#Sparrow ###A toy-like programming language
##目录
Sparrow语言是一门通用型的脚本语言,除了有完善的控制流、基础数据类型、函数,还支持引用其它模块、类、闭包等功能。该语言是出于作者兴趣而诞生的,它只是对编译原理基础知识的一些实践,并不具备实用价值,对于想自制编程语言玩玩的朋友或许稍有帮助。
实现这个项目主要借鉴了两本书。第一本,《两周自制脚本语言》,Sparrow语言前期受它的影响很大,我词法分析器和语法分析器都采用了该作者的实现方法,区别于传统的递归下降实现,这本书的作者分别使用了正则匹配和构造库的方式来实现,我觉得十分新颖。第二本,《编程语言实现模式》,正如书名所言,书中给出了很多实用的方法,这本书里还有一句话“大多数语言应用在架构上都是类似的,创造新的语言其实并不需要深厚的理论知识做铺垫”,从我的过程来看确实如此。在看两本书前我花了一段时间来补编译原理的基础知识,因为两本书对理论的知识的介绍都十分实用性,并不易于理解。
- Linux(Ubuntu 14.04)
- G++ >=4.9
下载项目后并进入项目根目录后,执行
mkdir build && cd build
cmake ../src && make
编译完之后解释器在当前目录的vm目录中,名为main,拷贝至根目录的demo文件夹或testFiles文件夹下就可以试运行语言了
./main *.spr
G++编译器必须4.9版本或以上
Sparrow的文法是LL(1)类型的,下文将用EBNF描述它。在所有的终结符中,IDENTIFIER表示id,所有的id由字母或下划线开头,其它位置可以是字母、数字或下划线;NULL表示空;INT表示整型数;FLOAT表示浮点型数,数字串中如果带有“.”则会被解析为浮点型;STRING表示字符串型,语言中的字符串必须由双引号括起来;OP表示运算符;EOL表示换行符
param ::= <IDENTIFIER>;
params ::= ( param { "," param } ) | <NULL>;
param_list ::= "(" params ")";
elements ::= expr { "," expr };
primary ::= ("lamb" param_list block)
| ( ("[" [elements] "]" ) | ("(" expr ")" ) | <INT> | <FLOAT> |<IDENTIFIER> | <STRING> ) { postfix };
factory ::= ("-" primary ) | primary;
expr ::= factor { <OP> factor };
block ::= "{" [statement] {(";" | <EOL>) [statement]} "}";
def ::= "def" <IDENTIFIER> param_list block;
args ::= (expr {"," expr}) | <NULL>;
postfix ::= ("." "new" "(" args ")") | ( "." <IDENTIFIER> | "(" args ")" ) | ( "[" expr "]" );
simple ::= expr;
use ::= "use" <IDENTIFIER> "=" <IDENTIFIER>;
statement ::= ("if" condition block { elif } ["else" block])
| ("while" condition block)
| ("return" expr)
| simple;
elif ::= "elif" condition block;
condition ::= expr | and_logic | or_logic;
and_logic ::= "and" "(" condition "," condition ")";
or_logic ::= "or" "(" condition "," condition ")";
member ::= def | simple;
class_body ::= "{" [member] {(";" | <EOL>) [member]} "}";
def_class ::= "class" IDENTIFIER ["extends" <IDENTIFIER>] class_body;
program ::= [def_class | def | use | statement ] (";" | <EOL>);语言一共定义了18个关键字,它们分别是
- 用于导入和引用其它模块的:require, as, use
- 用于程序控制流以及逻辑操作符的:while, if, elif, else , and, or
- 用于函数定义的:def, lamb, return, new;
- 用于类相关的:class, extends, super, self;
- 用于程序表示表示空值的:nil.
//if、elif、else组成选择控制流
//根据文法,elif和else必须接在 } 后面,不能空行
if <谓语> {
...
} elif <谓语> {
...
} else {
...
}
//while循环控制流
while <谓语>{
...
}
Sparrow语言提供两种方式创建函数,一种是在全局环境声明定义函数,以def关键字开始,后接函数名以及用括号括起来的参数列表;另外用户还可以在局部环境创建匿名函数,使用lamb关键字,后接用括号括起来的参数列表。通过该方式,语言执行创建后将返回一个函数对象,用户可以把该对象赋予某个id。当函数有返回值,或者需要运行到某处退出时,可以使用return语句。
//全局环境创建函数
def <函数名> (<参数>) {
...
}
//在一个函数的局部环境中创建函数
def create_lamb() {
...
//创建匿名函数并赋予一个id
var = lamb (...) {
...
}
//把函数当做变量返回
return var
}
在Sparrow中,源程序的域访问是在运行时做检查的,当访问一个对象中不存在的成员时,语言会报错,但如果对一个对象中不存在的成员赋值,语言会把它添加进该对象的作用域中。这符合许多脚本语言的灵活性,每个对象即使是从一个类实例化出来,它们也可能后期的扩展而具备不同的方法、特性。
下面了创建一个类的示例,由class关键字开始,后接类名,然后定义类的成员和变量。在类声明中,变量要么有初始值,要么作为nil值等待初始化。每个类都需要定义一个init的初始化方法,语言在进行类的实例化时会自动调用该方法。
//定义一个类
class <类名> {
//定义一个类成员
aMember = 10
//定义一个待初始化的成员
bMember = nil
//定义初始化方法,根据语言规则,该方法必须定义,否则报错
def init (...) {
...
}
}
下面展示了类继承的示例,用户在子类类名后面加上extends关键字以及继承所用到的父类名就可以实现继承的语义。在子类方法中,如果需要用到父类的同名方法,前面必须加上super关键字。
//继承
class <类名> extends <父类名> {
//初始化方法中需要调用父类的初始化,但凡引用到父类的且重名的成员或函数
//都要使用super关键字
def init(...) {
super.init(...)
...
}
}
下面展示了如何创建对象以及访问对象成员的示例。创建一个对象时,通过类名后面加new关键字的方法,就可以获得相应类的实例,而访问对象成员通过“.”符号以及成员名字即可。
//对象的创建,需要用到new关键字
//语言会调用类声明时定义的init函数来对对象进行初始化
aInstance = <类名>.new(...)
//访问对象的成员、方法(域访问)
aInstance.<成员名/方法名>
Sparrow的编译器对源程序进行预处理的主要目的是生成解析顺序树。
Sparrow提供了导入功能,使得模块(每个文件被当做一个模块)可以通过引用其它模块,来使用它们预先定义的变量、函数或声明的类。语言的导入功能对编写程序进行功能模块划分十分有帮助,另一方面也要求语言要用合理正确的顺序来对模块进行解析,避免出现导入无效、重复导入和循环导入的问题。编译器解决这些问题的关键是解析顺序树,这棵树上的每一个节点对应一个模块,树中不包含重复的节点,后序遍历节点的顺序就是解析器解析模块的顺序。
下面是生成解析顺序树的抽象算法伪代码,这是一个在递归中构造的树过程。当对某个模块进行预处理时,如果它不在解析顺序树中,则把它作为子节点放入当前的节点下(如果没有则作为根节点),接着对它导入的模块进行同样的递归处理。
pre-process_require (module):
if self not in order-tree:
put self into order-tree
for each module in required-modules:
pre-process_require(module)
本节详细参见pre_process目录中的代码。
Sparrow语言的内部实现有五种类型的Token,它们是IntToken, FloatToken, StrToken, IdToken, EOFToken,分别表示整型、浮点型、字符串型、标识型、文件终结标识。
在实现词法分析器时,我没有用递归下降逐步分析每个输入字符的方法,而是用正则表达式对每一行的每个字符串进行匹配,该正则表达式在C++中如下面代码片段所示,其中①是用来匹配每个单词前面的空白符,②至⑦用以匹配该单词的内容,它们间是互斥的。②代表匹配导入语句,③代表匹配注释,④代表匹配整型Token,⑤代表匹配浮点型Token,⑥代表匹配字符串Token,⑦代表匹配了标识Token。
std::string patternStr = \
"\\s*" ①
"("
"(require [[:alnum:]_]+(\\.[[:alnum:]_]+)* as [[:alnum:]_]+)" ②
"|(//.*)" ③
"|([0-9]+)" ④
"|([0-9]+\\.[0-9]+)" ⑤
"|(\"(\\\\\"|\\\\\\\\|\\\\n|[^\"])*\")" ⑥
"|\\$?[A-Z_a-z][A-Z_a-z0-9]*|!=|==|<=|>=|&&|\\|\\||[[:punct:]]" ⑦
")?";本节详细参见lexer.h,lexer.cc,lexer_imp.h,lexer_imp.cc。
Sparrow语言的语法分析器通过一个构造库来构造,这个库的实现用了一种名为“组合子”的编程思想,语法分析的规则是通过通过组合各种元规则来实现的。
每个规则都要实现以下接口:
class ParseRule {
public:
virtual void parse(Lexer &lexer, std::vector<ASTreePtr> &ast) = 0;
virtual bool match(Lexer &lexer) = 0;
...
};
而Parer类内部存储着一系列规则的组合接口,外部通过调用它就可以组合出需要的规则。
//Parser类声明
class Parser: public std::enable_shared_from_this<Parser> {
public:
...
//或规则
ParserPtr orPR(const std::vector<ParserPtr> &parsers);
...
private:
...
std::vector<ParseRulePtr> rulesCombination_; //规则组合集合
...
};
//Parser类部分实现代码
ParserPtr Parser::orPR(const std::vector<ParserPtr> &parsers) {
rulesCombination_.push_back(std::make_shared<OrParsePR>(parsers));
return shared_from_this();
}
如以下展示一条文法以及它的组合代码。
params ::= ( param { "," param } ) | <NULL>;
auto params = Parser::rule()->orPR({
Parser::rule(ASTKind::LIST_PARAMETER)->commomPR(param)\
->repeatPR(Parser::rule()->custom(",", true)->commomPR(param)),
Parser::rule(ASTKind::LIST_PARAMETER)\
->commomPR(Parser::rule(ASTKind::LIST_NULL_STMNT))
});
在进行语法分析时,会隐式生成语法分析树。在设计AST的中间节点,我为每种类型的中间节点设置了在没有子节点和子节点个数为1的情况下,该节点是否可以被忽略的标志(ASTList类中的ignore_字段)。通过上面这个标志,语法分析器在分析语法时可以通过剪枝直接生成AST。
本节详细参见parser_constructor.h,parser_constructor.cc,parser.h,parser.cc,ast相关的文件。
Sparrow语言运行时内部的数据对象有以下几类:
| 类型 | 介绍 |
|---|---|
| 空 | 用以表示语言中空对象含义的内部类型 |
| 整型 | 用以表示整型数字的内部类型 |
| 浮点型 | 用以表示小数的内部类型 |
| 字符串型 | 用以表示字符串的内部类型 |
| 布尔型 | 用以表示真、假的内部类型,它的值只有两种 |
| 数组 | 用以表示长度不变的数组的内部类型 |
| 函数 | 用以表示用户自定义的函数、闭包类型 |
| 原生函数 | 用以表示语言自带的,可供用户直接调用的函数的类型 |
| 类元信息 | 用以表示用户自定义的类的相关信息的类型 |
| 类实例 | 用于表示语言运行时类产生的实例的类型 |
| 环境 | 用于表示存储语言内部对象的环境的类型 |
Sparrow语言中的环境分为局部环境和非局部环境。局部环境指函数运行时构造的临时环境,非局部环境指除此以外的全部环境,如每个模块的全局数据存储环境,类实例数据存储环境等。
另一方面,环境与环境之间可以有内外层关系,当某一个变量在当前环境无法找到时,如果允许,将进一步在它的外层环境查找,直到找到或查找失败报错。由于环境还可以作为一个对象,因此环境里面放置的数据也有可能是另一个环境甚至是自己。
局部环境和非局部环境的区别如下表所示。编译器通过事先遍历函数的AST,可以知道哪些变量是局部变量(通过判断变量名有无出现在上下文的环境中),并确定函数运行时局部变量的个数。因此可以知道局部环境的大小。同时,它为变量分配一个在局部环境中的位置(下标)。程序运行时可以通过下标索引找到变量,减少名字索引的时间消耗,提高了运行速度。
非全局环境用于全局变量存储和类实例成员存储。它们的特点都是变量个数是可变的,因此无法为变量确定固定的下标,变量必须按照变量名进行索引。 因为局部环境允许外层环境为非局部环境,当对局部进行指明变量名的变量查找时,它会自动在外层环境中进行查找并返回结果。
| 对比项目 | 局部环境 | 非局部环境 |
|---|---|---|
| 大小是否可变 | 否,且大小提前预知 | 是,运行时可随时增减变量 |
| 变量索引方式 | 按下标索引或按变量名索引 | 按变量名索引 |
| 变量插入方式 | 指明下标或指明变量名 | 指明变量名 |
| 存储实现方式 | 数组(C++ vector) | 字典(C++ map) |
| 允许外层环境 | 局部环境或非局部环境 | 非局部环境 |
| 应用场景 | 函数 | 全局数据存储、类实例数据存储 |
本节详细代码见env.h和env.cc。
基于树遍历执行语言,是指通过语法分析得到的抽象语法树来执行程序。解释器只需要从抽象语法树的根节点往下遍历,计算各个节点的内容即可。
为了通过抽象语法树来运行程序,AST中的每个节点都需要具备计算自身的能力。为了达到这个目的,我在实现抽象语法树时,为节点的基类增加了一个名为eval的接口,每个子类只需要通过实现这个接口就可以达到计算自身的返回值,并将结果返回给调用者。这个接口如下所示。
class ASTree {
public:
...
//计算自身并返回结果
virtual ObjectPtr eval(EnvPtr env) = 0;
...
}
该接口的入参是一个环境。正如上文所言,环境为解释器的运行提供上下文支持,当解释器执行解释时,它可以从环境中找出所需要的变量,或者把执行结果写入到其中。为AST中的每个节点传入环境,让它们可以在计算自身时随时从外部获得所需的信息,也可以随时把结果作用于环境,达到源程序中数据变更的效果。
本节详细参见各ast文件中,各叶子、中间节点的eval实现。
基于树遍历的解释器最大的局限性是它的执行开销较大,如果语言处理器能够事先计算遍历的顺序,把抽象语法树线性化,那么解释器运行的开销就有可能可以降低。线性化是指把每个节点的执行逻辑编译为连续的字节码,解释器执行这些字节码就可以达到和遍历抽象语树一致的效果。
Sparrow语言使用的是栈式解释器,它模拟堆栈计算机,把所有操作的结果(即临时变量)放在操作数栈中。 它模拟了下列的计算机组件:
- 代码存储器:存放源程序字节码的数组
- 指令计数器寄存器:储存待执行的下一条指令的地址
- 全局存储器:程序运行时的外部环境,里面包含了各种全局变量
- CPU:解释执行字节码的,根据字节码进行不同的操作,也称为指令调度器
- 常量池:存储源代码中的字符串、浮点数和整型数字面量
- 函数调用栈:存放栈帧的结构,每个栈帧根据需要可能含有函数调用的返回地址、参数以及局部变量
- 操作数栈:存储临时变量的地方,任何一个指令的操作数要么存放在操作数栈中,要么存放在字节码中
- 栈寄存器:专用寄存器,指向操作数栈的栈顶
为了方便,统一用4字节无符号整型作为字节码的最小单位,而所有的操作指令大小均为4字节,它们的含义如下所示。
| 指令 | 含义及操作 |
|---|---|
| ADD | 弹出两个操作数,进行加法运算并把结果压入栈中 |
| SUB | 弹出两个操作数,进行减法运算并把结果压入栈中 |
| MUL | 弹出两个操作数,进行乘法运算并把结果压入栈中 |
| DIV | 弹出两个操作数,进行除法运算并把结果压入栈中 |
| MOD | 弹出两个操作数,进行相模运算并把结果压入栈中 |
| EQ | 弹出两个操作数进行相等比较,把真或假的结果压入栈中 |
| LT | 弹出两个操作数进行小于号比较,把真或假的结果压入栈中 |
| BT | 弹出两个操作数进行大于号比较,把真或假的结果压入栈中 |
| LE | 弹出两个操作数进行小于或等于号比较,把真或假的结果压入栈中 |
| BE | 弹出两个操作数进行大于或等于号比较,把真或假的结果压入栈中 |
| NEQ | 弹出两个操作数进行不相等比较,把真或假的结果压入栈中 |
| SCONST | 从常量池获取字符串型常量并压入栈中 |
| ICONST | 从常量池获取整型常量并压入栈中 |
| FCONST | 从常量池获取浮点型常量并压入栈中 |
| CALL | 调用函数,将新的栈帧压入调用栈中,将栈中的入参传递给栈帧 |
| RET | 函数返回,返回值(如果有)将压入栈中,将栈帧弹出调用栈 |
| BR | 无条件跳转 |
| BRT | 弹出栈顶元素,如果为真则跳转 |
| BRF | 弹出栈顶元素,如果为假则跳转 |
| AND | 弹出栈顶两个元素,进行与逻辑运算,并把结果压入栈中 |
| OR | 弹出栈顶两个元素,进行或逻辑运算,并把结果压入栈中 |
| GLOAD | 从全局存储器中获取变量并压入栈中 |
| GSTORE | 弹出栈顶元素,存储到全局存储器中 |
| CLOAD | 获取闭包变量并压入栈中 |
| CSTORE | 弹出栈顶元素,存储到闭包变量中 |
| LOAD | 从局部变量存储器中获取变量并压入栈中 |
| STORE | 弹出栈顶元素,存储到局部变量存储器中 |
| ARRAY_GENERATE | 生成数组 |
| ARRAY_ACCCESS | 数组访问,将访问目标压入栈中 |
| ARRAY_ASSIGN | 数组赋值,弹出栈顶元素并赋值于相应的数组元素 |
| LAMB | 创建闭包 |
| DOT_ACCESS | 域访问 |
| DOT_ASSIGN | 域赋值 |
| RAW_STRING | 元字符指令,虚拟机从栈帧中获取相应的字符串,该串在语言中不是字符串,但其在被虚拟机处理时需要当作字符串, |
| NEW_INSTANCE | 创建新的对象 |
| NEG | 弹出栈顶元素,取其负值并压入栈 |
| HALT | 终止程序 |
Sparrow语言的编译代码以函数为单元进行管理,即解释器执行的字节码分散在各个函数之中的,并不是都集中在一个字节码数组中。当发生函数调用时,解释器获取调用函数的字节码,存储在栈帧中。另一方面,栈帧也保存着运行时信息(如计数器,局部变量等),因此每个栈帧都提供了一个完整的函数执行环境以及状态。
基于上述的管理方式,只有作为函数的AST才会被编译器生成相应的字节码,或包含函数的AST(如类定义)。其它处于全局环境的赋值、调用操作,语言处理器会选择基于树遍历的方式来执行代码,而不生成字节码。字节码生成的过程和递归遍历执行AST的逻辑相似,每个节点在进行自身字节码生成时,会先对子树进行编译并把字节码放入函数的代码存储器。
CPU分析指令的逻辑比较简单,只需要把对取出的指令进行判断。每个指令对应着不同的操作,CPU只需要根据其含义模拟操作。其算法伪代码下所示。此处每个指令的执行逻辑,类似于在前文所提及的AST遍历执行中,每个节点计算自身的逻辑。可以理解为把在节点中计算的逻辑,转化到了CPU的执行逻辑中。
CPU-simulate():
switch(next_instruction):
case A:
do A
case B:
do B
...
get next_instruction
本节详细参见vm目录中的代码。
所有的例子源代码都位于demo文件夹中。
def main() {
printLine("Hello World")
}

def fib(n) {
if n < 2 {
return n
} else {
return fib(n - 1) + fib(n - 2)
}
}
def main() {
print("输入任意整型数:")
num = readInt()
printLine("")
print("fib(")
print(num)
print(") = ")
}
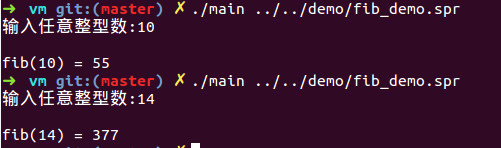
//快速排序,已省略(详见项目源代码)
def qsort(arr, left, right) {
if left >= right {
return nil
}
key = arr[left]
i = left + 1
j = right
while i < j {
while and(arr[i] <= key, i < j) {
i = i + 1
}
while and(arr[j] > key, i < j) {
j = j - 1
}
tmp = arr[i]
arr[i] = arr[j]
arr[j] = tmp
}
if arr[i] < key {
arr[left] = arr[i]
arr[i] = key
qsort(arr, left, i - 1)
qsort(arr, i + 1, right)
} else {
arr[left] = arr[i - 1]
arr[i - 1] = key
qsort(arr, left, i - 2)
qsort(arr, i, right)
}
}
//打印数列函数,已省略(详见项目源代码)
def printArray(arr, size) {...}
//main函数,主要是一些测试用例和打印,已省略(详见项目源代码)
def main() {...}
该例子通过模拟对文字进行HTML格式处理来展示Sparrow语言闭包功能。bold函数和italic函数模拟对文字进行处理,前者是加粗,后者是斜体。下面中通过组合两个函数,构造出加粗、斜体的混合格式处理函数。
//入参是一个函数对象,组合格式函数,可以为空
//出参是一个函数对象,该对象先执行内部组合格式函数进行格式化处理,然后再添加表示加粗的HTML元素
def bold(wrapped) {
tmp_lamb = nil
if wrapped == nil {
tmp_lamb = lamb (word) {
return "<b>" + word + "</b>"
}
} else {
tmp_lamb = lamb (word) {
return "<b>" + wrapped(word) + "</b>"
}
}
return tmp_lamb
}
//入参是一个函数对象,组合格式函数,可以为空
//出参是一个函数对象,该对象先执行内部组合格式函数进行格式化处理,然后再添加表示字体变斜的HTML元素
def italic(wrapped) {
tmp_lamb = nil
if wrapped == nil {
tmp_lamb = lamb (word) {
return "<i>" + word + "</i>"
}
} else {
tmp_lamb = lamb (word) {
return "<i>" + wrapped(word) + "</i>"
}
}
return tmp_lamb
}
def main() {
bold_and_italic = bold(italic(nil))
print("Please input a word: ")
word = readStr()
printLine(bold_and_italic(word))
}

//父类
class Person {
name_ = nil
def init(name) {
name_ = name
}
def get_name() {
return name_
}
def set_name(new_name) {
name_ = new_name
}
def info() {
print("name: ")
printLine(name_)
}
}
//子类,继承Person类
class Student extends Person {
stu_id_ = nil
def init(name, stu_id) {
super.init(name)
stu_id_ = stu_id
}
def get_stu_id() {
return stu_id_
}
def set_stu_id(new_id) {
stu_id_ = new_id
}
def info() {
//调用父类同名方法要用super关键字
super.info()
print("student id: ")
printLine(stu_id_)
}
}
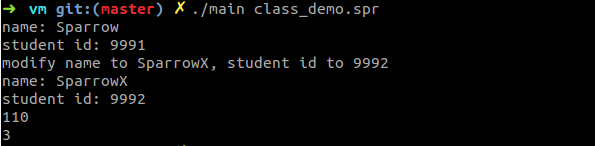
def main() {
//初始化一个Student实例并打印它的信息
zhu = Student.new("Sparrow", 9991)
zhu.info()
//修改刚才初始化的对象的值,并打印它的信息
printLine("modify name to SparrowX, student id to 9992")
zhu.set_name("SparrowX")
zhu.set_stu_id(9992)
zhu.info()
//当为对象一个不存在的成员赋值时,会为对象创建新的成员
//甚至是函数
zhu.id_ = 110
printLine(zhu.id_)
zhu.add_one = lamb(num) {
printLine(num + 1)
}
zhu.add_one(2)
}
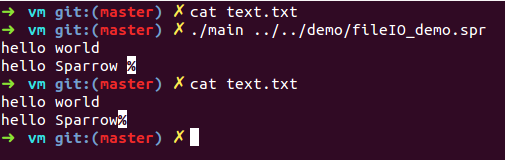
我使用Sparrow语言简单地实现了一个只读文件类ROFile和只写文件类WOFile。实现代码中用到了Sparrow语言内置的函数,这些函数以双下划线开头,它们对外是透明的。ROFile和WOFile所在的file.spr文件位于lib目录中,当语言的使用者需要用到文件IO功能时,只需要通过导入相应的库即可。
该例首先以截断的方式打开名为text.txt的文件文件并向其中写入内容,然后读取这个文件的内容并输出到屏幕上。
//库源码位于demo/lib/file.spr文件中
//文件只读类
class ROFile {...}
//打开的方式:截断和追加
OPEN_WITH_TRUNC = 0
OPEN_WITH_APPEND = 1
//文件只写类
class WOFile {...}
//导入语言的库
require lib.file as file
//另起别名,下文可以用ROFile 替代file.ROFile
use ROFile = file.ROFile
use WOFile = file.WOFile
def main() {
outputFile = WOFile.new("text.txt", file.OPEN_WITH_TRUNC)
outputFile.write("hello world \nhello Sparrow")
outputFile.close()
inFile = ROFile.new("text.txt")
line = inFile.readLine()
printLine(line)
word = inFile.readWord()
while word != nil {
print(word + " ")
word = inFile.readWord()
}
inFile.close()
}