This project looks at grocery retail transaction data and applies a Word2Vec model to generate embeddings for individual products.
Live demo can be accessed here
brave_ZXIXnMRwxq.mp4
For our model, we will evaluate baskets of items purchased together. We will use each basket of product IDs to train a Word2Vec model.
### Datasets
products = pd.read_csv("../datalake/products.csv")
orders = pd.read_csv("../datalake/order_products__train.csv")
### Take in order x product combinations
### Return products ranked by number of orders they appear in
product_ranking = (
orders.groupby("product_id")
.agg(ct=("order_id", "count"))
.reset_index()
.sort_values(["ct"], ascending=False)
.assign(rank=lambda d: d.reset_index().index + 1)
.drop(["ct"], axis=1)
)
### Encode product IDs to their ranking value
prod_encoder = ProductEncoder(product_ranking, products, num_products=NUM_PRODUCTS)
### Aggregate orders and apply encoding logic
baskets = (
orders.groupby("order_id")["product_id"]
.apply(list)
.reset_index()["product_id"]
.apply(lambda ls: [prod_encoder.product_to_idx[x] for x in ls])
)
### Prod2Vec model
model = Word2Vec(sentences=baskets, vector_size=64, negative=20, seed=42)Next, we can use the resulting embeddings to identify substitutable products by calculating the cosine similarity between the embeddings of each item. Products with higher cosine similarity scores are likely to be substitutable for the items in the basket.
We can then compare the cosine similarity between the embeddings of apples and other fruits that are likely to be substitutable for apples, such as pears or peaches.
### Find top 5 similar products using cosine similarity
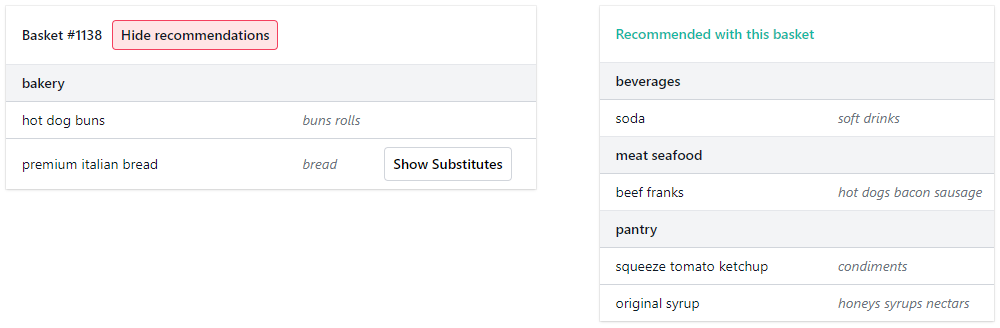
similar = model.wv.most_similar(item_idx, topn=5)We can also sum up the embeddings in each basket and use these aggregated embedding values to look for similar customer baskets. With this information we can recommend complementary items that other customers purchased.
### Calculate basket embeddings
basket_embeddings = [list(np.sum(model.wv[p], axis=0)) for p in baskets]
basket = basket_embeddings[0]
### Pull list of similar baskets
similarity_threshold = 0.95
idx_similar = np.array(
cosine_similarity([basket], basket_embeddings) > similarity_threshold
).reshape(-1)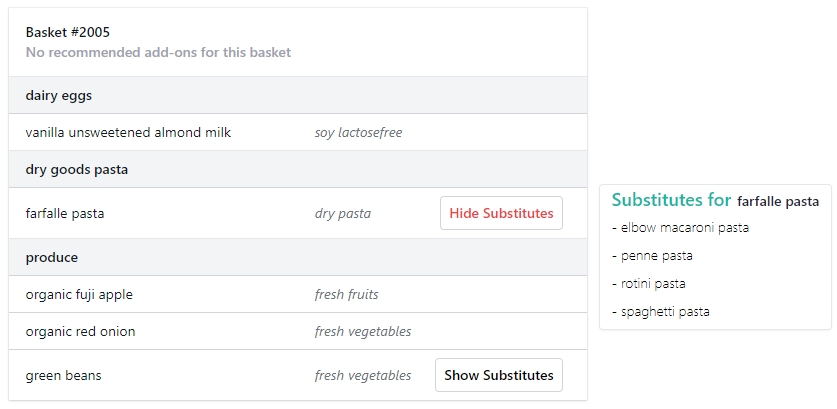
- Using "Kaggle Market Basket Analysis" dataset, which can be found here
- Unzip and make sure the
products.csvandorders.csvfiles are in thedatalakefolder