To solve a Rubik's Cube environment with the model prescribed in the paper, Imagination-Augmented Agents for Deep Reinforcement Learning, [Weber et al]. The I2A model generates observation predictions from an learned environment model. I2A's learn to leverage multiple rollouts of these predicitions to construct a better policy and value network for the agent.
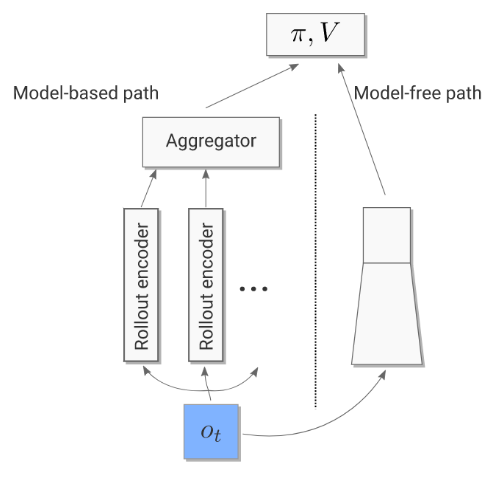
The Value and Policy Function leverage information from a model-free and a model-based path. The model-free path simply processed the current observation from the environment. The model-based path utilizes the observation to generate multiple rollout encoding which are aggregated and fed to the rest of the network. The rollout encodings are generated by the Imagination Core which uses a learned Environment Model to create these rollouts. These encodings can contain information about solving certain subproblems within the environment that may not yeild any reward but is beneficial for getting reward later on.
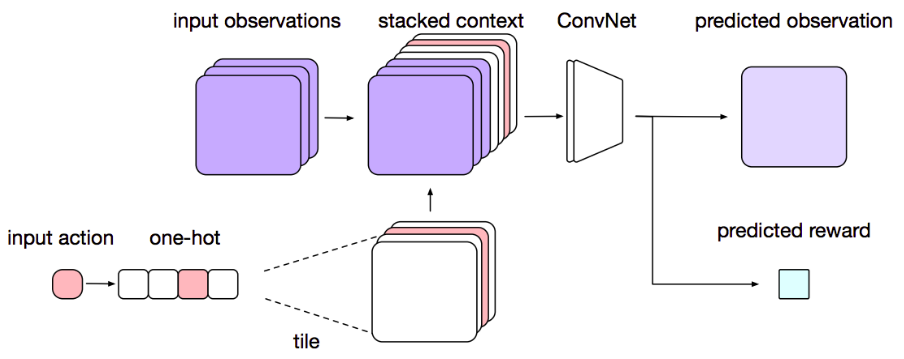
The Environment Model is a simple Convolutional Network that takes in the current observation of the state and action and outputs the predicted next state and reward that the real environment would produce. The input action is converted to a one-hot vector which then converted further into a one-hot channel representation and stacked alongside the other channels of the input observation. The accuracy of the model does improve the overall performance of the I2A model, but it was shown in the paper that even with a bad model, the full architecture is able to disregard the inaccuracies and still improve attain better performance when compared to a totally model-free counterpart.
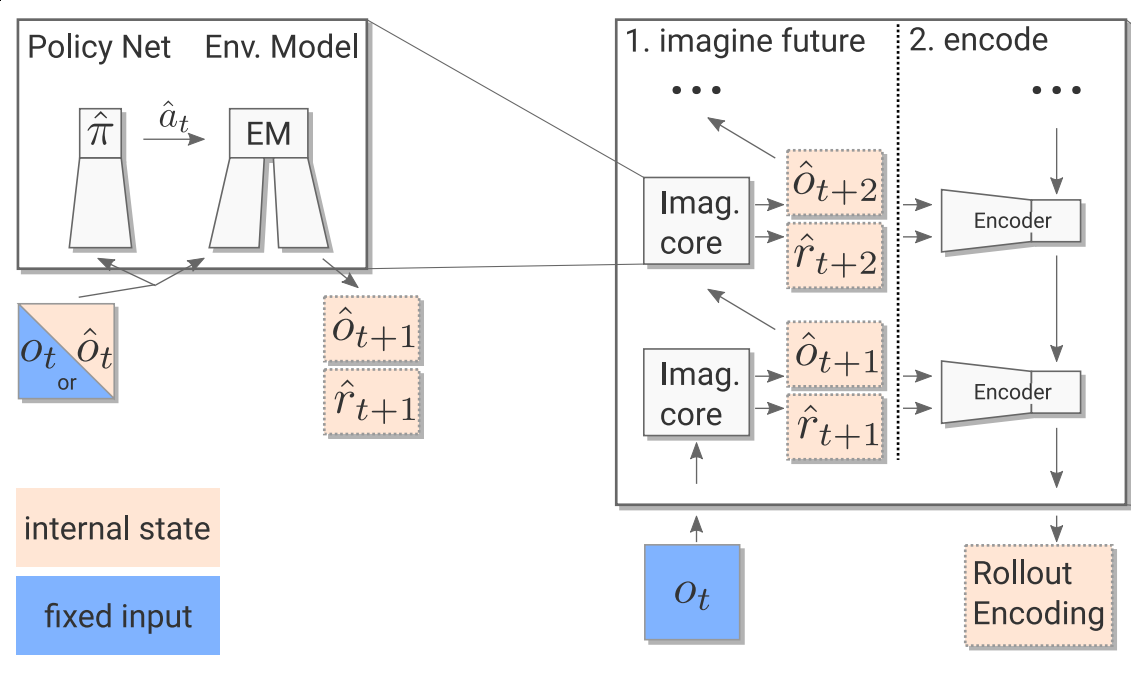
The Imagination Core is responsible for generating the trajectories and encoding them. We utilize a rollout policy that makes the decision of choosing what actions to take given either the real observation state or any imagined state generated by the Environment Model. The choice of rollout policy is up for experimentation and the details of it are described in the next section. The rollout policy is used to generate n rollouts. Each rollout is then passed into a convolutional Encoder and LSTM network which outputs the encoding for the rollout.
It turns out that for the environments the paper used, distilling the full I2A network into a smaller and entirely model-free network showed the best results for being the rollout policy. This is because the policy becomes goal-oriented and thus produces rollouts that are searching for the goal.
(Note that this is NOT the agent solving the environment)
The Rubik's Cube environment is actually a really simple environment that with only 12 possible actions (not counting mid-turns). If we include the ability to change orientation of the cube, we get a total of 18 actions. The 3x3x3 Rubik's Cube has 43,252,003,274,489,856,000 permutations making it equivalent to a very large maze. Out these permutations, there is only a single state that yeilds reward, the solved state. Theoretically, regardless of how scrambled the cube is, it can also be solved in 26 moves or less.
In our setup, the environment is setup as a gym environment using the API that
OpenAI's Gym Framework provides. The reward is made to be sparse and only provides
a reward of +1 on the solved state and provides a reward of +0 for all other states.
While the environment supports any n-order cube, testing will only be done of the
cube-x2-v0 and cube-x3-v0 environments. We will also explore how effective
the policy can become when allowing the agent to control the orientation of the
environment.
usage: main.py [-h] [--a2c] [--a2c-pd-test] [--em] [--vae] [--i2a]
[--iters ITERS] [--env ENV] [--workers WORKERS]
[--nsteps NSTEPS] [--scramble SCRAMBLE] [--maxsteps MAXSTEPS]
[--noise NOISE] [--adaptive] [--spectrum] [--easy]
[--no-orient-scramble] [--a2c-arch A2C_ARCH]
[--a2c-load A2C_LOAD] [--lr LR] [--pg-coeff PG_COEFF]
[--vf-coeff VF_COEFF] [--ent-coeff ENT_COEFF]
[--em-arch EM_ARCH] [--em-load EM_LOAD] [--em-loss EM_LOSS]
[--obs-coeff OBS_COEFF] [--rew-coeff REW_COEFF]
[--vae-arch VAE_ARCH] [--vae-load VAE_LOAD]
[--kl-coeff KL_COEFF] [--i2a-arch I2A_ARCH]
[--i2a-load I2A_LOAD] [--exp-root EXP_ROOT] [--exppath]
[--tag TAG] [--log-interval LOG_INTERVAL] [--cpu CPU]
[--no-override] [--arch-help]
optional arguments:
-h, --help show this help message and exit
--a2c Train the Actor-Critic Agent (default: False)
--a2c-pd-test Test the Actor-Critic Params on a single env and show
policy logits (default: False)
--em Train the Environment Model (default: False)
--vae Train the Variational AutoEncoder Model (default:
False)
--i2a Train the Imagination Augmented Agent (default: False)
--iters ITERS Number of training iterations (default: 50000.0)
--env ENV Environment ID (default: cube-x3-v0)
--workers WORKERS Set the number of workers (default: 16)
--nsteps NSTEPS Number of environment steps per training iteration per
worker (default: 40)
--scramble SCRAMBLE Set the max scramble size. format: size (or)
initial:target:episodes (default: 1)
--maxsteps MAXSTEPS Set the max step size. format: size (or)
initial:target:episodes (default: 1)
--noise NOISE Set the noise for observations from the environment
(default: 0.0)
--adaptive Turn on the adaptive curriculum (default: False)
--spectrum Setup up a spectrum of environments with different
difficulties (default: False)
--easy Make the environment extremely easy; No orientation
change, only R scrabmle (default: False)
--no-orient-scramble Lets the environment scramble orientation as well
(default: False)
--a2c-arch A2C_ARCH Specify the policy architecture, [Look at --arch-help]
(default: c2d+:16:3:1_h:4096:2048_pi_vf)
--a2c-load A2C_LOAD Load Path for the Actor-Critic Weights (default: None)
--lr LR Specify the learning rate to use (default: 0.0007)
--pg-coeff PG_COEFF Specify the Policy Gradient Loss Coefficient (default:
1.0)
--vf-coeff VF_COEFF Specify the Value Function Loss Coefficient (default:
0.5)
--ent-coeff ENT_COEFF
Specify the Entropy Coefficient (default: 0.05)
--em-arch EM_ARCH Specify the environment model architecture [Look at
--arch-help] (default: c2d:32:3:1_c2d:64:3:1_c2d:128:3
:1_h:4096:2048:1024_c2dT:128:4:1_c2dT:6:3:3)
--em-load EM_LOAD Load Path for the Environment-Model Weights (default:
None)
--em-loss EM_LOSS Specify the loss function for training the Env Model
[mse,ent] (default: mse)
--obs-coeff OBS_COEFF
Specify the Predicted Observation Loss Coefficient
(default: 1.0)
--rew-coeff REW_COEFF
Specify the Predicted Reward Loss Coefficient
(default: 1.0)
--vae-arch VAE_ARCH Specify the VAE model architecture [Look at --arch-
help] (default: c2d:32:3:1_c2d:64:3:1_c2d:128:3:1_z:32
:1024_c2dT:128:4:1_c2dT:6:3:3)
--vae-load VAE_LOAD Load Path for the Variational AutoEncoder Weights
(default: None)
--kl-coeff KL_COEFF Specify the KL-Divergence Coefficient (default: 0.5)
--i2a-arch I2A_ARCH Specify the I2A policy architecture [Look at --arch-
help] (default: NULL)
--i2a-load I2A_LOAD Load Path for the Imagination-Augmented Agents Weights
(default: None)
--exp-root EXP_ROOT Set the root path for all experiments (default:
./experiments/)
--exppath Return the experiment folder under the specified
arguments (default: False)
--tag TAG Tag the current experiemnt (default: )
--log-interval LOG_INTERVAL
Set the logging interval (default: 1000.0)
--cpu CPU Set the number of cpu cores available (default: 16)
--no-override Prevent loading arguments to override default settings
(default: False)
--arch-help Show the help dialogue for constructing model
architectures (default: False)
The miscellaneous scripts are found in misc. They contain useful
scripts which their usage will be documented here.
By default the main.py program saves experiments to the ./experiments
directory. The necessary files will be automatically be created in the local
filesystem. But lets say you wanted to save these experiments to a
Google Cloud Bucket. This script will mount the GCP Bucket
into the ./experiments folder using gcsfuse. More details for
Google's Cloud Storage FUSE can be found here.
Just a script to unmount the Google Cloud FUSE mentioned earlier.
Mentored by Kyoungmanlee, Game Contents AI Team Member at Netmarble.
This was supported by Deep Learning Camp Jeju 2018 which was organized by TensorFlow Korea User Group.