.predict(validate_X)
rmse_log = np.sqrt(mean_squared_error(
np.log1p(validate_y), np.log1p(predictions)))
print(rmse_log)^ We fix the PRNG seed to ensure we get the same experiement each time, because sklearn will. ^ Our evaluation metric is the same one that the leaderboard uses. ^ Square root of squared differences (error) between log of predicted price and log of actual price.
model.fit(all_train_set, y=all_train_set['SalePrice'])
predictions = model.predict(all_test_set)^ Train on the entire train set (instead of a portion of it like before). ^ Generate our prediction, which will be an array of house prices, log transformed.
assert pd.isna(predictions).sum() == 0, 'There are some NaN predictions!'^ Make sure we didn't produce any NaN predictions. ^ This would indicate we haven't sufficiently filled in missing data. ^ Sometimes a feature may have missing values in the test set, but not in the training set.

^ The leaderboard is already comparing log predictions to log truth. ^ Prevents expensive houses from effecting the score disproportionately from cheap houses.
![inline fit][log_sale_price_distro]

^ This is one sample distribution that I'd be happy to see skewed very far to the left. https://mathspig.wordpress.com/category/topics/normal-distribution/
![inline fit][lotarea_distro]
![inline fit][lotarea_distro_boxcox]
- Ridge
- Lasso
- ElasticNet
- GradientBoostingRegressor
- AdaBoostRegressor
- BaggingRegressor
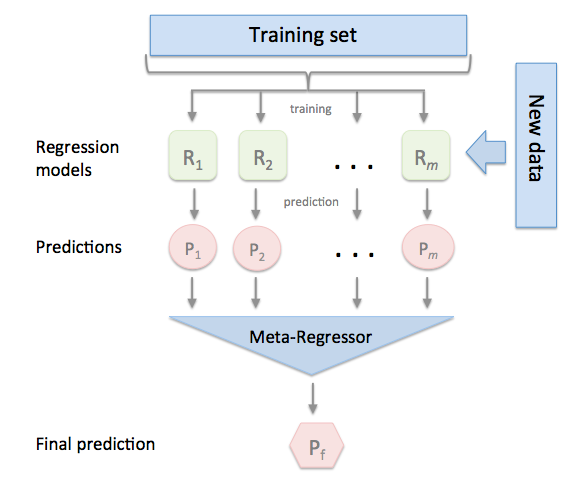
- Polynomial features (exponents of existing features)
- Interactions (products of existing features)
- Cluster categorical features
^ Cluster: eg. "type" of neighborhood by clustering neighborhoods