想通过python快速的爬取高校博士招生网站,进而整理一份网站名单,以方便查阅各大高校博士招生信息。
整理好的博客在这里: 全国各大985/211博士招生网站
常见搜索引擎搜索格式[1]:
- 百度搜索引擎: http://www.baidu.com.cn/s?wd=’ 关键词’&pn=‘分页’。 wd是搜索的关键词,pn是分页的页面,由于百度搜索每页的结果是十个(最上面的可能是广告推广,不是搜索结果),所以pn=0是第一页,第二页是pn=10… 例如https://www.baidu.com/s?wd=python&pn=0,得到的是关于python的第一页搜索结果。
- 必应搜索引擎: http://global.bing.com/search?q=‘关键词’
- 搜狗搜索引擎 https://www.sogou.com/web?query=‘关键词’
- 360搜索引擎 https://www.so.com/s?q=‘关键词’
这里,我采用必应搜索引擎。比如,我想搜索北京大学的博士招生信息,对应搜索指令为http://global.bing.com/search?q=北京大学+博士招生
所以现在需要解决的第一个问题就是如何利用python获取搜索引擎的搜索结果。
参考了如下文章后[2],修改了自己的代码,实现了如下功能:自定义搜索关键字,获取搜索结果第一页结果,输出结果网页的标题及其对应URL到文件中,等待后续处理文件。
代码如下:
import re
import requests
from lxml.html import etree
import time
# 重定向输出结果到./data/original_data.txt
import sys
sys.stdout = open('./data/original_data.txt', 'w', encoding='utf-8')
def get_bing_url(keywords):
keywords = keywords.strip('\n')
bing_url = re.sub(r'^', 'https://cn.bing.com/search?q=', keywords)
bing_url = re.sub(r'\s', '+', bing_url)
return bing_url
if __name__ == '__main__':
# base_keys是读取基础的搜索关键字,这里是“+博士招生+2023”, 你可以自定义其他搜索关键字,加号表示空格,即搜索结果中需要包含的关键字
base_keys = open('./data/base.txt', 'r', encoding='utf-8')
for key in base_keys:
# added_keys是读取附加的搜索关键字,比如“北京大学”
added_keys = open('./data/add.txt', 'r', encoding='utf-8') # add.txt contains the name of universities
for t_key in added_keys:
new_key = t_key.strip()+key.strip()
print(t_key)
bing_url = get_bing_url(new_key)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'cookie': 'DUP=Q=sBQdXP4Rfrv4P4CTmxe4lQ2&T=415111783&A=2&IG=31B594EB8C9D4B1DB9BDA58C6CFD6F39; MUID=196418ED32D66077102115A736D66479; SRCHD=AF=NOFORM; SRCHUID=V=2&GUID=DDFFA87D3A894019942913899F5EC316&dmnchg=1; ENSEARCH=BENVER=1; _HPVN=CS=eyJQbiI6eyJDbiI6MiwiU3QiOjAsIlFzIjowLCJQcm9kIjoiUCJ9LCJTYyI6eyJDbiI6MiwiU3QiOjAsIlFzIjowLCJQcm9kIjoiSCJ9LCJReiI6eyJDbiI6MiwiU3QiOjAsIlFzIjowLCJQcm9kIjoiVCJ9LCJBcCI6dHJ1ZSwiTXV0ZSI6dHJ1ZSwiTGFkIjoiMjAyMC0wMy0xNlQwMDowMDowMFoiLCJJb3RkIjowLCJEZnQiOm51bGwsIk12cyI6MCwiRmx0IjowLCJJbXAiOjd9; ABDEF=V=13&ABDV=11&MRNB=1614238717214&MRB=0; _RwBf=mtu=0&g=0&cid=&o=2&p=&c=&t=0&s=0001-01-01T00:00:00.0000000+00:00&ts=2021-02-25T07:47:40.5285039+00:00&e=; MUIDB=196418ED32D66077102115A736D66479; SerpPWA=reg=1; SRCHUSR=DOB=20190509&T=1614253842000&TPC=1614238646000; _SS=SID=375CD2D8DA85697D0DA0DD31DBAB689D; _EDGE_S=SID=375CD2D8DA85697D0DA0DD31DBAB689D&mkt=zh-cn; _FP=hta=on; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1; dsc=order=ShopOrderDefault; ipv6=hit=1614260171835&t=4; SRCHHPGUSR=CW=993&CH=919&DPR=1&UTC=480&WTS=63749850642&HV=1614256571&BRW=HTP&BRH=M&DM=0'
}
for i in range(1, 2): # 通过for in来翻页
if i == 1:
url = bing_url
else:
url = bing_url + '&qs=ds&first=' + str((i * 10) - 1) + '&FORM=PERE'
content = requests.get(url=url, timeout=5, headers=headers)
# 获取content中网页的url
tree = etree.HTML(content.text)
li = tree.xpath('//ol[@id="b_results"]//li[@class="b_algo"]')[0] # [0] query the first result
try:
h3 = li.xpath('//h2/a')
for h in h3:
result_url = h.attrib['href'] # 获取网页的url
text = h.text # 获取网页的标题
if ('招生简章' in text or '研究生院' in text or '研究生招生' in text):
print(f'{text} {result_url}') # 写到文件中(因为最开始重定向了输出结果到./data/original_data.txt)
print('=======================')
except Exception:
print('error')最终得到原始URL文件,结果如下图所示:
经过上一步骤后,得到了搜索引擎检索到的最可能包含博士招生网页的url,现在就需要对original_data文件进行处理。这里采用最笨的方法,手动筛选,直到找到想要的URL为止,这样省去了一个学校一个学校检索的步骤,相对省事了。(如果有大佬直到这一步怎么直接筛选得到招生网页,请联系我,感激不尽!)
经过处理后,得到了如下图所示内容:
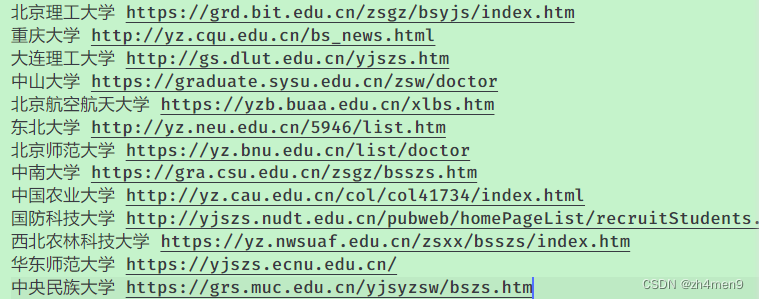
为了方便自己和大家使用,转换成Markdown,然后发布在博客上,可以直接点击学校名字就能访问招生主页了。
Markdown超链接格式为:[](),所以可以通过python很方便的直接处理URL得到想要的格式,代码如下:
# process url to Markdown formate —— [infomation](url)
output_file_path = './data/url.md'
output_file = open(output_file_path, 'w', encoding='utf-8')
# read url from ./data/phd_url.txt
with open('./data/phd_url.txt', 'r', encoding='utf-8') as f:
while True:
url_list = f.readline()
if not url_list: # 表明读取到文件末尾
break
url_list = url_list.strip()# 去掉末尾的换行符
urls = url_list.split(' ')
if (len(urls)==1): # 表明没有对应url
output_file.write(urls[0]+'(待更新)')
output_file.write('\n')
elif (len(urls)==2):
output_file.write('['+urls[0]+']('+urls[1]+')')
output_file.write('\n')
else:
print('error: url format error')整理好的博客在这里: 全国各大985/211博士招生网站
整理好的文档和python文件我开源在了自己的GitHub上:AutoPhd
[2] 如何扩展关键词,以及使用python多线程爬取bing搜索结果
main.py为主文件,进行爬取操作
url_process.py为处理url文件,将爬取到的url转换成markdown格式
data文件夹下为爬取到的数据、处理后的数据和最终的markdown文件
清华大学 北京大学 厦门大学 中国科学技术大学 南京大学 复旦大学 天津大学 浙江大学 西安交通大学 东南大学 上海交通大学 山东大学 中国人民大学 吉林大学 电子科技大学 四川大学 华南理工大学 兰州大学 西北工业大学 同济大学 哈尔滨工业大学 南开大学 华中科技大学 武汉大学 中国海洋大学 湖南大学 北京理工大学 重庆大学 大连理工大学 中山大学 北京航空航天大学 东北大学 北京师范大学 中南大学 中国农业大学 国防科技大学 西北农林科技大学 华东师范大学 中央民族大学
郑州大学 云南大学 新疆大学 北京工业大学 北京化工大学 北京中医药大学 中央财经大学 北京邮电大学 对外经济贸易大学 中国政法大学 北京外国语大学 北京体育大学(待更新) 北京交通大学 北京科技大学 北京林业大学 中国传媒大学 中央音乐学院 华北电力大学 中国地质大学(北京) 中国地质大学(武汉) 中国矿业大学(北京) 中国矿业大学 中国石油大学(北京) 中国石油大学(华东) 上海财经大学 上海外国语大学 东华大学 上海大学 华东理工大学 海军军医大学(第二军医大学) 暨南大学 华南师范大学 河海大学 南京师范大学 南京航空航天大学 南京理工大学 南京农业大学 中国药科大学 苏州大学 江南大学 合肥工业大学 安徽大学 南昌大学 福州大学 华中农业大学 华中师范大学 中南财经政法大学 武汉理工大学 天津医科大学 河北工业大学 湖南师范大学 西南大学 西南财经大学 西南交通大学 四川农业大学 陕西师范大学 西安电子科技大学 空军军医大学(第四军医大学) 西北大学 长安大学 太原理工大学 大连海事大学 辽宁大学 东北师范大学 延边大学 哈尔滨工程大学 东北农业大学 东北林业大学 海南大学 广西大学 贵州大学 内蒙古大学 石河子大学 宁夏大学 青海大学 西藏大学(待更新)