LWMA difficulty algorithm #3
Comments
|
I'm on boarding :) |
|
Here is the Python implementation of LWMA algo in Bitcoin Gold: def BTG_LWMA(height, timestamp, target):
# T=<target solvetime>
T = 600
# height -1 = most recently solved block number
# target = 1/difficulty/2^x where x is leading zeros in coin's max_target, I believe
# Recommended N:
N = 45 # int(45*(600/T)^0.3))
# To get a more accurate solvetime to within +/- ~0.2%, use an adjustment factor.
# This technique has been shown to be accurate in 4 coins.
# In a formula:
# [edit by zawy: since he's using target method, adjust should be 0.998. This was my mistake. ]
# adjust = 0.9989^(500/N)
# k = (N+1)/2 * adjust * T
k = 13632
sumTarget = 0
t = 0
j = 0
# Loop through N most recent blocks. "< height", not "<=".
# height-1 = most recently solved rblock
for i in range(height - N, height):
solvetime = timestamp[i] - timestamp[i-1]
j += 1
t += solvetime * j
sumTarget += target[i]
# Keep t reasonable in case strange solvetimes occurred.
if t < N * k // 3:
t = N * k // 3
next_target = t * sumTarget // k // N // N
return next_target@zawy12 , please note that your original pseudocode has a mistake at the last line: If I understand it correctly, it should be:
Given Apparently, there's a superfluous factor |
|
Thanks for the correction. |
Addet Zawy difficulty algorithm in version 2 (newest one: see zawy12/difficulty-algorithms#3 )
This PR adds in a difficulty adjustment algorithm. Motivation and Context We need to adjust the difficulty per block. This PR adds the LWMA algorithm as per zawy12/difficulty-algorithms#3
This PR adds in a difficulty adjustment algorithm. Motivation and Context We need to adjust the difficulty per block. This PR adds the LWMA algorithm as per zawy12/difficulty-algorithms#3
Merge pull request #971 We need to adjust the difficulty per block. This PR adds the LWMA algorithm as per zawy12/difficulty-algorithms#3
|
Can you please make a version for the BTC clones in version 0.8.6? I try but is hard the timestam stuff. |
|
what is setting to use for 5m blocks ? |
Is the blockchain already set at 5m and you want to adjust the numbers? |
|
In contradiction to my previous statements that say 50% of N depends on block time, I'm now saying 200 to 600 is a good value. One reason is because this many sample has only 1/SQRT(N) error in sampling which is 7% to 4% error. The main reason I changed is that I thought for many years that Monero was bad for every coin that tried it's DA because the average time was a full day (too slow). But later I realized most of the extreme oscillation problems were because monero modifies it's simple moving average to have a lag in using solvetimes (it doesn't use the most recent solvetimes). Simple moving averages can also cause oscillations under on-off mining, but not as bad as what monero forks were seeing before changing the difficulty algorithm. So instead of N=60 or 120 for 5-minute blocks, I'm saying 200 to 600 for all block times. |
i think N 576 is ok , but there another qustion if find that is ok for low times. but when N 576 and T 300 default is so if we do T*N = 172800 then 172800 / 20 = 8640 then convert it to hours 8640 / 60 / 60 = 2.4 Hours , more than default :/ and from that all will more than base BTC setting , so what keep ot maybe need calculate by another way for N 576 and T 300 ? |
|
Your N * T is 2 days which means if there is a significant price change in a few hours it could attract a lot of temporary mining to profit at expense of constant miners. In contradiction to my previous reply, you might want a balance between speed of response due to price changes and wanting stability if hashrate is constant. I'd like an N where expected daily stability in difficulty under constant hashrate is equal to the expected daily price change. This approach gives 2 equations that need solving to determine N and T. For example, if you want to target 1 day as the relevant time period in which you want to respond to price changes, then k = 3600 * 24. If F is measured from price history data to be 3% in that k time period (F = 0.03 std dev per day), then N = 1,111 from 1st equation & T = 78 seconds from 2nd equation. Using the equations conversely, you are using T=300 and N=576 which is like saying you have a good balance between stability and price changes if price typically changes 4.2% in 2 days. If it doesn't change that much, you could argue for a larger N, being aware that this will cause 2^(-15) * 1152 = 3.5% error in difficulty at times when nBit is near the "cusp" of changing (this requires understanding nBit's compression scheme to explain). It's 1.75% error at times with N = 576. |
|
I should mention that ideally your limits on timestamps (future time and past time) would be the highest accuracy your miners can be expected to maintain, provided it's larger than your "typically longest" propagation delays. Let's say blocks and validation of them can easily propagate under normal network conditions in 2 seconds. Then if they can keep clocks with 2.1 second accuracy, technically they should, and they should reject blocks who's timestamps are more than 4.2+2 seconds in the past or 4.2 seconds in the future. But there can be abnormal network delays which which cause blocks to be rejected under this rule, so you have to let PoW override the rule to repair the "breaking of synchony" that occurred. The rule could be "ignore blocks that break with rule for 300 seconds, then let PoW decide which is the most-work chain." This seems a lot of work for nothing but it's the proper way according to Lamport's 1978 Clock's paper. The only benefits I've noticed is that it makes selfish mining impossible because they have to assign a timestamp before they know when to release the block and it fixes a complaint people have had with "real time targeting". I described it in detail in a recent "issue" that included selfish mining. |
|
so what setting you can recomend if not go to "real time" mining for prevent any possible issue , about hashrate i not really scare as there dual pow ( not multi pow ) 2 checks - one Nbits = 2 algos. Yespower + argon2id with salt over sha512 with tricky RAM floating. |
|
People were using N=60 with T=60 or 120, so 5% of N * T for FTL was 180 seconds, so it needed to be a lot less than 2 hours. Your FTL = 2.4 hours is OK, but there's no reason not to make it a lot shorter. Every miner should be able to keep their clock within 5 minutes of UTC, so you could do that. A couple of coins used FTL = 15 seconds and said they didn't have any problems. I just think 2 hours is way too long and serves no purpose. I never saw a legitimate explanation for it in BTC. I would use 1 minute just to make miners keep an accurate clock. Keep in mind peer time should be removed in accordance with Lamport's 1982 Byzantine paper (and earlier research) as I repeated in the LWMA code and described in my "Timestamp Attacks" issue. But if peer time is kept, then the limit for "revert to local time" (miner's UTC time that he knows is correct) should be reduced form 70 minutes to 1/2 of FTL. I haven't understood what you're doing with 2 PoWs. Each "hash" is actually a sequence of 2 hashes? Please respond in issue #79 you created instead of this thread. |
Bellcoin uses Yespower and LWMA. How will you use two mining algorithms? https://github.com/bellcoin-org/bellcoin/tree/master/src. I don't believe the PoW mining algorithms you've selected are ASIC-resistant. Sorry Grammarly * |
not exist any asic resistance algos for all algos possible create asic , all depend how much money can be spendet to developt asic. Two proofs of work (POWs) are utilized for each block validation process. Initially, the block undergoes verification using the Yespower algorithm. Subsequently, the same block is subjected to two rounds of SHA512 as salt, followed by two rounds of Argon2id. The block is deemed valid only if it passes both proof of work validations simultaneously. For the Yespower proof of work, the function GetYespowerPowHash() computes the hash. This function serializes the block data and utilizes the Yespower algorithm for hash computation. For the Argon2id proof of work, the function GetArgon2idPoWHash() is employed. This function serializes the block data and then performs two rounds of SHA512 hashing with a salt . Following this, it conducts two rounds of Argon2id hashing. The resulting hash from the second round is returned. To verify block headers, the function CheckBlockHeader() is utilized. It evaluates both proofs of work for the block. If either proof of work fails, the block is considered invalid. For lightweight Simplified Payment Verification (SPV) wallets, only one of the proof of works can be utilized for verification. |
X16-17-+ were asic res unless that was incorrect in 2019 |
|
project is paned non premine , there no mining software / exist pools , algos only for POW , heders sha256 native (LTC like for speed up sync ). Target most be valid at the same time for 2 POW's - this is not multi POW it is dual POW and this is more experemental solution , as it dual pow and 1 target is valid , it make possible at future even remove one of algo at BIP with no keep any "trash code". |
Interesting. Why not just trust one pow? What’s is the benefit and does it mitigate anything? |
is one pow will have any problems or potential CVE we can drop it as target will be still valid and remove it clearly from code for not keep "forking code" , yespower is good for CPU and make prevent GPU and asic mining at exist software. this is more of an experiment + it was very difficult to find the best algorithm setting to maintain algorithms with the same speed difference - hashrate. for prevent situation - mining 1 algo to find targets and then try push it to 2 algo for speed up. |
Since it’s post incident, just change the algo at block # and do a wallet update. You will be doing wallet releases periodically for the first few years. Save your self the headache. (Technically a fork but it’s the same because you have to change the code to remove) |
|
and argon2id i use not native, there is 2 memory locks , what is problematic at GPU or FPGA , first for 1 round lock memory 4mb , then for next round you need again call memory 32mb "lock > free > lock" or simple think about it why we use at BTC 2 round of sha256 why not one ? the same . target - block most have the same or more lead 000... hash will be diferent ,but they will give valid targets at 2 algos for the same data ( "target colision" ) |
CN coins: The last test of your fork is to make sure your new difficulties when you sync from 0 are matching the old difficulties when running the pre-fork code. See this note.
FWIW, it's possible to do the LWMA without looping over N blocks, using only the first and last difficulties (or targets) and their timestamps. In terms of difficulty, I believe it's:
I discovered a security weakness on 5/16/2019 due to my past FTL recommendations (which prevent bad timestamps from lowering difficulty). This weakness aka exploit does not seem to apply to Monero and Cryptonote coins that use node time instead of network time. If your coin uses network time instead of node local time, lowering FTL < about 125% of the "revert to node time" rule (70 minutes in BCH, ZEC, & BTC) will allow a 33% Sybil attack on your nodes, so the revert rule must be ~ FTL/2 instead of 70 minutes. If your coin uses network time without a revert rule (a bad design), it is subject to this attack under all conditions See: zcash/zcash#4021
People like reading the history of this algorithm.
Comparing algorithms on live coins: Difficulty Watch
Send me a link to open daemon or full API to be included.
LWMA for Bitcoin & Zcash Clones
See LWMA code for BTC/Zcash clones in the comments below. Known BTC Clones using LWMA: are BTC Gold, BTC Candy, Ignition, Pigeon, Zelcash, Zencash, BitcoinZ, Xchange, Microbitcoin.
Testnet Checking
Emai me a link to your code and then send me 200 testnet timestamps and difficulties (CSV height, timestamp, difficulty). To fully test it, you can send out-of-sequence timestamps to testnet by changing the clock on your node that sends your miner the block templates. There's a Perl script in my github code that you can use to simulate hash attacks on a single-computer testnet. Here's example code for getting the CSV timestamps/difficulty data to send me:
Discord
There is a discord channel for devs using this algorithm. You must have a coin and history as a dev on that coin to join. Please email me at zawy@yahoo.com to get an invite.
Donations
Thanks to Sumo, Masari, Karbo, Electroneum, Lethean, and XChange.
38skLKHjPrPQWF9Vu7F8vdcBMYrpTg5vfM or your coin if it's on TO or cryptopia.
LWMA Description
This sets difficulty by estimating current hashrate by the most recent difficulties and solvetimes. It divides the average difficulty by the Linearly Weighted Moving Average (LWMA) of the solvetimes. This gives it more weight to the more recent solvetimes. It is designed for small coin protection against timestamp manipulation and hash attacks. The basic equation is:
next_difficulty = average(Difficulties) * target_solvetime / LWMA(solvetimes)LWMA-2/3/4 are now not recommended because I could not show they were better than LWMA-1.
LWMA-1
Use this if you do not have NiceHash etc problems.
See LWMA-4 below for more aggressive rules to help prevent NiceHash delays,
The following is an idea that could be inserted right before "return next_D;
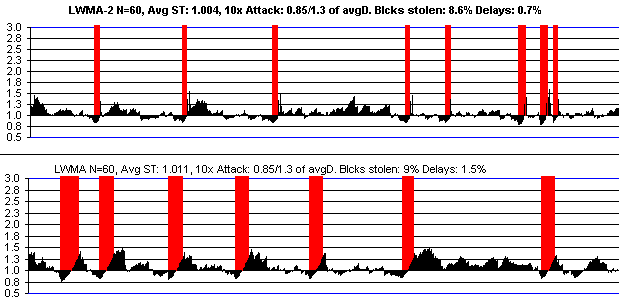
This is LWMA-2 verses LWMA if there is a 10x attack. There's not any difference for smaller attacks. See further below for LWMA compared to other algos.
Credits:
Known coins using it
The names here do not imply endorsement or success or even that they've forked to implement it yet. This is mainly for my reference to check on them later.
Alloy, Balkan, Wownero, Bitcoin Candy, Bitcoin Gold, BitcoiNote, BiteCode, BitCedi, BBScoin, Bitsum, BitcoinZ(?) Brazuk, DigitalNote, Dosh, Dynasty(?), Electronero, Elya, Graft, Haven, IPBC, Ignition, Incognito, Iridium, Intense, Italo, Loki, Karbo, MktCoin, MoneroV, Myztic, MarketCash, Masari, Niobio, NYcoin, Ombre, Parsi, Plura, Qwerty, Redwind?, Saronite, Solace, Stellite, Turtle, UltraNote, Vertical, Zelcash, Zencash. Recent inquiries: Tyche, Dragonglass, TestCoin, Shield 3.0. [update: and many more]
Importance of the averaging window size, N
The size of of an algorithm's "averaging" window of N blocks is more important than the particular algorithm. Stability comes at a loss in speed of response by making N larger, and vice versa. Being biased towards low N is good because speed is proportional to 1/N while stability is proportional to SQRT(N). In other words, it's easier to get speed from low N than it is to get stability from high N. It appears as if the the top 20 large coins can use an N up to 10x higher (a full day's averaging window) to get a smooth difficulty with no obvious ill-effects. But it's very risky if a coin does not have at least 20% of the dollar reward per hour as the biggest coin for a given POW. Small coins using a large N can look nice and smooth for a month and then go into oscillations from a big miner and end up with 3-day delays between blocks, having to rent hash power to get unstuck. By tracking hashrate more closely, smaller N is more fair to your dedicated miners who are important to marketing. Correctly estimating current hashrate to get the correct block solvetime is the only goal of a difficulty algorithm. This includes the challenge of dealing with bad timestamps. An N too small disastrously attracts on-off mining by varying too much and doesn't track hashrate very well. Large N attracts "transient" miners by not tracking price fast enough and by not penalizing big miners who jump on and off, leaving your dedicated miners with a higher difficulty. This discourages dedicated miners, which causes the difficulty to drop in the next cycle when the big miner jumps on again, leading to worsening oscillations.
Masari forked to implement this on December 3, 2017 and has been performing outstandingly.
Iridium forked to implement this on January 26, 2018 and reports success. They forked again on March 19, 2018 for other reasons and tweaked it.
IPBC forked to implement it March 2, 2018.
Stellite implemented it March 9, 2018 to stop bad oscillations.
Karbowanec and QwertyCoin appear to be about to use it.
Comparison to other algorithms:
The competing algorithms are LWMA, EMA (exponential moving average), and Digishield. I'll also include SMA (simple moving average) for comparison. This is is the process go through to determine which is best.
First, I set the algorithms' "N" parameter so that they all give the same speed of response to an increase in hash rate (red bars). To give Digishield a fair chance, I removed the 6-block MTP delay. I had to lower its N value from 17 to 13 blocks to make it as fast as the others. I could have raised the other algo's N value instead, but I wanted a faster response than Digishield normally gives (based on watching hash attacks on Zcash and Hush). Also based on those attacks and attacks on other coins, I make my "test attack" below 3x the basline hashrate (red bars) and last for 30 blocks.
Then I simulate real hash attacks starting when difficulty accidentally drops 15% below baseline and end when difficulty is 30% above baseline. I used 3x attacks, but I get the same results for a wide range of attacks. The only clear advantage LWMA and EMA have over Digishield is fewer delays after attacks. The combination of the delay and "blocks stolen" metrics closely follows the result given by a root-mean-square of the error between where difficulty is and where it should be (based on the hash rate). LWMA wins on that metric also for a wide range of hash attack profiles.
I also consider their stability during constant hash rate.
Here is my spreadsheet for testing algorithms I've spent 9 months devising algorithms, learning from others, and running simulations in it.
Here's Hush with Zcash's Digishield compared to Masari with LWMA. Hush was 10x the market capitalization of Masari when these were done (so it should have been more stable). The beginning of Masari was after it forked to LWMA and attackers were still trying to see if they could profit.
The text was updated successfully, but these errors were encountered: