在很多高级语言里都有Map这个数据结构,在如java的hashmap、python的dict以及golang里面的map,那么map究竟是什么呢,原理又是如何呢。
Map其实我们在使用中就是简单的KV类型的数据存储结构,即我们根据key来获取唯一对应的value。那么各种语言中都是如何做到的呢。以Golang为例,进行简单的解释与总结。
让我们来思考计算机支持的简单数据类型,数组,计算机原生支持,就是一段连续的内存片段,假设每个元素长度10,那么10个元素就对应100的长度。 我们根据偏移量就可以很轻易的取出各个元素。 但是如果要随机获取元素呢?效率很低。 如果要保证唯一插入呢?效率很低。原因就是在于数组要完全遍历才能确定唯一性。
于是聪明的人开始了进一步加工。将key进行一次hash,并将key落入数组指定的位置。这样就解决了遍历的问题。知道初始位置+偏移量就可以将元素唯一的取出,不需要遍历。又带来了另一个问题,当两个key的hash值落入同一个数组位置如何解决。
- 水平扩展: 因为既然利用了数组,那就继续利用数组。当出现两个key落入相同的数组位置,将后来的key按照当前位置加上一个magicNum,去取下一个位置。直到有一个位置可以将这个key存进去。 搜索的时候一样,先按照hash对应位置搜索,再加上magicNum继续搜索。 但是有了新的问题,数组的长度是有限的,因为数组长度有限,就限制了我们的map存储量。 可以扩张数组,但是这样带来rehash,复制拷贝问题。
- 纵向扩展: 既然数组中会出现两个key相同hash位置的冲突,那么就在数组位置建一个链表,而不是真正存储数据项。 当出现冲突的时候无限扩展链表的长度即可。内存有多大,链表长度就有多大。舞台足够大,map的容量不会有限制了。这个方案看似完美。
其实刚刚所讲纵向扩展就是hashmap,hashmap是map的一种最简单实现方式,map的实现方式有很多如hashmap、treemap、hashtable、linkedhashmap。因此要明白hashmap与map之间的关系。
刚刚最后的纵向扩展,我们看似解决了高效查找与存储容量的问题。可以高效的根据Key快速获取对应的Value。但实际上呢?让我们分析一下,以查找步骤来看
- 新建一个map,假设hash数组长度为10
- 存储一个kv
- hash(key) = 5
- 遍历位置为5的链表 其实我们发现第一步寻找hash(key)=5的操作相当于将遍历操作简化为1/10(假设hash值分布均匀),但是后续遍历链表操作性能很差。 Cpu比内存快很多,因为链表中元素内存并不是存在一起的,所以要频繁进行内存读写,cpu要一直等待内存。 对于一个语言内置数据结构,这是我们不能容忍的。
我们知道cpu是最快的,cpu读数据经过了寄存器、L1、L2、L3、内存、硬盘。 为了满足速度最快的cpu,数据层都在做优化,有一个很重要的优化就是空间相关性数据的预读取局部性原理。说简单点就是: 你要0x123的数据,系统会缓存0x100 - 0x164的数据,这样在访问0x126的时候就不需要访问到最下层了,可能在L层就被cache住了。 这样内存友好型数据结构最直接的就是内存了。 于是可以把刚刚的链表再加工一步,链表的每一项不再是单个的数据元素kv,而是多个数据元素组合在一起的一个数组。比如保存4个元素,那么就是 k v k v k v k v。 这样每次拿就会拿回4个元素来进行对比,不需要每次都读取内存。 效率更高了一步。
刚才我们把kvkvkvkv这样存储在一起,每次读取只读取一次可以获取4个元素长度的数据回来进行比较,但是如果我们将kkkkvvvv这样存储,我们每次可以获取回8个k,即kkkkkkkk回来,因为我们在比较时其实不需要v,它是多余的信息。 这样我们将k和v分开存储。 极限压榨计算机。
###精益求精 我们在对比key的时候,需要把key一个个取出来再做对比。而且假设key是字符串类型,其实对比字符串也是很低效的。 我们可以对元素再进行一次hash,这样在每个链表元素头部记录此元素内部数据的第二次hash值,之后寻找的时候先判断此链表元素头部的数组是否在对应的hash位置是否为0即可,如果为0直接进入下一个链表元素,不为0再进行对比查找。又可以节省很多时间。
我们首先对Map的Key进行一次Hash,根据hash值计算此Key落在哪个桶(即数组的index)。然后将此数组对应的链表第一项取出,继续判断链表内hash值对应的数组位是否为0,如果为0则代表此链表项内不包含此key。如果不为0则有可能存在,需要进行遍历查找。
外层分桶的Hash值肯定不能和链表元素头部的Hash值相同,否则就失去了意义,但计算两个Hash值又会消耗性能,因此在Golang中采用计算一次Hash值,取Hash值的高N位来决定链表元素头部的Hash值,取Hash值的低N位来决定最开始数组的分桶值。 取最低位和最高位的方式可以高效的利用二进制与运算来决定结果值。
尽管我们从通用型和效率上考虑了Map的设计,使用链表纵向扩展,使用链表内聚合多个子kv元素来提高性能。但实际上远不止如此简单,尤其是考虑聚合元素提高性能时有很多小细节去主意,例如每个链表元素内的KV个数限制以及与垃圾回收综合考虑时指针的处理等等。
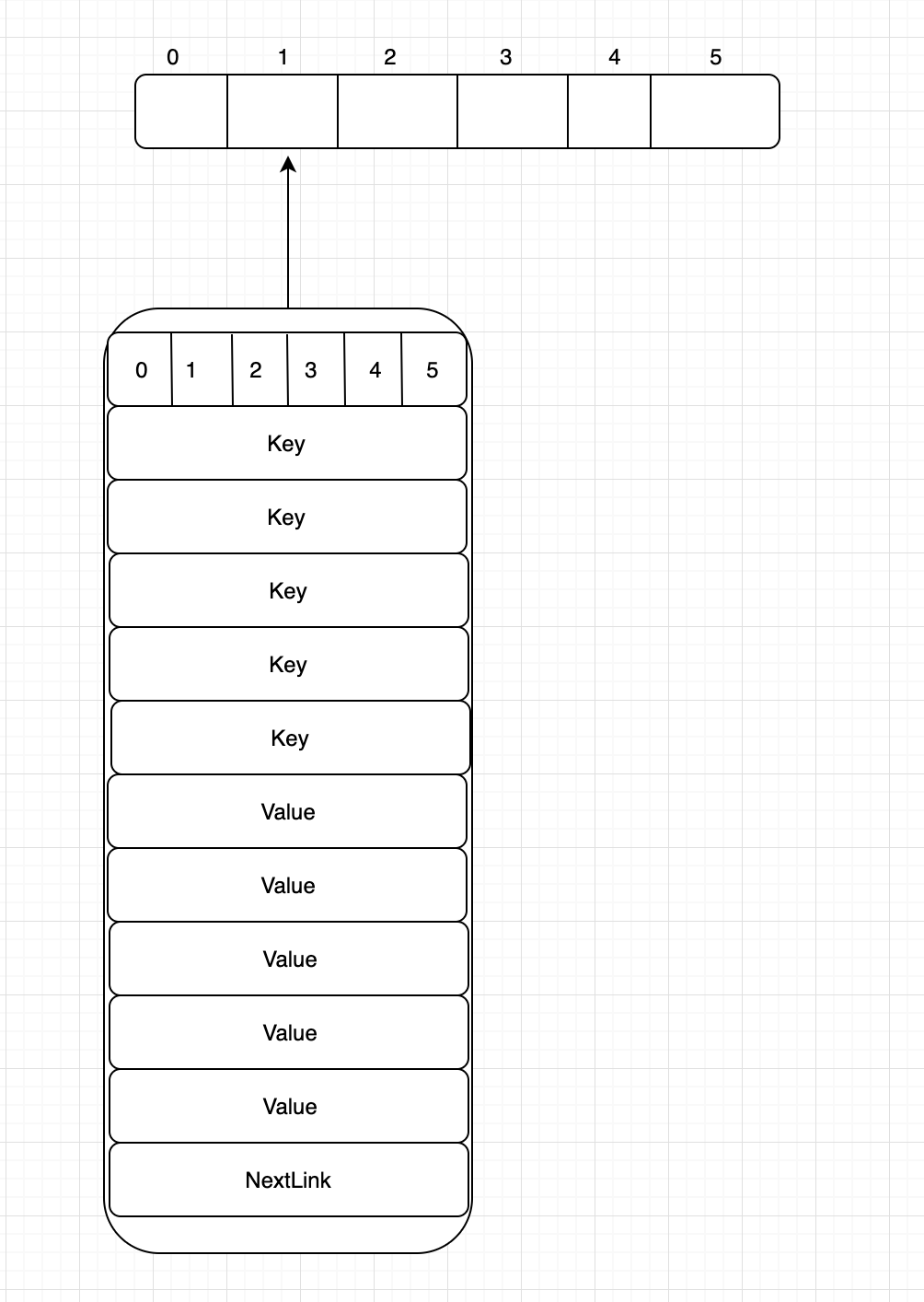
我们刚刚明白了Golang中Map的基本原理,但是伴随着Map的使用,中间又会出现什么样的问题呢。例如在初期为了不占用过大的内存资源,我们将桶设为8个,但是当存入上千个KV时,平均每个桶就要125个KV元素,即使均匀的分布,每个链表元素包含8个KV,每个桶也要有1000/8/8=16个长度链表,每次查找都要遍历16个桶,很低效。
其实还有一种极端案例,5个桶,1000个元素都在一个桶内,那就有125个链表长度。 很可怕。
于是就有了负载因子这个指标,用于监控这个Map的健康状况(负载因子请自行🔍)。当出现扩容需要时,首先第一步就是扩大桶的数量,例如之前取最低3位,那现在取最低的4位,即*2的方式来扩容。 同时对map进行一次标记rehashing=true,之后的每次请求,都会将对应的原hash桶元素进行rehash。这样采用惰性,多次,少量的方式进行rehash,既不会出现耗时过长的阻塞,也不会占用过多资源,实现平稳的过渡。 为了防止某些冷区桶无法被访问到,按照上面的策略也就无法被rehash,因此又添加了一个rehash策略,设置一个rehashidx数字,每次rehash不止要rehash自身,也要处理rehashidx这个桶,然后rehashidx++,这样就会在短时间内将所有桶都rehash,而且有一个很易见的rehash结束条件即rehashidx == len(桶)。
通过从最开始的数组一步步的演化过程,我们知道了Golang中Map数据结构的基本实现原理以及扩容过程。但内部仍有很多细节需要去满满挖掘。 但是作为一个语言内置的数据结构,高效性与易用性是必须考虑的,因此从其实现过程中可以看到很多符合计算机思维的考虑。